
2025년 4월 21일부로 래블업은 설립 만 10년을 맞이하였습니다. 천릿길도 한걸음부터라고 했는데 오다보니 앞으로도 갈길이 구만리나 남아있는 것 같지만, 이번 기회에 그동안 래블업과 함께 한 10년을 돌아보며 그동안의 래블업과 AI 업계의 기술 발전 과정을 돌아보고자 합니다.
리눅스 컨테이너

아마 저희 회사 소개를 들은 많은 분들은 '랩을 업'에서 회사 이름이 유래하였다는 이야기를 들어보셨을 겁니다. 2015년 창업 당시 현직 랩돌이거나 전직 랩돌이인 사람들이 모였다보니 아무래도 가장 와닿는 것이 뭔가 연구실에서 삽질하는 걸 줄여보자는 것이었더랬습니다. 물리학과에서 1000대 규모의 CPU 기반 클러스터 환경을 직접 관리하면서 끝없는 C 컴파일러와 라이브러리의 호환성 문제와 끝없이 죽어나가는 컴퓨터들(확률적으로 컴퓨터가 3년에 한 번 정도 고장난다고 생각하면, 1천대쯤 모이면 대충 하루이틀에 한대씩 문제가 생긴다고 볼 수 있습니다) 때문에 학을 뗀 신정규 대표님과, if 문의 브랜치 예측 하나가 맞느냐 틀리느냐로 성능이 몇%까지 차이날 정도의 극한의 성능 최적화가 필요한 GPU 가속 기반 패킷 처리 프레임워크를 만들던 제가 만나 어떻게 하면 이 삽질을 좀 남들은 덜 하게 만들 수 있을까 고민하기 시작했죠.
현재 래블업의 모토는 "Make AI Accessible", 그리고 이것을 조금 더 구체화하여 "Make AI Scalable"을 이야기하고 있습니다. 하지만 2015년 당시의 모토는 재현 가능한 연산 환경(reproducible computing environment)을 클라우드 기반으로 제공하여 과학 연구의 상호 검증과 재현의 문턱을 낮추자는 것이었습니다.
HPC나 슈퍼컴퓨팅 분야에서는 기존의 하드웨어 전체를 완전히 가상화하여 별개의 독립된 시스템으로 만들어주는 가상머신 기술은 성능 오버헤드 때문에 널리 활용되지 않는데요, 이 때문에 각 대학이나 연구기관의 슈퍼컴퓨팅 센터에서는 여러 사용자가 개별적으로 자신의 워크로드를 실행하기 위해 요청하는 특화된 라이브러리나 특정 버전의 C/Fortran 컴파일러 같은 것을 사용자 간 충돌 없이 지원하기 위해 module이라는 명령어를 통해 PATH, LD_LIBRARY_PATH 환경변수를 관리해주는 방식을 사용해왔습니다. 여전히 이 방식은 Slurm과 같이 bare-metal 환경에서 직접 다중 사용자 워크로드를 돌릴 때 쓰이고 있습니다.
당시에 주목했던 것은 리눅스 컨테이너 기술이었습니다. 2013년 Solomon Hykes가 PyCon US에서 라이트닝 토크로 dotCloud를 뒷받침하는 기술로 Docker를 처음 소개한 후 Docker는 복잡한 의존성이 있는 소프트웨어 배포를 편리하게 할 수 있는 기술로 점점 클라우드 업계에서 인기를 끌고 있었습니다. 리눅스 컨테이너의 근간을 이루는 커널 네임스페이스(cgroups) 기술은 이전부터 존재했지만, 이것을 계층적 파일시스템과 결합하여 재사용 가능한 라이브러리 계층을 바탕으로 재현 가능한 환경이 제공되는 앱 배포 환경으로 포장했다는 점에서 실제 개발자들에게 재현 가능한 개발·베포 환경을 제공해주었기 때문입니다.
 제가 봤을 때, 가상화에 따른 소프트웨어 배포의 편리함과 재현 가능한 환경의 구축을 달성하면서도 bare-metal에 준하는 하드웨어 연산 성능을 활용할 수 있도록 이 간극을 좁힐 수 있는 기술이 바로 리눅스 컨테이너 기술이었고, 따라서 래블업의 초기 기술적 목표는 컨테이너 기술을 바탕으로 고성능 연산 환경을 제공하자는 것이 되었습니다. 이런 주제로 처음 세상에 래블업의 존재를 알린 것이 바로 PyCon Korea 2015년 발표입니다.
제가 봤을 때, 가상화에 따른 소프트웨어 배포의 편리함과 재현 가능한 환경의 구축을 달성하면서도 bare-metal에 준하는 하드웨어 연산 성능을 활용할 수 있도록 이 간극을 좁힐 수 있는 기술이 바로 리눅스 컨테이너 기술이었고, 따라서 래블업의 초기 기술적 목표는 컨테이너 기술을 바탕으로 고성능 연산 환경을 제공하자는 것이 되었습니다. 이런 주제로 처음 세상에 래블업의 존재를 알린 것이 바로 PyCon Korea 2015년 발표입니다.
실제로 컨테이너 기반으로 고성능 연산 플랫폼을 개발하면서, (어느 정도 예상은 했지만) 컨테이너가 생각보다 굉장히 많은 호스트 시스템의 정보를 그대로 컨테이너 내부 애플리케이션에게 노출한다는 점을 알게 되었습니다. 경우에 따라서는 이것 때문에 cgroup affinity mask 상으로는 CPU 코어 수를 8개로 제한했지만 호스트 CPU 전체 코어 개수만큼 스레드를 생성하는 BLAS 및 OpenMP 라이브러리 때문에 심각한 성능 저하가 발생하기도 했습니다. htop이나 ps 같은 명령어를 실행하면 CPU나 메모리 용량 정보가 호스트의 것이 그대로 노출되기도 하고요. 또한, 사용자 코드가 임의로 컨테이너 내부의 워크로드 관리 프로세스를 죽이거나 하는 일을 방지할 필요도 있었습니다. 이런 문제를 해결하기 위해 seccomp와 ptrace 기반으로 시스템콜을 제어하고 심볼 후킹 방식으로 libc의 일부 API를 제어하는 자체 샌드박스 계층을 만들었는데, 다 만들어서 릴리즈하자마자 Docker의 기본 샌드박스 메커니즘이 seccomp로 바뀌었던 기억이 있습니다. 사실 그 시점에 다들 비슷한 고민을 했던 게 아닌가 싶더라구요. 현재는 이런 문제들을 해결해주는 것으로 lxcfs와 같이 아예 /proc 파일시스템을 오버라이드하는 식으로 좀더 고도화된 솔루션들이 존재합니다.
