Sep 29, 2022
Releases
Backend.AI Announcement: Graphcore IPU Integration

Lablup
Lablup
Sep 29, 2022
Releases
Backend.AI Announcement: Graphcore IPU Integration
Lablup
Lablup
Backend.AI is now starting to support Graphcore's IPU. Let's explore a brief introduction to IPU and how Backend.AI supports the use of IPU.
Graphcore IPU
Currently, deep learning accelerators predominantly utilize the computational units of Graphics Processing Units (GPUs) through programming. However, as performance and computational demands increase, power consumption also rises accordingly, leading to various attempts to improve the power-to-performance ratio. A representative approach includes AI-specific processors. These processors aim to improve power-to-performance ratios by incorporating computation units more specialized for neural network operations and handling deliberately lower precision integer and floating-point types such as int8/fp8/fp16 directly at the processor level. The IPU (Intelligence Processing Unit) is one such processor, an AI and ML specialized acceleration computing device being developed by Graphcore.
Structure
The IPU is primarily composed of "tiles," IPU-Exchange™️ interface, IPU-Link™️ interface, and PCIe interface.
- Tiles: These are the minimum computational units of the IPU, consisting of an IPU-Core™️ and SRAM. A single IPU contains multiple tiles1. Based on the Bow-IPU, the total SRAM capacity within an IPU is 900MB. While this capacity is smaller compared to other GPUs with similar computational performance, the IPU's memory is faster than the L1 Cache and shared memory of other GPUs2 and shows latency similar to a CPU's3 L2 cache.
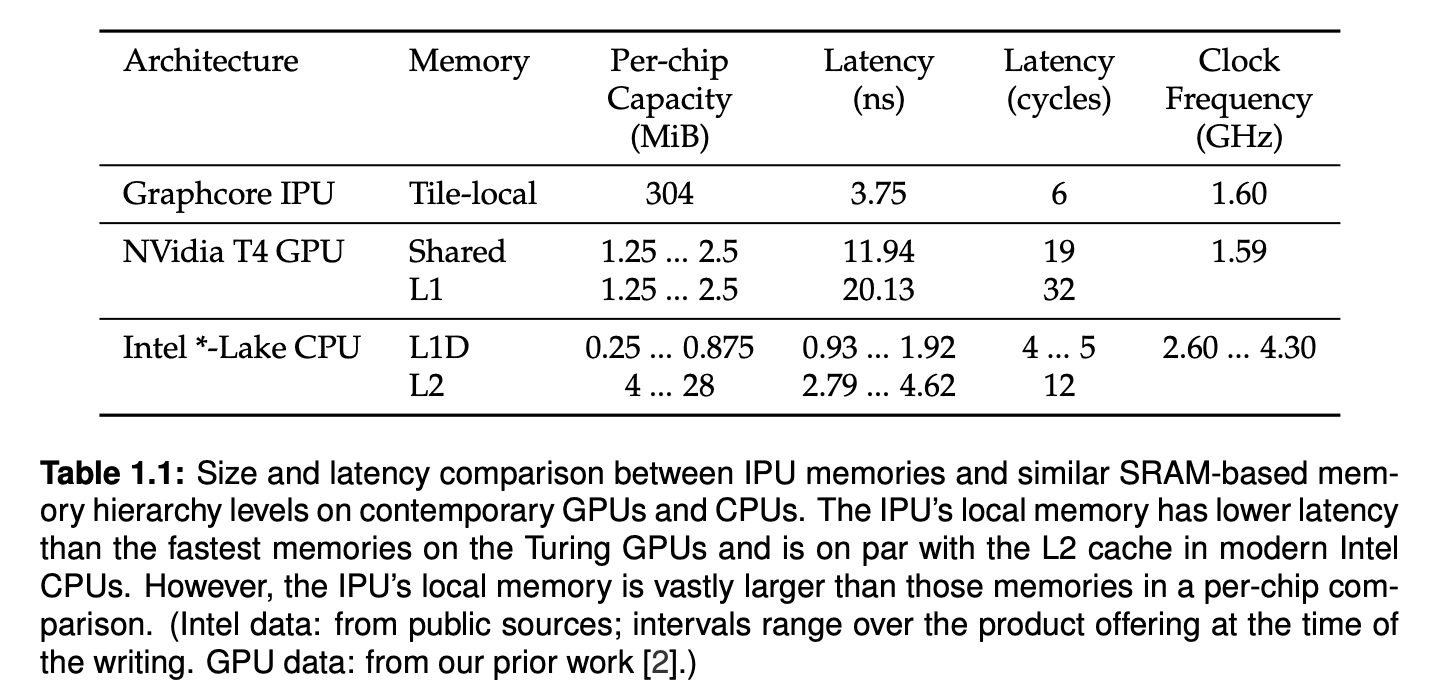
-
IPU-Exchange™️: This is the channel for transferring data between processors when using multiple IPUs simultaneously. It supports non-blocking connections with a maximum bandwidth of 11TB/s.
