May 9, 2025
Celebrating 10 Years of Lablup: Reflections on a Decade of Upgrading the Lab

Joongi Kim
Co-Founder / CTO
May 9, 2025
Celebrating 10 Years of Lablup: Reflections on a Decade of Upgrading the Lab
Joongi Kim
Co-Founder / CTO
On April 21, 2025, Lablup marked its 10th anniversary. What began as a small step has become a long journey, with much still ahead. This milestone offers an opportunity to reflect on Lablup’s first decade and the rapid evolution of AI technology alongside our company.
Linux Containers: The Foundation

Many who know Lablup have heard that our name comes from “Upgrading the Lab.” When we founded the company in 2015, most of us were current or former lab researchers, frustrated with the repetitive technical hurdles in research environments. Managing a 1,000-node CPU cluster in a physics department, for example, meant endless struggles with compiler and library compatibility and frequent hardware failures. Our CEO, Jeongkyu Shin, and I, who was building a GPU-accelerated packet processing framework, came together to find a way to reduce these pains for others.
Our current motto is “Make AI Accessible,” and more specifically, “Make AI Scalable.” Back in 2015, our mission was to lower the barriers for reproducible computing environments in scientific research through the cloud.
In the field of HPC and supercomputing, traditional virtual machine technologies which fully virtualize entire hardware systems to create separate, independent environments are not widely used due to their performance overhead. As a result, supercomputing centers at universities and research institutions have long relied on a different approach to support multiple users running their own workloads. To allow users to access specialized libraries or specific versions of C/Fortran compilers without conflicts, these centers use the module command to manage environment variables such as PATH and LD_LIBRARY_PATH. This method enables users to load and unload software environments as needed, preventing interference between users. Even today, this approach remains common in bare-metal environments where multi-user workloads are managed directly, often using workload managers like Slurm.
What drew attention at the time was Linux container technology. Since Solomon Hykes first introduced Docker as the technology behind dotCloud during a lightning talk at PyCon US in 2013, Docker gradually gained popularity in the cloud industry as a convenient way to deploy software with complex dependencies. While kernel namespaces (cgroups), which form the foundation of Linux containers, had existed previously, Docker combined them with layered filesystems and packaged them as an application deployment environment offering reproducible environments based on reusable library layers. This provided developers with truly reproducible development and deployment environments.
 In my view, Linux container technology was the key to bridging the gap. It archives the convenience of software deployment and reproducible environments enabled by virtualization, while still allowing access to near bare-metal hardware performance. For this reason, Lablup’s initial technical goal was to provide a high-performance computing environment based on container technology. It was with this theme that Lablup was first introduced to the world through a presentation at PyCon Korea 2015.
In my view, Linux container technology was the key to bridging the gap. It archives the convenience of software deployment and reproducible environments enabled by virtualization, while still allowing access to near bare-metal hardware performance. For this reason, Lablup’s initial technical goal was to provide a high-performance computing environment based on container technology. It was with this theme that Lablup was first introduced to the world through a presentation at PyCon Korea 2015.
While developing a high-performance computing platform based on containers, I discovered (as somewhat expected) that containers expose far more host system information to internal applications than anticipated. In some cases, we limited the number of CPU cores to eight using the cgroup affinity mask. However, because BLAS and OpenMP libraries still created as many threads as there were total CPU cores on the host, this sometimes led to significant performance degradation. Commands like htop or ps would also reveal the host’s actual CPU and memory specifications. Additionally, we needed to prevent user code from arbitrarily killing container internal workload management processes.
To address these issues, we built a custom sandboxing layer combining seccomp for syscall control and symbol hooking to override specific libc APIs. Ironically, shortly after releasing this solution, Docker switched its default sandboxing mechanism to seccomp, a clear sign that many in the industry were grappling with similar challenges at the time. Today, more sophisticated solutions like lxcfs exist, which virtualize /proc filesystem entries to prevent such host information leaks.
The Jurassic Park
Everything looks different on the other side.