쥐라기 공원
Everything looks different on the other side.
— Ian Malcomm, from Michael Crichton's 'The Jurassic Park'
지금도 정규님의 이메일 꼬리말로 사용되고 있는 문구입니다. 쥐라기 공원은 영화사에서 3D 컴퓨터 그래픽과 애니메트로닉스의 수준을 한 단계 끌어올린 작품으로 대중에게 각인되었지만, 그 원작 소설은 정규님에게는 복잡계 이론을 바탕으로 줄거리를 풀어나가서 더 인상이 깊었던 작품이기도 합니다. 작중에서는 이안 말콤 박사가 복잡계를 전공한 UT Austin 소속의 천재 수학 교수로 등장합니다.
아마 여러분들은 NVIDIA의 GPU 모델명은 전자공학이나 컴퓨팅 분야의 기틀을 닦은 유명한 과학자들의 이름을 따서 짓고, AMD의 Epyc CPU 모델명은 이탈리아의 도시 이름들을, Apple의 운영체제 이름은 고양이과 동물을 한동안 사용하다가 요즘은 캘리포니아의 유명한 도시나 지명을 따온다는 것을 알고 계실 겁니다. 사실 개발자들에게 제일 어려운 일 중에 하나가 이름짓는 것인데요, 서버 이름을 지을 때 별이나 별자리 이름을 사용한다거나 이런 것도 흔합니다.
 당연히, 우리라고 별다를 것도 없었습니다. 정규님이 좋아하는 게 뭐다? 쥐라기 공원이다... 그래서 래블업의 서버 이름들을 공룡 이름으로 짓기 시작했습니다. "saurus" 같은 공통 접미사는 자르고 tyrano, raptor, bronto, ... 이런 식으로요. (이때 새롭게 알게 된 것은, 공룡 연구가 나름 많이 진전되어 우리가 어렸을 때는 들어보지 못한 새로운 공룡 이름들도 꽤 많다는 것이었습니다.) 그러다보니 자연스럽게 공룡을 나르는 컨테이너도 생각하게 되었고, 당시의 백엔드 프로젝트 코드네임은 쥐라기 공원 소설과 영화에서 공룡을 복제·생산하는 실험실이 있던 섬인 Isla Sorna를, 프론트엔드 프로젝트의 코드네임은 실제 관람객이 방문하는 섬이었던 Isla Nublar를 따와서 지었습니다. 이 둘을 연결해주는 long-polling 기반의 코드 실행 프로토콜 핸들러의 이름은 공룡 연구개발 회사인 Ingen이었습니다.
당연히, 우리라고 별다를 것도 없었습니다. 정규님이 좋아하는 게 뭐다? 쥐라기 공원이다... 그래서 래블업의 서버 이름들을 공룡 이름으로 짓기 시작했습니다. "saurus" 같은 공통 접미사는 자르고 tyrano, raptor, bronto, ... 이런 식으로요. (이때 새롭게 알게 된 것은, 공룡 연구가 나름 많이 진전되어 우리가 어렸을 때는 들어보지 못한 새로운 공룡 이름들도 꽤 많다는 것이었습니다.) 그러다보니 자연스럽게 공룡을 나르는 컨테이너도 생각하게 되었고, 당시의 백엔드 프로젝트 코드네임은 쥐라기 공원 소설과 영화에서 공룡을 복제·생산하는 실험실이 있던 섬인 Isla Sorna를, 프론트엔드 프로젝트의 코드네임은 실제 관람객이 방문하는 섬이었던 Isla Nublar를 따와서 지었습니다. 이 둘을 연결해주는 long-polling 기반의 코드 실행 프로토콜 핸들러의 이름은 공룡 연구개발 회사인 Ingen이었습니다.
![]() 그렇게 제가 직접 아이패드로 그렸던 Sorna 아이콘이 등장하였습니다.
그렇게 제가 직접 아이패드로 그렸던 Sorna 아이콘이 등장하였습니다.
CodeOnWeb과 알파고 쇼크
현재의 래블업은 Backend.AI 플랫폼을 엔터프라이즈 고객을 대상으로 상용화하여 다양한 기업·기관들이 AI를 보다 쉽고 저렴하게 개발하고 서비스할 수 있도록 돕고 있습니다. 하지만 처음부터 래블업의 주 사업 모델이 이러한 엔터프라이즈 솔루션 판매는 아니었습니다.
2015년 후반쯤 GUI조차 존재하지 않았던 '원격 코드 실행' API를 컨테이너 기반으로 구현하는 프로토타입을 만들었을 때, 연구자들을 위한 계산과학 플랫폼을 만든다는 스타트업의 비즈니스 목표를 이해하는 투자자는 거의 없었습니다. 사실 우리 자신도 이러한 솔루션에 대한 필요성이 커질 것이라는 예상은 했지만 이걸로 어떻게 돈을 벌어야 하는지는 감이 잘 없었습니다. 단 한 가지, 한국 시장에서는 아마 이런 솔루션을 팔아서는 먹고살기 힘들 것이므로 우리는 무조건 미국과 해외 시장을 타게팅해야 하며 언제든 회사가 flip할 수 있도록 모든 개발 이력은 영어로 쌓는다는 원칙을 정한 정도였습니다. 당시 엔젤투자자로부터 받은 조언은, 코딩 교육 시장이 핫해질 것 같으니 여기에 온라인 강의 플랫폼(LMS; Lecture Management System) 형태로 GUI를 붙여서 팔아보면 어떨까 였습니다. 그래서 바깥에 알려진 래블업의 첫 제품으로 나온 것이 CodeOnWeb이었습니다. 실제로 초등학교의 수학·과학 교과서들을 살펴보고 이 과정에 맞춰서 코딩 교육 커리큘럼을 만들어보기까지 했습니다.