-
IPU-Link™️: This channel transfers data between IPU-Cores™️ within a single IPU. The Bow IPU has 10 IPU-Links™️, supporting a chip-to-chip bandwidth of 320GB/s.
-
PCI-e: This is the interface for connection with the host computer. It supports PCI-e Gen4 (x16) mode and allows bidirectional data transfer of up to 64GB/s.
(Reference page: https://www.graphcore.ai/bow-processors) (Reference article: Dissecting the Graphcore IPU Architecture via Microbenchmarking - Citadel Security, 2019 (arXiv:1912.03413v1 [cs.DC]))
Bow IPU
Latest generation of IPUs that incorporates Wafer on Wafer (WoW) technology. It features a total of 1,472 computational cores and 900MB of memory, capable of computing at speeds of up to 350 teraFLOPS.
Bow 2000
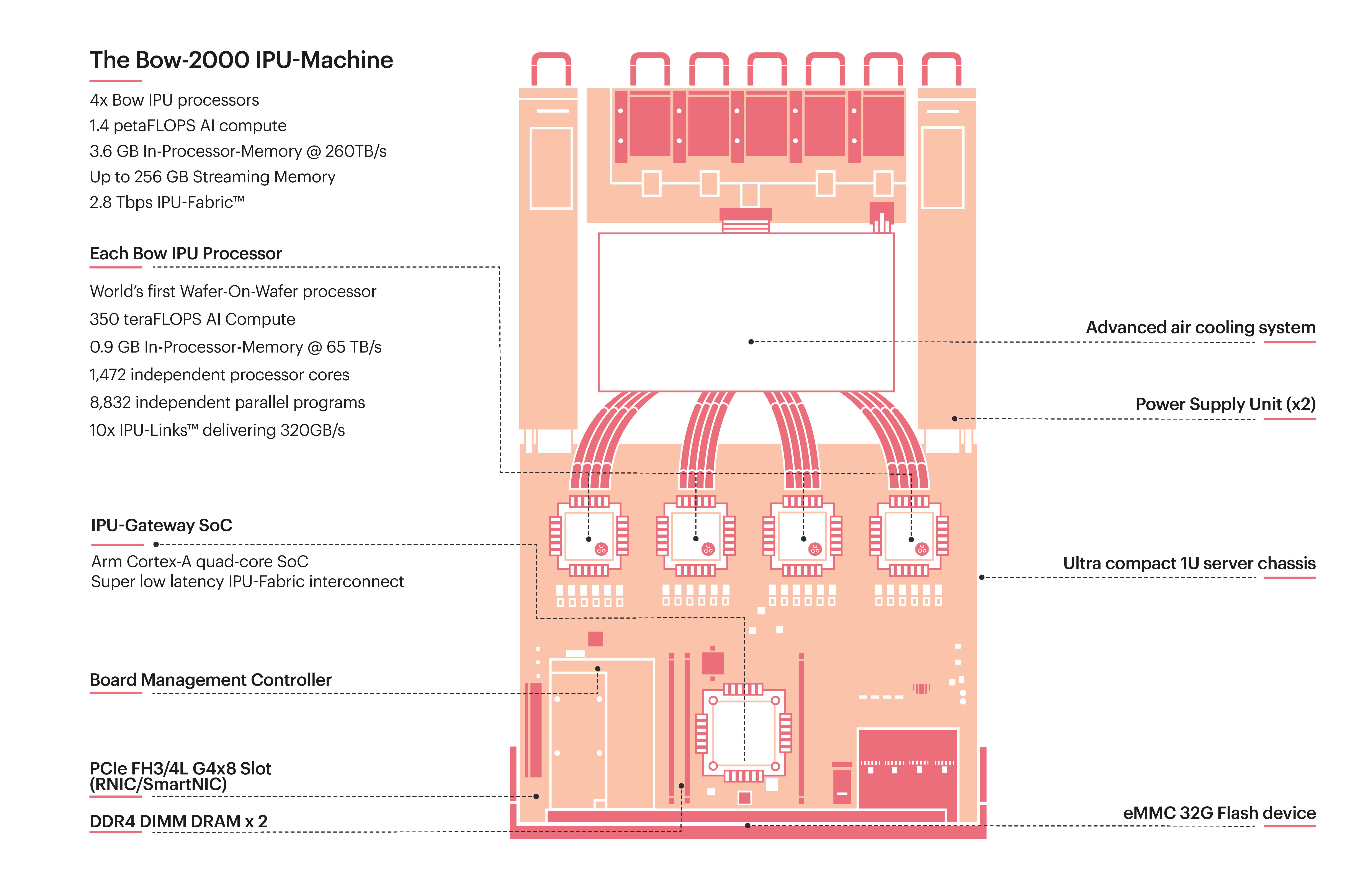 1U blade equipped with 4 Bow IPU chips. It includes an Infiniband interface for data transfer between multiple Bow IPUs.
