여러분이 놀라운 AI를 만들고 서비스하는 동안 백엔드는 Backend.AI가 맡겠습니다.

핵심 역량
한 대부터 수천 대까지 압도적인 GPU 관리 능력
Backend.AI는 멀티노드 멀티테넌트 환경에서 수천 대의 GPU를 하나의 플랫폼으로 관리합니다. 하나의 GPU를 여러 사용자가 나누어 쓰는 Fractional GPU부터 수백 대의 GPU를 동시에 활용하는 대규모 학습까지, 규모에 관계없이 최적의 자원 활용을 보장합니다.

GPU를 도입한다고 끝이 아닙니다
엔터프라이즈 GPU 인프라에서 가장 빈번하게 발생하는 문제와 Backend.AI의 해결 방법입니다.
GPU를 충분히 활용하지 못하고 있습니다
수십억을 투자하여 GPU를 도입했지만 실제 활용률은 30%에 미치지 못합니다. 한 팀이 GPU 8장을 할당받고도 실제로는 2장만 사용하는 상황이 반복됩니다.
해결 방법 보기 →
Fractional GPU로 한 대도 남김없이
물리 GPU를 소수점 단위로 분할하여 여러 사용자가 동시에 활용합니다. 모든 NVIDIA GPU에서 동작하며, 5% 미만의 오버헤드로 활용률을 극대화합니다.
A기업 GPU 활용률 30% → 85% (2.8배 향상)
GPU를 나눠 사용하기 어렵습니다
여러 팀이 GPU 클러스터를 공유하지만 배분 기준이 없습니다. 긴급한 실험이 있어도 다른 팀의 자원 점유로 대기해야 하는 상황이 발생합니다.
해결 방법 보기 →
4계층 멀티테넌시로 공정하게 배분
조직, 부서, 프로젝트, 사용자 4계층으로 자원을 관리합니다. 유휴 자원은 동적 할당을 통해 다른 부서에 자동 재배분됩니다.
B 대학 관리자 개입 없이 자원 관리 자동화
클라우드 도입이 제한되는 환경입니다
민감한 정보를 다루는 업종이기 때문에 외부 클라우드 AI 서비스 도입이 제한됩니다. 폐쇄망 환경에서 AI를 운영해야 합니다.
해결 방법 보기 →
완전한 폐쇄망 독립 운영
설치부터 모델 배포, 업데이트까지 외부 인터넷 연결 없이 동작합니다. 다중 보안 샌드박싱으로 금융·국방 수준의 보안 요구사항을 충족합니다.
C 은행 폐쇄망 LLM 운영
GPU 가격 문제와 물량 문제를 겪고 있습니다
GPU 가격 상승과 공급 부족으로 AMD, Intel, 혹은 국산 NPU 도입을 검토하고 있지만, 의존성이 있어서 특정 플랫폼 생태계에서 벗어나기 어렵습니다.
해결 방법 보기 →
12개+ 벤더, 하나의 통합 인터페이스
하드웨어 추상화 계층(HAL)으로 NVIDIA, AMD, Intel, Google TPU, 리벨리온, 퓨리오사AI, 텐스토렌트 등을 단일 인터페이스에서 관리합니다.
D 기업 GPUaaS 사업 위해 Backend.AI 위에서 국산 NPU 도입
늘어나는 GPU 수요에 대응해야 합니다
AI 서비스 확대로 GPU를 추가 도입하고 있지만, 수십 대에서 수백 대로 늘어난 멀티노드 환경을 기존 도구로는 관리할 수 없습니다.
해결 방법 보기 →
Sokovan 오케스트레이터가 규모에 맞춰 확장
Sokovan 스케줄러는 멀티노드·멀티테넌트 워크로드를 규모에 관계없이 처리합니다. GPU와 스토리지 등 AI 인프라가 증가해도 재설계 없이 유연하게 대응합니다.
E 대학교 보유 노드 256% 증가에도 안정적인 서비스 운영
팀이 늘어나 운영이 복잡해졌습니다
팀 규모가 커지다 보니 우선순위 충돌, 대기열 문제가 발생합니다. 인력 변경이 생길 경우 운영 노하우가 사라지는 것도 걱정입니다.
해결 방법 보기 →
Scalable 인프라를 감당하는 소프트웨어
Backend.AI는 정책 기반으로 GPU 운영을 자동화합니다. 자원 할당량, 스케줄링 규칙, 접근 제어가 정책으로 정의되어 효율적인 운영이 가능합니다.
F 대학교 최소한의 인력으로 학내 인프라 운영
핵심 기술
Sokovan. AI 워크로드를 아는 진짜 전문가를 만나보세요
Sokovan은 AI 인프라를 위한 가장 강력한 컨테이너화된 워크로드 오케스트레이터로, 처음부터 AI를 고려하여 설계되었습니다. 매니저와 에이전트 이중 레이어로 구성된 스케줄링 시스템을 핵심으로, 멀티테넌트 환경에서 하드웨어 활용률, 성능, 운영 효율성을 극대화합니다.
Sokovan 알아보기 →
유휴에서 유능으로
컨테이너 수준의 GPU 가상화
Backend.AI 독자 특허 기술로 컨테이너 내부 CUDA API 호출을 가로채 GPU 리소스를 소프트웨어 수준에서 정밀하게 제어하는 방법입니다. 물리 GPU 하나를 여러 사용자가 안전하게 공유하면서도 워크로드 간 완전한 격리를 보장합니다.
400%
GPU 활용률 향상
75%
인프라 비용 절감
3
특허 등록 (KR/US/JP)
GPU 활용률 비교
다중 사용자 GPU 공유
User A
0.25 GPU
User B
0.5 GPU
User C
0.15 GPU
User D
0.1 GPU
하드웨어에 종속되지 않는 접근
12종 이상의 AI 가속기를 지원하는 벤더 중립적 플랫폼
Backend.AI는 하드웨어 추상화 계층(HAL)을 통해 NVIDIA Blackwell, Intel Gaudi, AMD Instinct, Rebellions ATOM+, FuriosaAI RNGD 등 12종 이상의 AI 가속기를 단일 인터페이스로 관리합니다. 어떤 가속기를 사용하든 동일한 워크플로로 개발, 학습, 배포가 가능합니다.