그 즈음 두 가지의 중요한 사건이 발생합니다.
첫번째는 구글이 TensorFlow 프레임워크를 2015년 12월 오픈소스로 공개한 것입니다. 그 전까지는 C/C++로 직접 행렬계산을 짜거나 Fortran을 쓰거나 혹은 numpy, scikit-learn과 같은 '전통적' 머신러닝 라이브러리를 사용해서 한땀한땀 딥러닝 모델 코드를 짜야 했습니다. Caffe 정도가 그나마 발전된 프레임워크였고, Torch가 그나마 Lua 기반의 고수준 인터페이스를 제공했지만 데이터 전처리나 다른 시스템과의 연동 측면에서는 불편이 많았습니다. TensorFlow의 등장으로 (지금 돌아보면 이조차도 저수준 인터페이스라 하겠습니다만) 나름 Python으로 손쉽게(?) 딥러닝 코드를 짤 수 있는 길이 열렸습니다.
두번째는, 2016년 3월 진행된 이세돌과 알파고의 바둑 대결입니다. 결과는 알파고의 승리였습니다. 당시 대학원 연구실에서 누가 이길 것인가를 놓고 작은 베팅을 했는데, 알파고가 전승한다는 쪽에 건 사람은 저 말고 거의 없었던 것으로 기억합니다. 저는 GPU가 딥러닝과 같은 종류의 연산에 매우 잘 어울린다는 것을 알고 있었고(이때 NVIDIA 주식을 샀었어야 하는데 말이죠...), 딥러닝의 방법론 상으로 충분한 훈련을 했다면 이기지 못할 이유가 없다고 생각했습니다. 하지만 당시 일반 대중에게는 이것이 엄청난 사회적 충격으로 다가왔습니다. 특히 우리나라에서는 택시를 타면 택시기사님들조차도 알파고 이야기를 할 정도였죠.
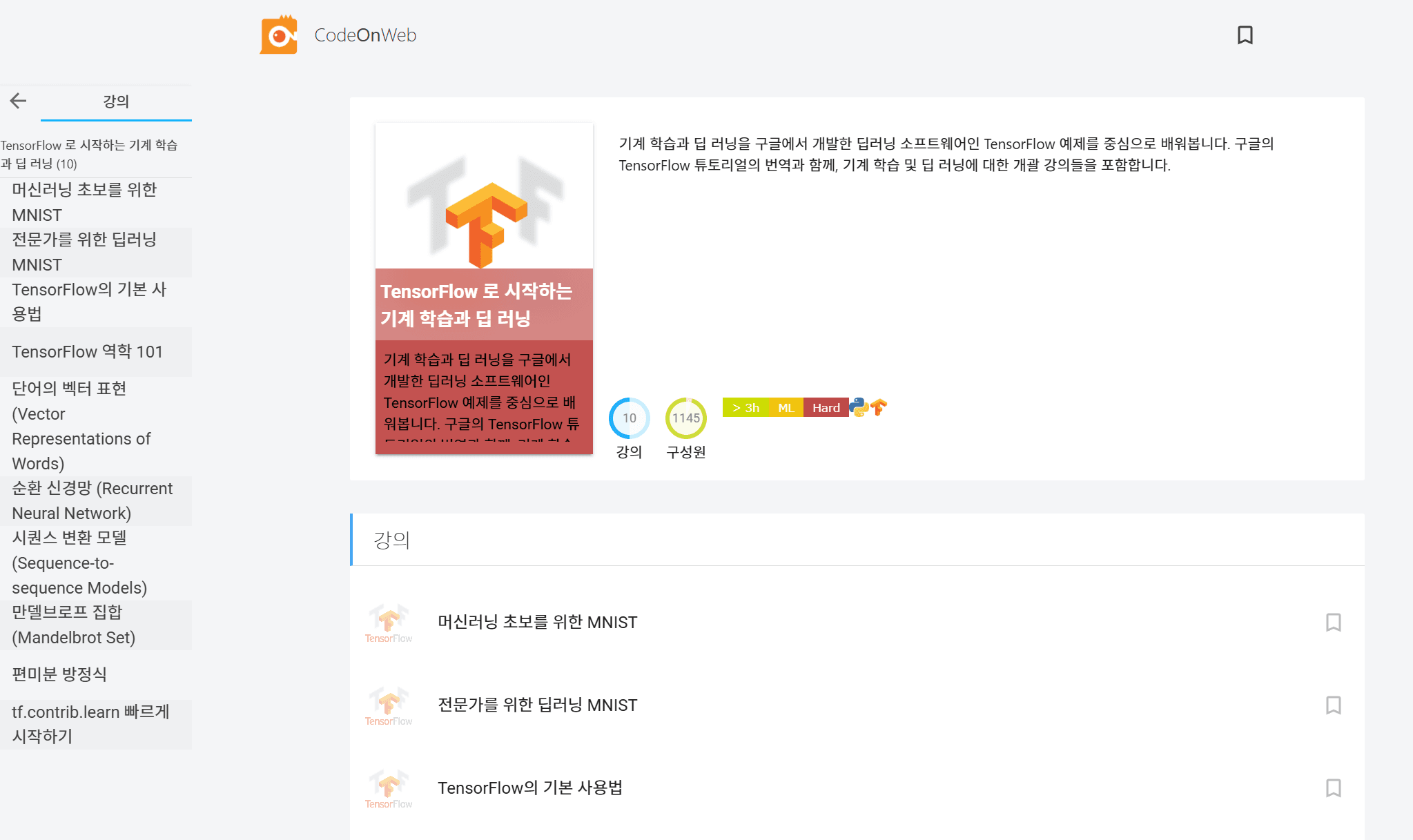 CodeOnWeb이 세상에 알려질 수 있었던 계기는 바로 이 두 사건 덕분이었습니다. 당시 정규님은 TensorFlow 매뉴얼을 번역해서 CodeOnWeb 강의로 변환하여 실제 코딩 실습을 해볼 수 있는 형태로 공개하였습니다. 그런데 이것이 TensorFlow에 대한 국내 개발자 커뮤니티의 관심 속에 나름 대박을 쳤고, 여기에 알파고 쇼크까지 가세하면서 갑자기 큰 관심을 받았습니다. 나중에 알게 된 사실인데, TensorFlow 관련 구글 검색 유입량이 당시 우리나라가 전 세계에서 미국과 중국을 제외하고 가장 많았습니다. 이 즈음 AWS의 p2 인스턴스를 이용해서 (돈을 아끼기 위해) GPU의 1/3씩만 사용하도록 TensorFlow를 직접 패치하여 GPU 워크로드를 CodeOnWeb에서 원클릭으로 직접 돌려볼 수 있게 한 것 또한 래블업이 "AI" 관련 회사로 인식될 수 있는 큰 계기가 되었습니다. 이를 바탕으로 첫 Pre-series A 투자도 유치할 수 있었습니다.