1U blade equipped with 4 Bow IPU chips. It includes an Infiniband interface for data transfer between multiple Bow IPUs.
IPU Pod
An IPU cluster consisting of multiple Bow 2000 units and a single host system.
- Host System server performs computations through the IPUs within the Pod. It is connected to the Bow 2000 via RoCE (RDMA over Converged Ethernet), enabling low-latency, fast data transfer from memory during computation.
- There is an Infiniband interface that connects Bow 2000 units to each other. This ensures that data transfer between IPUs is not affected by data transfer between the host and Bow 2000.
- V-IPU
- Used when bundling IPU chips together and partitioning them for use.
Comparison with Traditional GPU
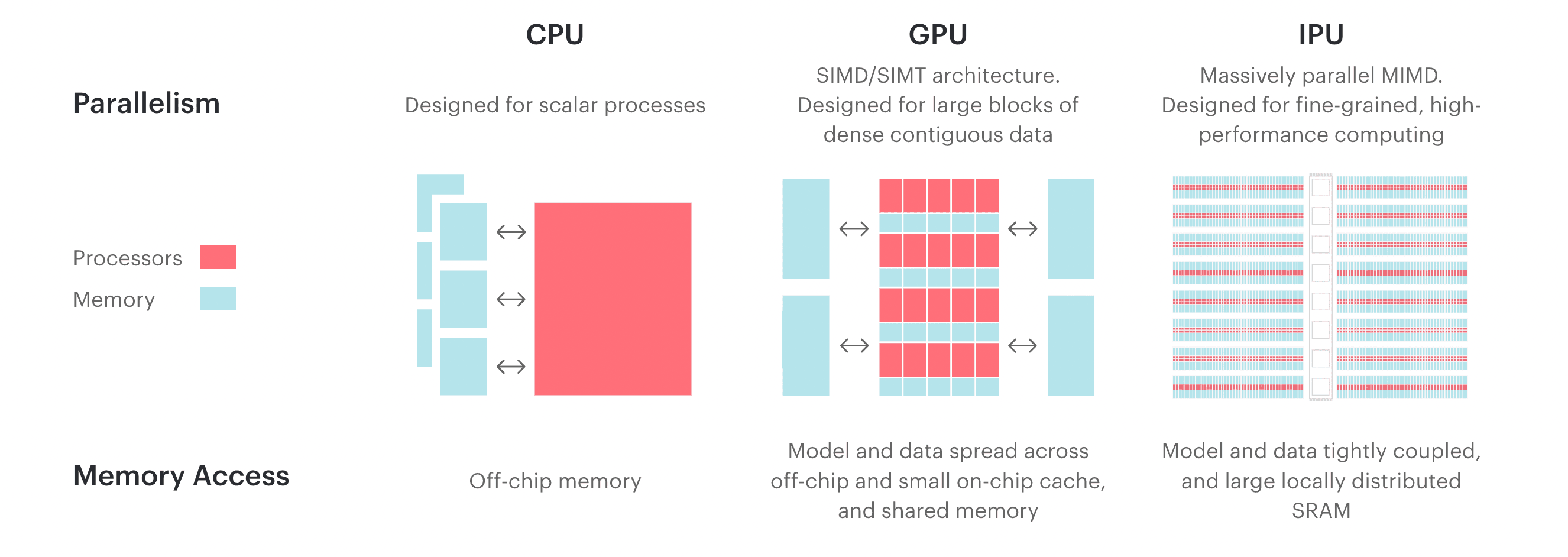
Advantages
- Through a larger number of more granular computational units¹ compared to GPUs, it can process more operations simultaneously.