스토리지의 중요성을 아는 인텔리전트 플랫폼
어떤 스토리지든, 하나의 인터페이스로
VAST, WEKA, PureStorage, IBM Storage Scale 등 스토리지 백엔드의 종류와 상관없이 동일한 방식으로 접근하고, NVIDIA GPUDirect Storage를 지원하여 스토리지에서 GPU 메모리로 데이터를 직접 전송할 수 있습니다.
자세히 보기 →







Mind the gap
폐쇄망에서도 완전한 AI 환경을 운영합니다
Reservoir AI(모델 허브) + Reservoir(패키지 저장소)
금융, 국방, 공공 기관처럼 외부 인터넷 연결이 불가능한 환경에서도 AI 모델과 개발 도구를 최신 상태로 유지할 수 있습니다. Reservoir가 폐쇄망 AI 인프라의 소프트웨어 공급망을 완결합니다.
Reservoir 알아보기 →Air-Gapped Network Boundary
Backend.AI Control Plane
Control
Data
GPU Nodes
직관적인 웹 기반 관리
GPU 활용, 운영의 장벽을 낮추는 인터페이스
Backend.AI WebUI는 CLI 전문 지식 없이 브라우저만으로 GPU 클러스터 관리, 리소스 모니터링, 멀티테넌트 환경 거버넌스를 수행할 수 있습니다. 세션 관리부터 정책 기반 자원 배분까지, 하나의 통합 인터페이스에서 이루어집니다.
WebUI 알아보기 →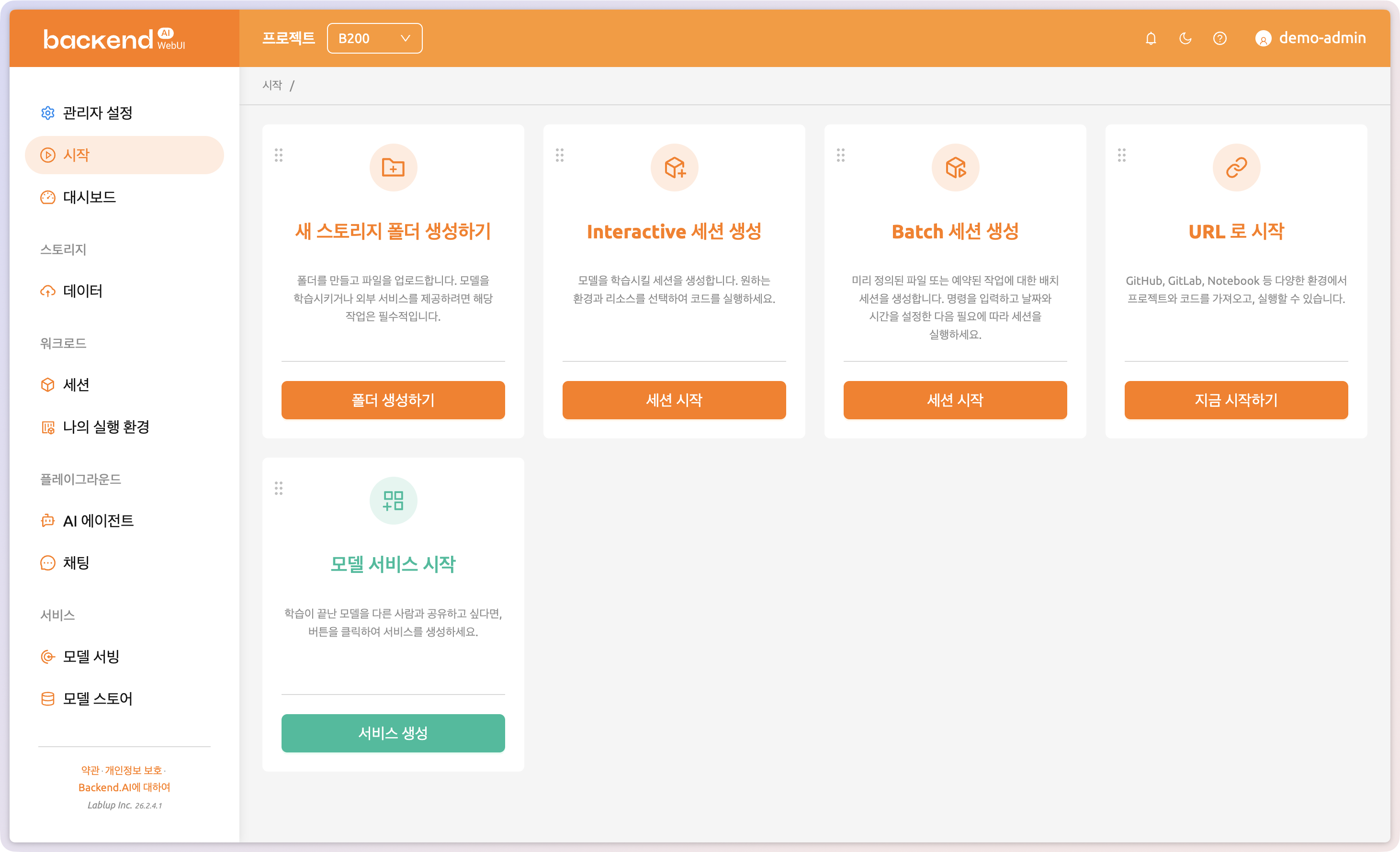
NVIDIA DGX-Ready 소프트웨어
NVIDIA DGX를 위해 설계된 엔터프라이즈 규모의 인증된 AI 플랫폼
NVIDIA DGX-Ready 소프트웨어로 인증받은 Backend.AI는 NVIDIA DGX 시스템 및 Grace Blackwell과의 원활한 운영을 보장하며, 컨테이너 수준 GPU 분할가상화와 Sokovan 오케스트레이터를 결합하여 다양한 스케일에서의 AI 및 HPC 워크로드의 활용도를 최적화합니다.
DGX-Ready 알아보기 →
어떤 환경에서든 동일하게 동작합니다
온프레미스, 클라우드, 하이브리드 중 조직의 보안 정책과 인프라 환경에 맞는 배포 모델을 선택할 수 있습니다.