CodeOnWeb이 세상에 알려질 수 있었던 계기는 바로 이 두 사건 덕분이었습니다. 당시 정규님은 TensorFlow 매뉴얼을 번역해서 CodeOnWeb 강의로 변환하여 실제 코딩 실습을 해볼 수 있는 형태로 공개하였습니다. 그런데 이것이 TensorFlow에 대한 국내 개발자 커뮤니티의 관심 속에 나름 대박을 쳤고, 여기에 알파고 쇼크까지 가세하면서 갑자기 큰 관심을 받았습니다. 나중에 알게 된 사실인데, TensorFlow 관련 구글 검색 유입량이 당시 우리나라가 전 세계에서 미국과 중국을 제외하고 가장 많았습니다. 이 즈음 AWS의 p2 인스턴스를 이용해서 (돈을 아끼기 위해) GPU의 1/3씩만 사용하도록 TensorFlow를 직접 패치하여 GPU 워크로드를 CodeOnWeb에서 원클릭으로 직접 돌려볼 수 있게 한 것 또한 래블업이 "AI" 관련 회사로 인식될 수 있는 큰 계기가 되었습니다. 이를 바탕으로 첫 Pre-series A 투자도 유치할 수 있었습니다.
결국 2017년 이후에는 CodeOnWeb의 LMS 기능을 더 개발하기보다는, Sorna 프로젝트 자체를 고도화하여 독립적인 GPU 워크로드 관리 시스템으로 발전시키기로 합니다. 이때 리브랜딩을 진행한 결과가 현재의 Backend.AI 플랫폼입니다. 사실 여기에도 우여곡절이 많은데, 래블업이 구글 스타트업 캠퍼스에 입주해있을 당시 구글의 지원으로 마케팅·브랜드 전문 구글러들을 한국에 초청하여 컨설팅을 받은 결과 Sorna라는 이름이 구글에 검색하면 영 좋지 못한 단어의 약자로 쓰인다는 것을 발견하여 새로운 이름을 찾다가 마침 비어있는 도메인(...)을 발견한 것이 바로 Backend.AI입니다.
GPU 가상화
2016년에서 2017년으로 넘어가면서, CodeOnWeb은 대학 강의라기보다는 GPU를 활용한 딥러닝 실습 세션에서 주로 활용되기 시작했습니다. 지금 보면 귀여운(?) 수준의 fashion-MNIST 같은 비교적 작은 크기의 딥러닝 예제들이 많이 사용되었죠. 이 시기 TensorFlow는 급격한 발전을 거듭하며 거의 한달 반에 한번씩 새 버전이 나왔고, 세 번의 릴리즈 후에는 그 이전 버전과의 호환성을 더 이상 보장하지 않고 있었습니다. NVIDIA 또한 처음 텐서코어를 처음 도입한 Volta 아키텍처를 공개하며 본격적으로 딥러닝 워크로드로 무게추를 옮기기 시작했고, 구글도 TPU v2를 공개하여 점차 딥러닝을 누가누가 잘 돌려주나 경쟁하기 시작합니다.
이런 흐름 속에서 TensorFlow를 매 릴리즈마다 직접 패치하여 GPU 사용량을 임의로 제한하는 방식은 더 이상 유지보수가 힘들어졌습니다. 그러다가 2018년 IITP의 GPU 클라우드 핵심 기술 개발 과제를 수행하던 중, 이걸 더 아래 레이어로 내려가서 아예 컨테이너 내부에서는 조작이 어렵도록 CUDA 드라이버를 감싸서 GPU 자체를 더 작게 보이게 만들면서 그 사용량도 그 크기에 맞춰 제한하는 방법을 개발하게 되었는데, 이를 통해 매번 TensorFlow를 패치해야 하는 번거로움을 없애고 이때쯤 인기를 끌기 시작한 PyTorch와 같은 새로운 프레임워크도 추가적인 노력 없이 바로 지원할 수 있게 되었습니다. 이때 주안점을 두었던 부분이 클라우드 멀티테넌트 환경에서 워크로드 간 간섭이나 충돌을 최소화하는 것, 그리고 분할된 GPU 용량 자체를 미리 고정해두지 않고 그때그때 컨테이너를 실행할 때마다 동적으로 할당할 수 있게 한 것이었습니다. 만들 당시에는 사실 잘 몰랐지만, 이것이 나중에 두고두고 래블업 GPU 가상화 기술의 가장 핵심적인 selling point가 되었습니다.
트랜스포머와 ChatGPT Moment
2017년에서 2019년을 거치며 딥러닝 발전사에서 가장 중요한 획은 그었다고 평가할 수 있는 트랜스포머(transformer) 아키텍처와 이를 응용한 소위 거대 언어 모델(LLM)들이 등장합니다. 트랜스포머 아키텍처는 자기 주의(self-attention) 메커니즘을 통해 긴 텍스트 정보를 병렬적으로 학습·처리할 수 있고, 인코더를 통해 입력 정보의 정제와 압축을, 디코더를 통해 인코더 결과와 디코더 자신이 생성한 결과를 참조하여 다음 토큰을 예측하는 방식으로 다양한 출력을 생성해내는 특징을 가집니다. 이에 따라 임베딩 벡터를 구성하기 위해 인간 언어로 된 텍스트나 이미지·음성 등의 정보를 쪼갠 '토큰'이 AI 모델 정보 처리의 기본 단위로 부상합니다.