— Ian Malcomm, from Michael Crichton's 'The Jurassic Park'
This quote, still used in Jeongkyu’s email signature, resonates with us. While “Jurassic Park” is remembered for its groundbreaking CGI and animatronics, the original novel left a deeper impression on Jeongkyu due to its focus on complexity theory. In the story, Dr. Ian Malcolm, a genius mathematician from UT Austin, embodies this theme.
You may already know that NVIDIA names its GPU architectures after famous scientists who have made foundational contributions to electronics and computing, such as Ada Lovelace, Ampere, Turing, Pascal, Maxwell, Kepler, Fermi, and Tesla. AMD, on the other hand, uses the names of Italian cities for its EPYC CPU models. (Examples include Naples, Rome, and Milan.) Apple’s operating systems were once named after big cats, but in recent years they have shifted to naming them after well-known locations in California.
In fact, one of the most challenging tasks for developers is naming things. It’s quite common to use names of stars or constellations when naming servers, for example.
 Of course, we were no different. What does Jeongkyu love? The Jurassic Park. That’s why we started naming our servers after dinosaurs. We dropped the common suffix “-saurus” and went with names like tyrano, raptor, bronto, and so on. (One thing we discovered during this process was that paleontology has advanced quite a bit. There are now plenty of dinosaur names we’d never even heard of as kids.)
Of course, we were no different. What does Jeongkyu love? The Jurassic Park. That’s why we started naming our servers after dinosaurs. We dropped the common suffix “-saurus” and went with names like tyrano, raptor, bronto, and so on. (One thing we discovered during this process was that paleontology has advanced quite a bit. There are now plenty of dinosaur names we’d never even heard of as kids.)
Naturally, this led us to think about containers that would “carry” dinosaurs, and so our backend project was codenamed Isla Sorna, after the island in the Jurassic Park novels and films where dinosaurs were cloned and bred in laboratories. The frontend project was codenamed Isla Nublar, the island where visitors actually experienced the park. The long-polling-based code execution protocol handler that connected the two was named Ingen, after the fictional company responsible for dinosaur research and development.
![]() That’s how the Sorna icon I drew myself on an iPad came to be.
That’s how the Sorna icon I drew myself on an iPad came to be.
CodeOnWeb and the AlphaGo Shock
Today, Lablup commercializes the Backend.AI platform for enterprise customers, making AI development and services more accessible and affordable. But our initial business model was not enterprise solutions.
In late 2015, we built a prototype remote code execution API based on containers, but few investors understood the need for such a platform. We knew the Korean market would be tough, so we targeted the US and global markets, documenting all development in English. An angel investor suggested pivoting to the booming coding education market by adding a GUI and selling it as an online lecture management system. This led to our first product, CodeOnWeb. We even developed coding curricula based on elementary school math and science textbooks.
Around that time, two important things happened.
The first major milestone was Google’s open-sourcing of the TensorFlow framework in December 2015. Before this, building deep learning models required developers to handcraft matrix operations in C/C++, use Fortran, or rely on more traditional machine learning libraries like numpy and scikit-learn. Caffe was one of the more advanced frameworks available at the time, and Torch provided a higher-level interface based on Lua, but both had significant limitations, especially when it came to data preprocessing and integration with other systems.
With the release of TensorFlow, even though its initial interface would now be considered quite low-level, developers could finally write deep learning code more easily in Python. This marked a turning point, as TensorFlow offered a general, flexible, and open-source platform that accelerated the adoption and development of deep learning across both research and industry.
The second major milestone was the Go match between Lee Se-dol and AlphaGo in March 2016. The result was a victory for AlphaGo. I remember that in my graduate lab, we made small bets on who would win, and I was one of the very few who believed AlphaGo would achieve a clean sweep. My reasoning was that GPUs are extremely suited for deep learning tasks (in hindsight, I should have bought NVIDIA stock back then), and given enough training, there was no reason why the deep learning approach couldn’t prevail.
However, for the general public, this event was a massive shock. In Korea, the impact was so great that even taxi drivers were talking about AlphaGo.