온프레미스
모든 데이터와 워크로드가 고객의 데이터센터 내에서 처리됩니다. 폐쇄망(Air-gapped) 환경에서도 독립적으로 운영할 수 있습니다.
- 완전한 데이터 주권 보장
- 폐쇄망(Air-gapped) 지원
- 규제 준수 용이
클라우드
AWS, GCP, Azure, OCI 등 퍼블릭 클라우드의 GPU 인스턴스 위에서 운영됩니다. 초기 투자 없이 즉시 시작할 수 있습니다.
- 초기 투자 없이 즉시 시작
- 탄력적 확장/축소
- 글로벌 리전 즉시 배포
하이브리드
온프레미스와 클라우드를 하나의 제어 평면에서 통합 관리합니다. 민감한 데이터는 온프레미스에서, 버스트 워크로드는 클라우드로 분산합니다.
- 단일 제어 평면 통합 관리
- 정책 기반 워크로드 배치
- 기존 온프레미스 투자 보호
Dashboard & management
모든 것을 모니터링하고 관리하고 제어합니다
| GPU | Model | Util | VRAM | Temp | Power |
|---|---|---|---|---|---|
| GPU | H200 141 | 79.1% | 84.2/141GB | 78°C | 511/700W |
| GPU | H200 141 | 28.8% | 90.0/141GB | 63°C | 420/700W |
| GPU | H200 141 | 36.1% | 61.6/141GB | 63°C | 385/700W |
| GPU | H200 141 | 66.2% | 69.3/141GB | 75°C | 502/700W |
대시보드를 통해 리소스 사용량, 세션 상태, 인프라 현황 등 다양한 정보를 한눈에 모니터링할 수 있습니다. All-SMI를 통해 NVIDIA, AMD, Intel Gaudi, Google TPU 등 이기종 가속기와 서버 상태를 단일 인터페이스에서 통합 모니터링합니다. 팀과 사용자 관리 등 조직을 위한 기능이 기본으로 제공됩니다.
All-SMI 알아보기 →Customers
대학, 연구기관, 기업이 선택하는 Backend.AI
캠퍼스 연구실부터 엔터프라이즈 데이터센터까지, 110여곳 이상의 다양한 조직이 Backend.AI의 이점을 경험하고 있습니다.