트랜스포머 기반의 거대 언어 모델들이 처음부터 세간의 주목을 받은 것은 아니었습니다. 물론 머신러닝을 연구하는 사람들이나 기계번역과 같이 특정 전문 분야에 종사하는 사람들에게는 나름 큰 변화였지만, 아직 일반인(?)들에게는 IRC 봇으로 만들곤 했던 아무말 생성봇이나 심심이보다 조금 더 고도화된 수준에 지나지 않는, 개념적으로는 결국 다음에 올 단어를 좀 더 잘 예측해서 생성해주는 정도에 가까웠습니다.
하지만 2022년 11월, 결국 모두가 아는 ChatGPT가 공개되고 인터넷 역사 상 가장 빠르게 1억 명 사용자에 도달합니다. GPT-3 모델을 질의응답을 '친절하게' 잘 하도록 추가로 훈련시킴으로써 컴퓨터에게 궁금한 걸 물어보면 척척박사처럼 잘 대답하는 서비스가 된 것이죠. 구글이 인터넷 세상을 지배할 수 있었던 원동력은 사람들이 궁금해하는 정보를 웹에서 가장 잘 찾아주었기 때문인데, 사람들은 더 이상 검색결과를 직접 일일이 들어가서 확인해보지 않아도 ChatGPT가 학습한 내용이라면 즉시 답을 얻을 수 있다는 점이 큰 매력으로 다가왔습니다. 동시에, 모르는 걸 모른다고 말하지 못하고 자꾸 그럴 듯한 틀린 답을 내놓는 환각(hallucination) 현상도 심각한 단점으로 지적되었습니다.
 2024년은 마침내 AI 분야가 노벨상을 받은 해였습니다. 존 홉필드와 제프리 힌튼이 신경망 학습의 기본 이론들을 정립한 공로로 노벨물리학상을, 딥마인드의 데미스 하사비스, 존 점퍼와 데이비드 베이커는 AlphaFold와 같이 AI를 활용한 단백질 3차원 구조 예측을 획기적으로 개선한 공로로 노벨화학상을 받았죠. 특히 AlphaFold 2는 트랜스포머를 활용하여 서열 상으로는 서로 떨어진 위치에 있는 아미노산들이 전체 단백질 구조에서는 접힘을 통해 지역적으로 가깝게 상호작용할 수 있다는 특징을 성공적으로 모델링할 수 있었습니다. 노벨상의 가장 중요한 수여 기준 중 하나가 단순히 뛰어나기만 한 연구인 것뿐만 아니라 전 인류에 충분한 이익과 영향력을 준 것이 충분한 시간 동안 입증된 것이어야 한다는 것입니다. 물리학상은 수상자의 1980년대 연구들이 장기간 딥러닝 분야의 발전에 영향을 주었다는 점을 참작하여 준 것이지만, 화학상은 2018년 처음 AlphaFold 1을 공개한 이후 10년도 안 되는 사이에 수상자의 연구들이 해당 분야의 연구 수행 방식을 크게 바꿔놓았다는 사실을 보여주었습니다.
2024년은 마침내 AI 분야가 노벨상을 받은 해였습니다. 존 홉필드와 제프리 힌튼이 신경망 학습의 기본 이론들을 정립한 공로로 노벨물리학상을, 딥마인드의 데미스 하사비스, 존 점퍼와 데이비드 베이커는 AlphaFold와 같이 AI를 활용한 단백질 3차원 구조 예측을 획기적으로 개선한 공로로 노벨화학상을 받았죠. 특히 AlphaFold 2는 트랜스포머를 활용하여 서열 상으로는 서로 떨어진 위치에 있는 아미노산들이 전체 단백질 구조에서는 접힘을 통해 지역적으로 가깝게 상호작용할 수 있다는 특징을 성공적으로 모델링할 수 있었습니다. 노벨상의 가장 중요한 수여 기준 중 하나가 단순히 뛰어나기만 한 연구인 것뿐만 아니라 전 인류에 충분한 이익과 영향력을 준 것이 충분한 시간 동안 입증된 것이어야 한다는 것입니다. 물리학상은 수상자의 1980년대 연구들이 장기간 딥러닝 분야의 발전에 영향을 주었다는 점을 참작하여 준 것이지만, 화학상은 2018년 처음 AlphaFold 1을 공개한 이후 10년도 안 되는 사이에 수상자의 연구들이 해당 분야의 연구 수행 방식을 크게 바꿔놓았다는 사실을 보여주었습니다.
2013년 영화 'Her'가 개봉했을 당시에는 말 그대로 "SF" 영화였는데, 그 영화의 배경인 2025년이 된 지금 영화에 묘사된 AI와의 상호작용이 전혀 어색하지 않을 만큼 실제 기술이 발전했고 누구나 쉽게 써볼 수 있는 세상이 되었습니다. 백투더퓨처의 2015년 묘사에 등장했던 하늘을 나는 자동차 같은 건 아직 대중화될 만큼 기술이 성숙하지 않았지만, AI 챗봇과 에이전트 서비스는 이미 많은 사람들의 삶을 바꿔놓고 있습니다. 이제는 수억 명 단위의 사용자가 트랜스포머 기반의 AI 서비스를 직간접적으로 이용하는 세상이 도래한 것이죠.
래블업 또한 이러한 변화를 등에 업고 성장 가도를 달릴 수 있었습니다. 본격적으로 흑자가 발생하기 시작한 2020년 이후 꾸준하게 성장폭을 이어오고 있는데, 여기에는 거대 언어 모델의 등장으로 인한 국내 대기업과 클라우드 회사들의 적극적인 AI 인프라 투자가 한 몫 했습니다. 위에 언급한 것처럼 창업 초기에는 국내 매출만으로는 회사의 생존도 쉽지 않을 것이라 예상했지만, 이 예상은 보기 좋게 깨졌습니다. 물론, 지금 잘 번다고 앞으로도 그러리라는 보장은 없고, 지속적인 성장을 위해서는 시장 규모 자체가 압도적으로 차이나는 해외 시장으로 눈을 돌릴 필요가 여전히 있습니다.