- The high bandwidth and low latency of IPU-Exchange™️ enables fast processing of multi-node computations utilizing multiple Bow IPUs.
Disadvantages
- With the default settings, it is difficult to use in a multi-user environment through containers. Similar to NVIDIA's nvidia-docker, Graphcore also provides a CLI tool called gc-docker that allows running containers with access to IPUs. However, in this case, the use of Docker's Host Network is enforced, which can be disadvantageous from a security perspective.
Backend.AI with Graphcore IPU
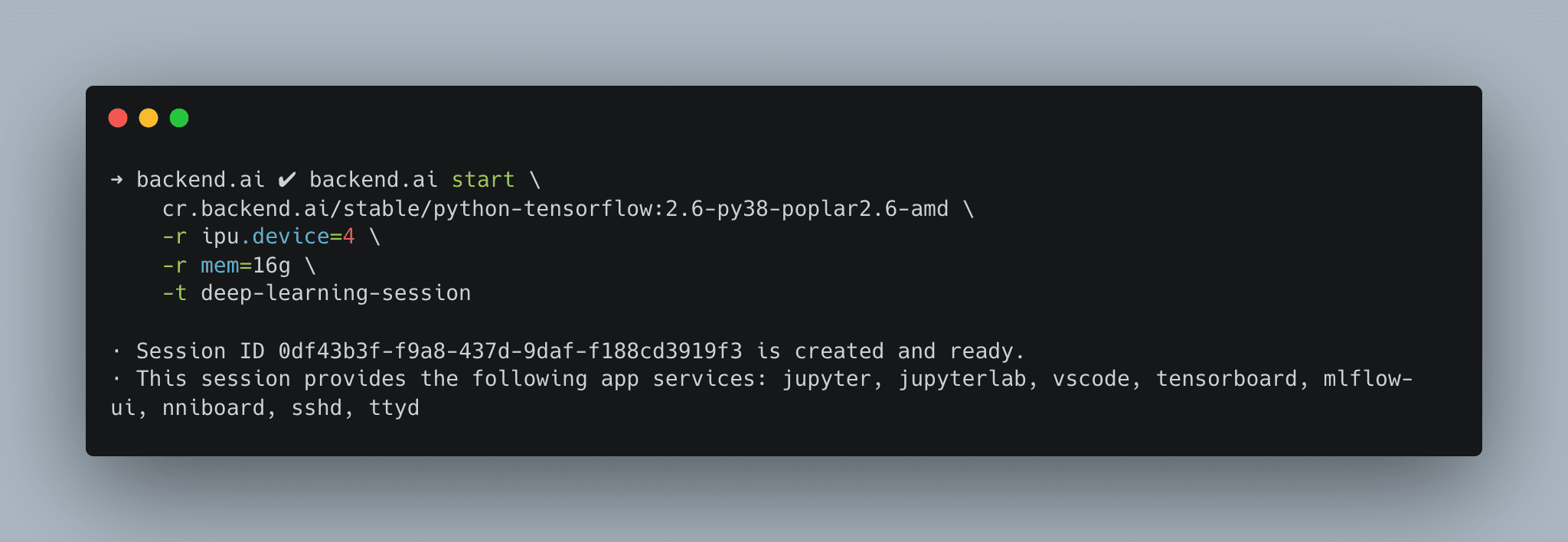
Backend.AI is being developed with the basic premise of a multi-user environment requiring high security in cloud and enterprise settings. As mentioned earlier, we were able to overcome the disadvantages of gc-docker, which was difficult to use in multi-user environments, through collaboration with Graphcore and updates to the Backend.AI Container Pilot engine. As a result, Graphcore IPUs can now be used in Backend.AI in a fully isolated manner in multi-user environments without any performance degradation.