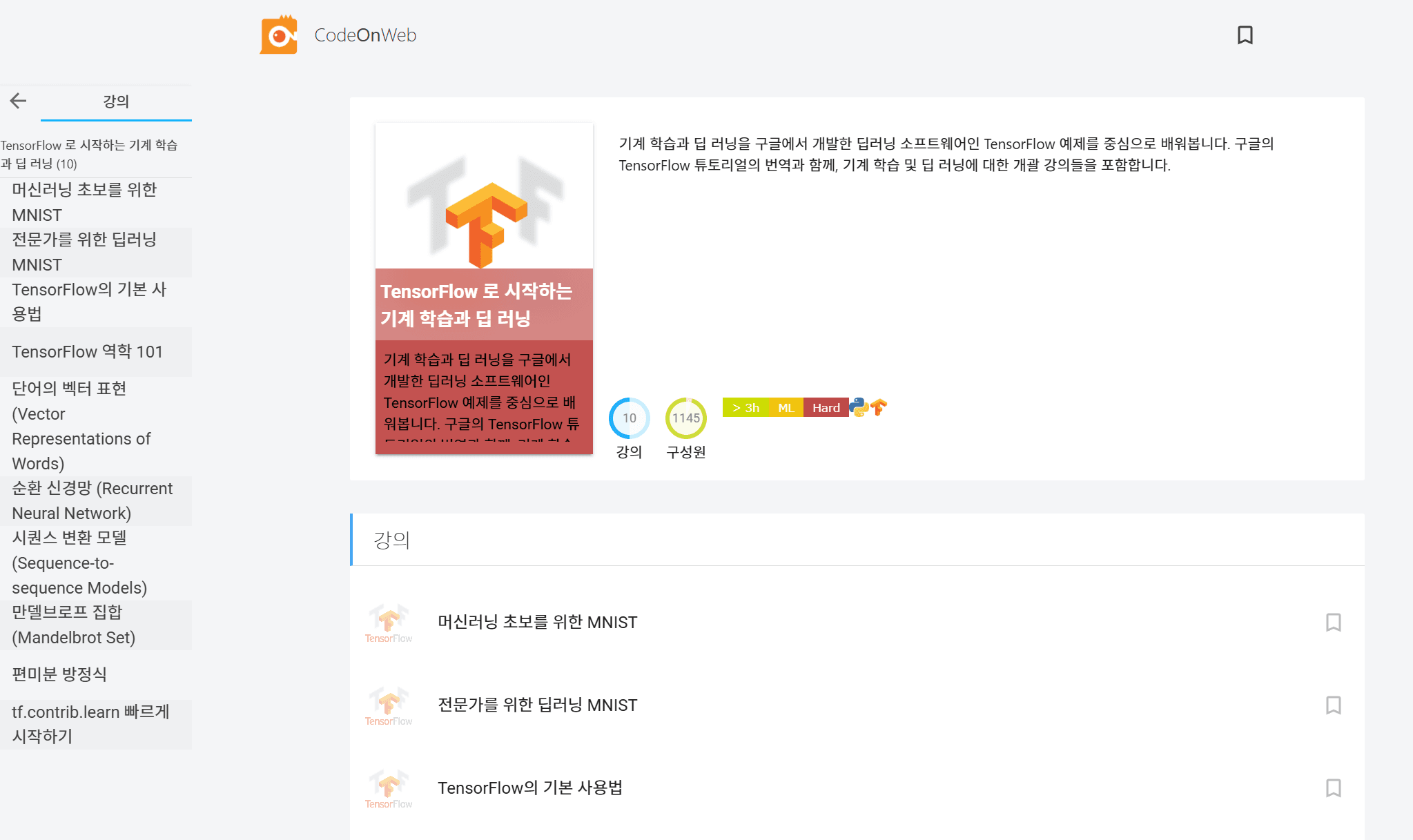 CodeOnWeb’s breakthrough into the global spotlight was propelled by two pivotal events. At the time, Jeongkyu translated the TensorFlow manual and converted it into CodeOnWeb lessons, making it available to the public in a form that allowed for hands-on coding practice. This initiative unexpectedly resonated deeply within Korea’s developer community, coinciding with the widespread "AlphaGo shock" that had captivated public attention. Later, we discovered that South Korea ranked third globally in TensorFlow-related Google search traffic, trailing only the U.S. and China during this period.