Python Rocks!
 래블업의 기술적 발전 역사에는 Python 또한 빼놓을 수 없습니다. 혹시 기억하시는 분이 얼마나 있을지 모르겠습니다만, 2009년만 해도 Python은 국내에서 '대안언어축제'에 당당하게(?) 자리할 만큼 아는 사람만 사용하는 그런 마이너한 프로그래밍 언어였습니다. 지금도 대규모 웹서비스나 SI 시장은 전자정부프레임워크 및 Spring의 영향으로 Java가 큰 비중을 차지하고 있지만, 이제는 Python으로도 웬만한 중·대규모 서비스를 구축하는 사례가 간간이 나오고 특히 AI 워크로드에서는 Python이 절대적인 지위를 갖고 있습니다. 2017년 ~ 2020년을 거치며 딥러닝 프레임워크는 TensorFlow와 PyTorch가 양대산맥을 이루게 되었는데, Keras와 같은 고수준 API가 등장하여 TensorFlow 2.0에 통합되고 Hugging Face가 transformers 라이브러리를 내놓으면서 Python이 본격적으로 "AI 프로그래밍 언어"로 인정받게 되었습니다.
래블업의 기술적 발전 역사에는 Python 또한 빼놓을 수 없습니다. 혹시 기억하시는 분이 얼마나 있을지 모르겠습니다만, 2009년만 해도 Python은 국내에서 '대안언어축제'에 당당하게(?) 자리할 만큼 아는 사람만 사용하는 그런 마이너한 프로그래밍 언어였습니다. 지금도 대규모 웹서비스나 SI 시장은 전자정부프레임워크 및 Spring의 영향으로 Java가 큰 비중을 차지하고 있지만, 이제는 Python으로도 웬만한 중·대규모 서비스를 구축하는 사례가 간간이 나오고 특히 AI 워크로드에서는 Python이 절대적인 지위를 갖고 있습니다. 2017년 ~ 2020년을 거치며 딥러닝 프레임워크는 TensorFlow와 PyTorch가 양대산맥을 이루게 되었는데, Keras와 같은 고수준 API가 등장하여 TensorFlow 2.0에 통합되고 Hugging Face가 transformers 라이브러리를 내놓으면서 Python이 본격적으로 "AI 프로그래밍 언어"로 인정받게 되었습니다.
이러한 흐름을 타고 국내외 PyCon (Python Conference) 또한 양적으로 엄청난 성장을 보였습니다. 안타깝게도 이러한 성장세는 코로나19 기간을 거치며 주춤하게 되었지만, 그 시기 저 또한 Sorna와 Backend.AI 개발 과정에서 맞닥뜨리게 된 다양한 asyncio 관련 문제들을 커뮤니티에 소개하고 이를 해결하는 라이브러리들도 직접 개발·공개하면서 Python 커뮤니티에 기여할 수 있는 기회를 얻을 수 있었습니다.
개인적으로는 학부 시절 SPARCS 동아리에서 2009년 봄학기에 첫 공개하여 지금도 사용되고 있는, 학사DB와 연동한 시간표 작성 및 과목사전/강의평가 기능을 제공하는 otl.kaist.ac.kr 서비스를 Django 기반으로 개발하면서 Python에 재미를 느끼게 되었고, 대학원 때 박사논문으로 개발한 NBA (Network Balancing Act) 프레임워크에 Python 인터프리터를 임베딩하여 복잡한 NUMA 환경에서 다중 네트워크 카드의 RX/TX 큐 매핑을 자동 설정하는 DSL (domain-specific language)로 Python을 활용하거나 Snakemake를 이용하여 CUDA, OpenCL, Xeon Phi용 SCIF 플랫폼 기반의 크로스빌드 구성을 해보고, asyncio를 이용하여 시스템 자원 소모를 최소화하면서 다중 노드와 다중 프로세스를 관리하는 네트워크 성능 실험 스크립트를 작성하며 긍정적인 경험을 지속적으로 축적하였습니다. 물론... 래블업 창업 이후에는 asyncio에 발등 찍힌 경험도 상당히 많았구요... ㅠㅠ
이런 과정을 거치며 Python은 제 개발 경력에서 빼놓을 수 없는 중요한 자리를 차지하게 되었습니다. 오히려 발등에 많이 찍혀야 했기에(...) asyncio를 통해서 커뮤니티에 더 많은 사례 소개를 할 수 있었던 것이기도 합니다. 2023년에는 PyCon US에서 세션 발표를 통해 asyncio의 디버깅 기능 강화가 필요하다는 것을 어필할 수 있었고, 결국 작년(2024년)에는 PyCon Korea에서 키노트 발표도 진행할 수 있었습니다. 당시에 나름 2015년부터 한 해도 빠지지 않고 진행해온 PyCon Korea 발표들을 창업 시점의 이야기, asyncio와 삽질한 이야기, 엔터프라이즈 고객과 함께 성장하기, 그리고 영향력 있는 엔지니어링으로 세상을 이롭게 하자 이렇게 나누어 되돌아보는 시간을 가졌습니다. 이제는 올해 GTC 출장에서 참석하게 된 WheelNext 워킹그룹과 다가오는 PyCon US에서 열릴 Packaging Summit에도 참석하여 가속기별로 특화된 대규모 바이너리 배포를 좀더 쉽게 할 수 있는 wheel 차세대 규격 논의에 참여하는 등 좀더 많은 사람들에게 도움을 줄 수 있는 영향력(influential) 엔지니어링을 하고자 합니다.
래블업의 구성원들 또한 그동안 많은 PyCon 발표를 통해 커뮤니티에 기여해왔고, 앞으로도 다양한 이야기들을 지속적으로 선보일 수 있으리라 생각합니다. 이 자리를 빌어 한국 파이썬 커뮤니티에도 감사하다는 말씀 전하고 싶습니다.