- Fast and convenient resource allocation: With just a few clicks, isolated IPU partition allocation per container is possible.
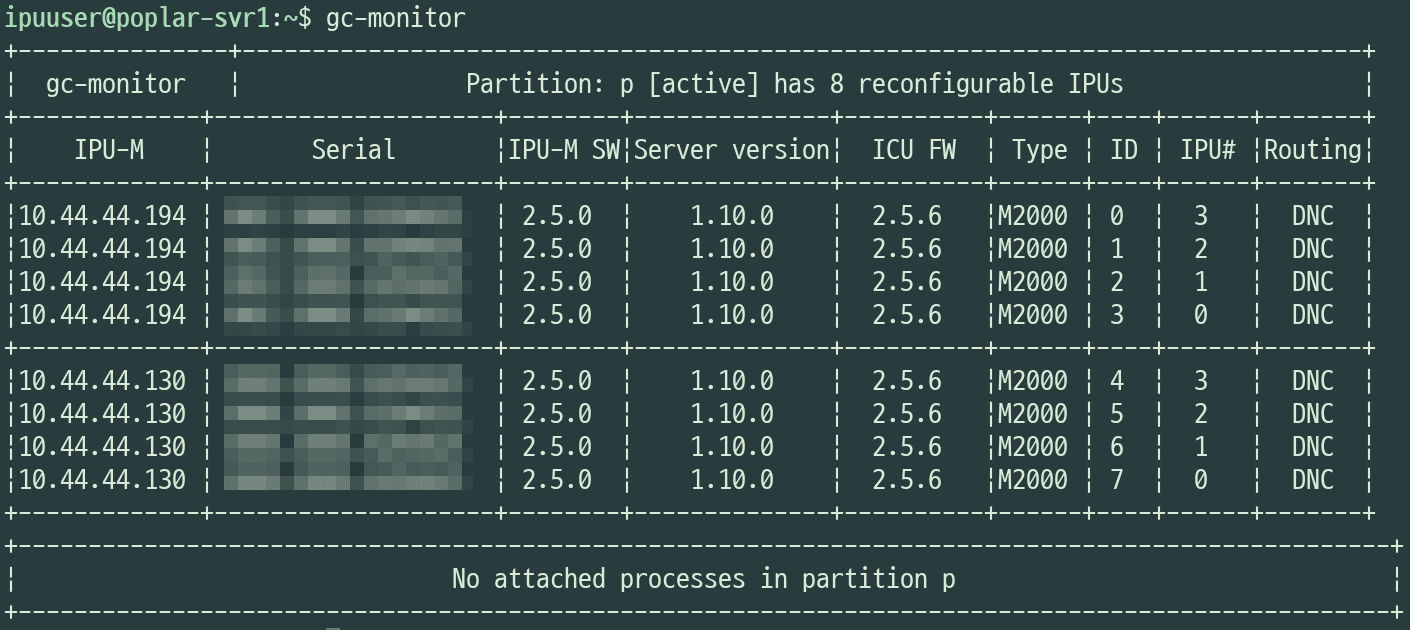
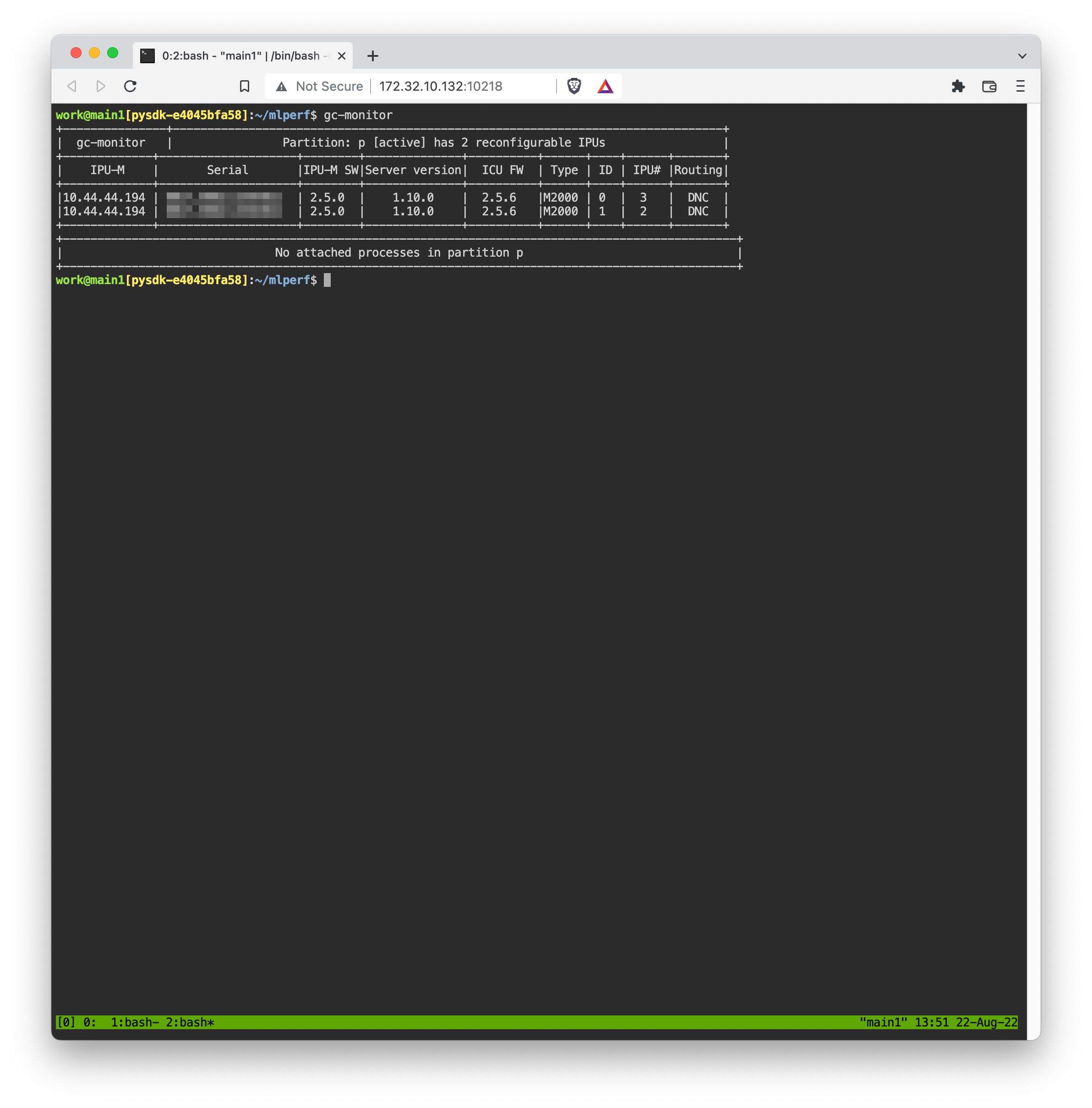
- Isolated network environment: Using Backend.AI, you can use isolated sessions without exposing containers to the Host Network.
- Ability to bundle multiple IPU Pods: By utilizing Backend.AI's cluster session feature, which bundles multiple distributed containers into a single computational session, distributed learning is possible even with multiple IPU Pods.
Conclusion
Backend.AI effectively abstracts interfaces for recognizing and allocating hardware such as storage and AI accelerators. This design greatly helps with flexible support for new hardware. The same was true for this Backend.AI support for Graphcore IPU. With this update, Graphcore IPU has become the fourth AI accelerator guaranteed to work with Backend.AI, following CUDA GPU, ROCm GPU, and Google TPU. Going forward, Backend.AI will continue to strive to add value to hardware by taking the lead whenever new exciting and powerful hardware is released. Please look forward to what's coming!