KT
통신/클라우드

KT Cloud
통신/클라우드

NHN Cloud
통신/클라우드

삼성전자
IT/전자

LG전자
IT/전자

CJ AI Center
IT/전자

신한은행
금융

한국은행
금융

현대모비스
모빌리티

대한항공
항공

삼성웰스토리
식품

LIG넥스원
국방/방산

대한민국 해군
국방/방산

경기도청
공공기관

삼성서울병원
의료/바이오

분당서울대병원
의료/바이오

건강보험심사평가원
의료/바이오

삼성리서치
IT/전자

한국전자통신연구원
연구소/공공기관

한국과학기술정보연구원
연구소/공공기관
Univ. of Southern California
대학
성균관대학교
대학

국민대학교
대학
And more...
Customer stories
Backend.AI와 함께 구축하는 고객 사례
전 세계 대학, 연구기관, 기업이 Backend.AI로 GPU 인프라를 혁신하고 있습니다
Lablup의 클라우드 리소스 덕분에 연구 운영이 효율화되었습니다. Backend.AI의 빠르고 편리하며 어디서나 접근 가능한 플랫폼으로, 우리 팀은 장소에 관계없이 생산성을 유지하고 있습니다.
KIST CJLab 화학생명융합연구센터 정철현 박사 연구팀
사례 보기→GPU를 효율적으로 사용하도록 만들어 주는 Backend.AI의 컨테이너 수준 GPU 분할가상화 덕분에 초창기 GPU 서버 3대 만으로도 수십명의 학생들이 동시에 머신러닝 실습을 할 수 있었어요. 전문 관리 인력 없이도 최소한의 인원으로 학내 인프라를 관리할 수 있게 되었습니다.
국민대학교 AI빅데이터융합경영학과 조윤호 교수
사례 보기→성균관대학교는 학내 슈퍼컴퓨팅 센터 운영을 통해 인프라 중복 투자를 막고, 보유하고 있는 자원을 효율적으로 사용하며, 지속적으로 자원을 업그레이드함으로써 캠퍼스 연구 역량을 향상시켰습니다.
성균관대학교 슈퍼컴퓨팅센터 최형기 센터장
사례 보기→대학이 보유한 자원을 학생들이 제대로 활용할 수 있도록 돕는 플랫폼의 존재는 매우 중요합니다. Backend.AI는 AI 인프라를 쉽게 관리하고, 자원에 쉽게 접근할 수 있게 만드는 운영 플랫폼입니다.
김병도 Associate Chief Research Information Officer
사례 보기→
업스테이지는 인프라 단의 모든 것을 Backend.AI에게 맡겼습니다. 덕분에 인프라 관리에 시간을 할애하는 대신 거대언어모델(LLM) 개발에 매진할 수 있었습니다.
업스테이지 컨소시엄 이승윤 리드
사례 보기→
askyour.trade 2.0은 AI가 문서를 이해하고 자율적 결정을 내리는 지능형 무역 워크스페이스입니다. 팀리부뜨는 래블업과 함께 무역 사무 운영 과정에서의 디지털 전환(DX)을 가속화하고 있습니다.
팀리부뜨 최성철 대표
사례 보기→글로벌 리더들이 신뢰하는 파트너


VAST COSMOS
Technology Partner
Pure Storage
Tech Alliance Partner