AI Factory 시대
 2025년 NVIDIA GTC 키노트에서 젠슨황은 AI 산업을 유한한 자원 내에서 '토큰'을 가장 많이 효율적으로 찍어내는 것을 지상 목표로 하는 제조업으로 비유하기도 했습니다. AI Factory라는 용어가 그런 뜻으로 나온 것이기도 합니다. 실제로 고객사들에서도 이제는 모델을 직접 훈련시키거나 파인튜닝할 때와 달리 GPU나 CPU와 같은 연산자원을 몇 시간 또는 몇 분 동안 점유했는지 기준이 아니라 토큰을 얼마나 생성해냈는지를 기준으로 하는 AI 모델 서비스 과금 체계를 만들고 싶다는 의견도 나오고 있습니다.
2025년 NVIDIA GTC 키노트에서 젠슨황은 AI 산업을 유한한 자원 내에서 '토큰'을 가장 많이 효율적으로 찍어내는 것을 지상 목표로 하는 제조업으로 비유하기도 했습니다. AI Factory라는 용어가 그런 뜻으로 나온 것이기도 합니다. 실제로 고객사들에서도 이제는 모델을 직접 훈련시키거나 파인튜닝할 때와 달리 GPU나 CPU와 같은 연산자원을 몇 시간 또는 몇 분 동안 점유했는지 기준이 아니라 토큰을 얼마나 생성해냈는지를 기준으로 하는 AI 모델 서비스 과금 체계를 만들고 싶다는 의견도 나오고 있습니다.
경영 관점에서 기업 활동을 크게 두 가지 카테고리로 나누기도 하는데요, 바로 비용 센터와 수익 센터입니다. 기존에는 직접 foundational model을 만들겠다거나 AI 연구개발 조직을 꾸리겠다고 하면 대부분의 경우 선행기술에 대한 R&D 비용을 지불·투자하는 비용 센터에 가까웠습니다. 그 중에서 나름 성공적으로 여러 서비스에 응용할 만한 모델까지 간 사례도 있지만, 대부분의 경우 경영진이 어지간히 강한 의지를 갖고 있는 것이 아니라면 들어간 시간과 비용으로부터 충분한 유형·무형의 이득을 얻기란 쉽지 않았고 장기간 투자를 지속하는 것도 어려웠습니다.
AI Factory 개념은 이제 AI가 비용 센터가 아닌 수익 센터로 전환되고 있다는 것을 의미합니다. 공개형 언어모델들도 상용 제품에 활용할 수 있을 만큼 성능이 좋아지고, 하드웨어나 소프트웨어도 점점 접근성이 좋아지면서 이제는 모델 자체의 구조를 새로 개발하기보다는 널리 알려진 모델들을 가져와서 빠르게 돌려보고 평가하고 튜닝하고 서비스에 적용하는 것이 더 중요해졌습니다. 그렇게 해서 기존의 제품과 서비스에 AI를 접목하여 사용자들이 더 많은 일을 유연하게 할 수 있도록 하거나, AI 에이전트나 챗봇 자체가 서비스의 핵심 수단이 됨으로써 돈을 벌어들일 수 있는 수단이 된 것이죠. 이러한 전환이 의미하는 것은, 이제 AI 기반 서비스로 돈을 벌 수 있다면 그 인프라 규모는 계속해서 더 늘어날 수 있다는 것입니다. 공장을 더 지어서 제품(토큰)을 더 찍어내고 그만큼 돈을 더 벌 수 있다면 투자의 규모가 달라지겠죠. 아직은 돈을 태우는 분야라는 인식이 더 강하지만, 분야의 발전 속도나 새로운 서비스 시도들이 끊임없이 나오고 있는 점을 볼 때 산업 전체의 관점에서 손익분기를 넘는 것은 시간 문제입니다.
AIDC(AI 데이터센터) 분야에서 2024-2025년 기준 가장 큰 병목은 에너지 확보입니다. 미국의 빅테크들이 현재 운영하고 있는 AIDC들은 대략 1 GW 정도 규모라면, 차세대로 준비하고 있는 것들은 5 GW 정도 규모입니다. 일론머스크가 한달 만에 발전트럭들까지 끌어모아 지은 데이터센터는 200 MW 정도 규모였고 지속적으로 확장하고 있습니다. 이제 그 다음 세대가 되면 10~20 GW급의 데이터센터들이 등장하겠죠. 과연 이만큼의 전력을 어디에서 끌어올 수 있는지 자체가 이제 이슈가 되는 상황입니다. 이미 B200 8장 꽂혀있는 노드 1개가 14 kW 수준의 전력을 소비하고, NVL72 랙에서는 130 kW를 요구하고 있는 상황에서, Grace Blackwell의 다음 버전으로 올해 GTC에서 발표한 Vera Rubin 기반의 NVL576 랙은 무려 600 kW의 전력을 소비할 것이라고 합니다. 랙 2개만 놓아도 MW 단위가 되는 것이죠. 이 추세대로 갈지 아니면 다른 대안을 모색하게 될지 모르겠지만, SMR 같은 소형 원전 기술이나 핵융합 발전 같은 것이 상용화된다면 일정 규모 이상의 AIDC를 건설·운용하기 위해선 필수적인 설비가 될지도 모르겠습니다.
Agent를 거쳐 AGI에 이르는 길
사실 엄밀하게는 현재의 AI 기술은 범용적으로 인간과 같은 지능과 의식을 가졌다고 하기 어렵고, 결정론적 컴퓨터 프로그램으로 모델링하거나 작성하기 어려웠던 특정한 종류의 작업을 인간 수준과 동등하거나 더 우수하게 해결할 수 있는 '약(weak) 인공지능'이라고 봐야 합니다. AI 업계에서도 '강(strong) 인공지능' 또는 AGI(Artificial General Intelligence)는 아직까지 도달하지 못한 일종의 성배에 가까운 개념입니다. 물론 사람마다 또는 회사마다 우리 인류가 언제쯤 AGI에 도달할 수 있을 것인가에 대한 예측은 굉장히 다르고요.