CodeOnWeb’s breakthrough into the global spotlight was propelled by two pivotal events. At the time, Jeongkyu translated the TensorFlow manual and converted it into CodeOnWeb lessons, making it available to the public in a form that allowed for hands-on coding practice. This initiative unexpectedly resonated deeply within Korea’s developer community, coinciding with the widespread "AlphaGo shock" that had captivated public attention. Later, we discovered that South Korea ranked third globally in TensorFlow-related Google search traffic, trailing only the U.S. and China during this period.
Around the same time, we implemented a cost-saving innovation: modifying TensorFlow to utilize just 1/3 of a GPU’s capacity on AWS p2 instances. This allowed users to run GPU workloads with a single click directly on CodeOnWeb. While unconventional, this optimization demonstrated our early focus on AI infrastructure efficiency and became a defining factor in Lablup’s recognition as an AI-focused company. These combined efforts laid the groundwork for securing our first Pre-Series A investment.
After 2017, instead of further developing the LMS features of CodeOnWeb, we decided to focus on advancing the Sorna project itself, evolving it into an independent GPU workload management system. This rebranding process ultimately led to the creation of the current Backend.AI platform.
There’s an interesting backstory here: when Lablup was based at Google Startup Campus Seoul, we had the opportunity to receive consulting from Google’s marketing and branding experts. Through this process, we discovered that “Sorna” was, unfortunately, also used as an abbreviation for 'Sex Offender Registration and Notification Act'. This prompted us to look for a new name, and that’s when we found that the domain “Backend.AI” was available, a fortunate coincidence that fit our vision perfectly.
GPU Virtualization
Between 2016 and 2017, CodeOnWeb shifted from being used mainly for university lectures to serving as a platform for hands-on deep learning sessions leveraging GPUs. At that time, relatively small-scale deep learning examples like fashion-MNIST were commonly used, which is an example that now seem quite modest in retrospect. During this period, TensorFlow was evolving rapidly, with new versions being released almost every month and a half, and after just three releases, backward compatibility with previous versions was no longer guaranteed.
Meanwhile, NVIDIA unveiled its Volta architecture, which introduced Tensor Cores for the first time, which is a specialized hardware designed to dramatically accelerate deep learning workloads. This marked a significant pivot toward optimizing GPUs specifically for AI tasks. At the same time, Google announced its second-generation TPU (TPU v2), which supported both training and inference, signaling the start of intense competition over which platform could deliver the best deep learning performance.
In this context, the approach of patching TensorFlow with every release to arbitrarily limit GPU usage became increasingly difficult to maintain. Then, while working on the core technology development project for GPU cloud at IITP in 2018, we decided to tackle the problem at a lower layer. We developed a method that wraps the CUDA driver itself, making it difficult to manipulate from within the container. This allowed us to present a GPU that appears smaller inside the container and to restrict its usage according to that virtual size.
With this solution, we no longer had to patch TensorFlow every time, and we could immediately support new frameworks like PyTorch, which was starting to gain popularity at the time, without any additional effort. The main focus was on minimizing interference and conflicts between workloads in a cloud multi-tenant environment, and on enabling dynamic allocation of GPU resources each time a container is launched, rather than pre-allocating fixed partitions of GPU capacity. At the time, I didn’t fully realize the significance of this approach, but it later became the most important selling point of Lablup’s GPU virtualization technology.
The Transformer Era and the ChatGPT Moment
Between 2017 and 2019, the transformer architecture and the emergence of large language models (LLMs) marked what can be considered the most significant milestone in the history of deep learning. The transformer architecture, through its self-attention mechanism, enables the parallel learning and processing of long text information. The encoder refines and compresses the input information, while the decoder generates diverse outputs by referencing both the encoder’s results and its own previously generated outputs to predict the next token. As a result, "tokens"—the segmented units of information from human language, images, or audio—have risen to become the fundamental unit of information processing in AI models.
Transformer-based large language models did not attract widespread public attention from the outset. Of course, for those researching machine learning or working in specialized fields such as machine translation, these developments represented a significant change. However, to the general public, they seemed little more than a slightly more advanced version of the random sentence generators or simple chatbots like SimSimi that had previously been made as IRC bots. In essence, models that could predict and generate the next word a bit better than before.