그럼에도 불구하고 저는 인간의 자연 언어를 컴퓨터와 상호작용할 수 있는 주요한 인터페이스로 만들어주었다는 점에서 생성형 AI 기술은 이미 지금 형태로도 무궁무진한 가능성을 갖고 있다고 생각합니다. 기존에는 소위 "computational thinking"을 할 수 있다 하더라도 자신이 하고자 하는 일을 프로그래밍 언어 내지 최소한 스크립트 형태로 표현할 수 있어야 컴퓨터의 능력을 자유롭게 활용할 수 있었지만(물론 IT 업계에는 이 과정을 조금 더 쉽게 만들어주기 위한 수많은 노코드 및 워크플로우 도구들이 있지만 아무래도 그 자유도가 제조사가 정해놓은 범위 안으로 제한될 수밖에 없습니다), 이제는 개떡같이 말해도 찰떡같이 알아듣고 내가 원하는 일을 수행해줄 수 있는 Agent들이 점점 늘어나고 있습니다.
최근 유행하는 용어로 바이브 코딩(vibe coding)이라는 말이 있습니다. 기존에는 VSCode, Cursor, Zed와 같은 IDE에서 심볼 정도 수준이 아닌 여러 줄의 코드까지 포함하는 일종의 확장된 자동완성 기능을 생성형 AI로 구현해주는 느낌이었다면, 바이브 코딩에서는 대부분의 코드 작성 작업을 모두 AI Agent가 도맡고 사람은 아이디어나 설계만 던져주는 방식을 말합니다. 생각과 의식의 흐름에 맡기고 손으로 코드를 치는 작업은 AI에게 모두 일임한다 이런 느낌이죠.
이러한 흐름을 보며 기술 발전 속도가 대단하다 느끼면서도(또한 거기에 한몫 하고 있다고 생각하면서도), 동시에 앞으로 신입 엔지니어들의 역할은 무엇이 되어야 하는가에 대한 고민도 함께 깊어지고 있습니다. 이미 산전수전 개발 경험을 쌓은 시니어나 아키텍트 수준의 사람들, 그러니까 이러한 AI Agent들이 만들어준 코드를 빠르게 평가하고 수정 지시하거나 요구사항을 구체적으로 적는 게 가능한 사람들에게는 이러한 AI 도구들이 자신의 생각을 빠르게 실현해주는 좋은 도우미이지만, 막상 그러한 경험 자체를 쌓아나가야 하는 학생들이나 신입 엔지니어들에게는 자신의 일자리를 위협할 수도 있는 경쟁자인 것도 현실입니다. 하지만 인간의 수명은 무한하지 않고, 지금의 시니어 인력들이 AI를 통해 폭발적 생산성을 달성하더라도 이 사람들이 영원히 모든 일을 다 할 수는 없습니다. 그렇다면 현재의 신입 인력들이 어떤 방법으로 AI들을 잘 활용할 수 있도록 학습·성장을 지원할 수 있는가에 대해서도 생각을 해봐야 되겠죠. 개인적으로는 생각의 구조화와 퇴고를 포함한 글쓰기 능력과 메타인지가 이런 AI 기술이 보편화된 세상에서 살아남고 나아가 이를 활용하는 데 가장 중요하지 않을까 싶습니다.
앞으로의 10년
 3명에서 시작하여 35명에 다다르면서 이제는 개인기보다는 팀워크와 조직의 움직임이 더 중요해지는 어떤 변곡점에 도달한 것 같습니다. 이제는 점점 사람들과 팀과 회사들을 연결하고 프로젝트를 구상하고 전체적인 일의 얼개를 짜는 일의 비중이 높아지고 있고요. 어떤 점에서는 코드 대신 조직을 '작성' 또는 '디버깅'한다는 느낌이 들 때도 있습니다. 한편으로는 좀 내려놓고 쉬고 싶다가도 달리는 호랑이 등에 올라탄 상황이라 어쩔 수 없이 몸은 쉬더라도 머리는 계속 돌아가야 하는 운명이기도 합니다. 그래도 일거리가 없어서, 돈이 없어서 힘들어하는 상황보다는 훨씬 즐거운 고민의 연속이라 생각합니다.
3명에서 시작하여 35명에 다다르면서 이제는 개인기보다는 팀워크와 조직의 움직임이 더 중요해지는 어떤 변곡점에 도달한 것 같습니다. 이제는 점점 사람들과 팀과 회사들을 연결하고 프로젝트를 구상하고 전체적인 일의 얼개를 짜는 일의 비중이 높아지고 있고요. 어떤 점에서는 코드 대신 조직을 '작성' 또는 '디버깅'한다는 느낌이 들 때도 있습니다. 한편으로는 좀 내려놓고 쉬고 싶다가도 달리는 호랑이 등에 올라탄 상황이라 어쩔 수 없이 몸은 쉬더라도 머리는 계속 돌아가야 하는 운명이기도 합니다. 그래도 일거리가 없어서, 돈이 없어서 힘들어하는 상황보다는 훨씬 즐거운 고민의 연속이라 생각합니다.
스타트업 업계에서 어쨌든 창업 후 10년을 살아남고 또 손익분기를 넘어 수년 간 흑자를 달성했다는 것은 정말 시작할 때만 해도 여기까지 올 수 있을까 미처 생각하지 못했던 성과입니다. 초등학교 ~ 고등학교까지 12년, 학부 ~ 대학원까지 11년 반, 그리고 래블업에서 10년. 앞으로 또 어떤 모험이 펼쳐질지 기대되기도 하고, 한편으로는 이제 내 손에서 코드라는 자식이 떠나서 아쉽기도 한가 하면, 어차피 필요하면 바이브 코딩을 하면 되잖아? 하는 생각이 들기도 하는... 그런 복합적인 감정이 드네요.
비행기에서 작성하기도 하고, 휴일을 맞아 그나마 시간을 내어 동네 카페에서 작성하기도 하고, ChatGPT의 도움을 받아 업계 역사도 다시 정리해보고 하면서 다시 한번 내가 어떤 맥락 속에서 일하고 있는지 되돌아볼 수 있었습니다. 10년 동안 래블업을 알게 모르게 응원해주신 분들께 감사드리면서, 앞으로도 멋진 래블업의 성장 소식을 들려드릴 수 있도록 하겠습니다.