In November 2022, ChatGPT was released and it reached 100 million users faster than any other product in internet history. By further training the GPT-3 model to provide 'friendly' and helpful answers in a question and answer format, ChatGPT became a service where users could ask the computer anything and receive expert-like responses.
The driving force behind Google’s dominance of the internet was its ability to help people find the information they wanted on the web better than anyone else. But now, the great appeal of ChatGPT was that users could get instant answers based on what it had learned, without having to click through search results themselves.
At the same time, a serious drawback was also pointed out: ChatGPT could not admit when it didn’t know something and often produced plausible but incorrect answers, a phenomenon known as hallucination.
 In 2024, AI finally received Nobel Prizes: John Hopfield and Geoffrey Hinton for neural network theory (Physics), and Demis Hassabis, John Jumper, and David Baker for AlphaFold’s breakthroughs in protein structure prediction (Chemistry). AlphaFold 2’s use of transformers modeled protein folding with unprecedented accuracy.
In 2024, AI finally received Nobel Prizes: John Hopfield and Geoffrey Hinton for neural network theory (Physics), and Demis Hassabis, John Jumper, and David Baker for AlphaFold’s breakthroughs in protein structure prediction (Chemistry). AlphaFold 2’s use of transformers modeled protein folding with unprecedented accuracy.
One of the most important criteria for awarding the Nobel Prize is not just the excellence of the research itself, but also the requirement that its benefits and impact on all humanity must be proven over a sufficient period of time. For example, the Physics Prize considered the long-term influence of the laureates’ research from the 1980s. This research contributed significantly to the development of the deep learning field. In contrast, the Chemistry Prize highlighted the impact of the laureates’ work that was first introduced with AlphaFold 1 in 2018. Their achievement fundamentally transformed research methodologies in chemistry in less than a decade.
When the film “Her” was released in 2013, its depiction of AI in 2025 seemed like pure science fiction. Now, AI agents and chatbots are part of everyday life, transforming how millions interact with technology. While technologies like the flying cars depicted in "Back to the Future’s" vision of 2015 have yet to mature enough for widespread adoption, AI chatbots and agent services have already transformed the lives of many people. Now, we live in a world where hundreds of millions of users, whether they like it or not, are directly or indirectly using transformer-based AI services.
Lablup was also able to ride this wave of change and experience rapid growth. Since 2020, when we first began to turn a profit, we have continued to grow steadily, thanks in part to the active AI infrastructure investments made by major domestic corporations and cloud companies following the emergence of large language models. As mentioned above, in the early days of the company, we expected that it would be difficult to survive on domestic sales alone, but this expectation was pleasantly proven wrong. Of course, just because we are doing well now does not guarantee future success, and for continued growth, it is still necessary to look toward overseas markets, which are overwhelmingly larger in scale.
Python Rocks!
 Python has also played an indispensable role in Lablup’s technical evolution. Some may remember that back in 2009, Python was still considered a niche language in Korea, featured at events like the “Alternative Language Festival” and used mainly by enthusiasts. Even today, Java continues to dominate large-scale web services and the SI (System Integration) market, largely due to the influence of the e-Government Framework and Spring. However, it has become increasingly common to see mid to large scale services built with Python, and in the field of AI workloads, Python now holds an unrivaled position.
Python has also played an indispensable role in Lablup’s technical evolution. Some may remember that back in 2009, Python was still considered a niche language in Korea, featured at events like the “Alternative Language Festival” and used mainly by enthusiasts. Even today, Java continues to dominate large-scale web services and the SI (System Integration) market, largely due to the influence of the e-Government Framework and Spring. However, it has become increasingly common to see mid to large scale services built with Python, and in the field of AI workloads, Python now holds an unrivaled position.
Between 2017 and 2020, deep learning frameworks consolidated around two major players: TensorFlow and PyTorch. The emergence of high-level APIs like Keras, which was later integrated into TensorFlow 2.0, and the release of Hugging Face’s transformers library helped establish Python as the definitive “AI programming language.” This shift not only accelerated AI research and development but also solidified Python’s central role in the broader technology landscape.
Riding this wave, both domestic and international PyCon (Python Conference) events experienced tremendous growth in scale and participation. Unfortunately, this momentum slowed during the COVID-19 pandemic, as in-person gatherings were suspended and many conferences shifted online or were postponed. Despite this setback, the period provided me with valuable opportunities to contribute to the Python community: while developing Sorna and Backend.AI, I encountered a range of challenges related to Python’s asyncio, which I then shared with the community and addressed by developing and releasing several open-source libraries.
Through these efforts, I was able to give back to the Python ecosystem and engage with a broader community of developers, even during a time when physical conferences and networking were limited.
During my undergraduate years, while developing the otl.kaist.ac.kr service which was launched in the spring semester of 2009 through the SPARCS club, I first discovered the joy of working with Python. This Django-based platform integrated with KAIST’s academic database to provide timetable creation, course catalog access, and lecture evaluation features.
In graduate school, I embedded a Python interpreter into the NBA (Network Balancing Act) framework, which I developed for my PhD thesis. This framework utilized Python as a domain-specific language (DSL) to automate RX/TX queue mappings for multiple network cards in complex NUMA environments. I also experimented with cross-build configurations for CUDA, OpenCL, and Intel Xeon Phi’s SCIF platform using Snakemake. Additionally, I leveraged Python’s asyncio to write network performance test scripts that minimized system resource usage while managing multi-node and multi-process workflows, further solidifying my positive experiences with the language.
Of course, after founding Lablup, I faced significant challenges with asyncio, but these experiences only deepened my understanding of its intricacies.
Through these experiences, Python has become an indispensable part of my development career. In fact, working with asyncio allowed me to share even more case studies with the community. In 2023, I had the opportunity to present a session at PyCon US, where I emphasized the need for enhanced debugging capabilities in asyncio. As a result, last year (2024), I was able to deliver a keynote at PyCon Korea as well. During that keynote, I took the time to reflect on the journey of my PyCon Korea talks, which I have given every year since 2015, dividing them into themes such as the founding story, lessons learned from working with asyncio, growing alongside enterprise customers, and the idea of making the world a better place through influential engineering.
Now, after attending this year’s GTC business trip and joining the WheelNext working group, I also plan to participate in the upcoming Packaging Summit at PyCon US. There, I hope to contribute to discussions on the next-generation wheel specification, aiming to make large-scale, accelerator-specific binary distribution easier. My goal is to pursue influential engineering that can help even more people.
The members of Lablup have also contributed to the community through many PyCon presentations over the years, and I believe we will continue to share a variety of stories in the future. I would like to take this opportunity to express my gratitude to the Korean Python community as well.
The Age of the AI Factory
 At NVIDIA GTC 2025, Jensen Huang likened the AI industry to manufacturing, where the goal is to produce the most tokens efficiently within finite resources, with the term “AI Factory.” Some customers now want to bill AI model services based on tokens generated, not just compute hours.
At NVIDIA GTC 2025, Jensen Huang likened the AI industry to manufacturing, where the goal is to produce the most tokens efficiently within finite resources, with the term “AI Factory.” Some customers now want to bill AI model services based on tokens generated, not just compute hours.
From a business management perspective, corporate activities are often divided into two main categories: cost centers and profit centers. Traditionally, initiatives such as building foundational models from scratch or establishing in-house AI research and development teams have been viewed primarily as cost centers, requiring significant investment in R&D for advanced technologies. While there have been some notable cases where these efforts led to models that could be successfully applied across various services, the reality is that, unless company leadership was exceptionally committed, it was difficult to realize sufficient tangible or intangible returns on the time and money invested. Sustaining such long-term investments was a major challenge for most organizations.
The concept of the AI Factory signifies that AI is shifting from being a cost center to becoming a profit center. Open language models have now reached a level of performance that makes them suitable for commercial products, and both hardware and software have become increasingly accessible. As a result, rather than developing entirely new models, it has become more important to adopt and implement widely recognized models. By integrating AI into existing products and services, users can accomplish more with greater flexibility, and in some cases, AI agents or chatbots themselves have become the core means of delivering services and generating revenue.
This transition means that as long as AI-powered services can generate profits, the scale of supporting infrastructure can continue to grow. If building more "factories" (i.e., scaling AI infrastructure) allows for the production of more "products" (tokens, predictions, or automated outputs) and thus greater revenue, the scale and nature of investment will fundamentally change. While AI is still widely seen as an area that consumes significant resources, the rapid pace of technological advancement and the continuous emergence of new AI-driven services suggest that, from an industry-wide perspective, reaching profitability is only a matter of time.
In the field of AIDC (AI Data Centers), as of 2024-2025, the biggest bottleneck is securing energy. The AIDCs currently operated by major U.S. tech companies are around 1 GW in scale, but the next-generation facilities being prepared are targeting around 5 GW. For example, the data center Elon Musk built in just a month by bringing in power trucks is about 200 MW in scale and is continuously expanding. In the next generation, we will likely see data centers in the 10–20 GW class. The question of where to source this much electricity is now becoming a major issue.
Already, a single node equipped with eight B200 GPUs consumes about 14 kW of power, and an NVL72 rack requires 130 kW. According to announcements at this year’s GTC, Vera Rubin-based NVL576 rack will reportedly consume a staggering 600 kW of power. Just two racks would already reach the megawatt level. Whether this trend will continue or alternatives will be sought remains to be seen, but if technologies like small modular reactors (SMRs) or fusion power become commercially available, they may become essential facilities for building and operating AIDCs above a certain scale.
From Agents to AGI
Strictly speaking, current AI technology cannot yet be said to possess general intelligence or consciousness like that of humans. Rather, it should be considered "weak AI" systems that can solve certain types of tasks, which were previously difficult to model or program deterministically, at a level equal to or even surpassing humans. In the AI industry, "strong AI" or AGI (Artificial General Intelligence) is still considered something of a holy grail that has yet to be achieved. Of course, predictions about when humanity might reach AGI vary greatly depending on the individual or the company.
Nevertheless, I believe that generative AI technology already holds immense potential in its current form, particularly because it has made natural human language a primary interface for interacting with computers. In the past, even if someone was able to perform "computational thinking," they still needed to express what they wanted to do in a programming language or at least in the form of a script to fully leverage a computer’s capabilities. (Of course, there have been countless no-code and workflow tools in the IT industry to make this process easier, but their flexibility is inevitably limited by what the creators have defined.) Now, however, we are seeing more and more agents that can understand and carry out what we want, even if our instructions are imprecise or informal.
One term that has been trending in the tech world is "vibe coding. Traditionally, generative AI in IDEs like VSCode, Cursor, or Zed has been used to provide advanced autocomplete features, not just completing symbols, but generating multiple lines of code at a time. In contrast, vibe coding refers to a new paradigm where the AI agent takes on most of the coding work, while the human primarily provides ideas or high-level designs.
Reflecting on the rapid pace of technological advancement and feeling that I am contributing to it, I find myself increasingly concerned about the evolving role of entry-level engineers. For senior or architect-level professionals with extensive development experience, these new AI agents are powerful assistants: they can quickly review, direct, and refine AI-generated code, or articulate precise requirements, allowing them to realize their ideas more efficiently. However, for students and junior engineers who still need to build up this experience, these AI tools can also feel like competitors threatening their job prospects. Yet, human lifespans are finite, and even if current senior engineers achieve explosive productivity gains with AI, they cannot do all the work forever. Therefore, it is crucial to consider how to support the learning and growth of today’s entry-level talent so they can effectively leverage AI in their careers. Personally, I believe that literacy and metacognition, including structuring and reflecting on thoughts, will be the most important for surviving and even thriving in a world where these AI technologies become ubiquitous.
Looking Ahead: The Next 10 Years
 From three founders to a team of 35, Lablup has reached a turning point where teamwork and organization matter more than individual effort. Sometimes it feels like I’m writing or debugging an organization instead of code. While the journey has been demanding, it’s far more rewarding than struggling for work or resources.
From three founders to a team of 35, Lablup has reached a turning point where teamwork and organization matter more than individual effort. Sometimes it feels like I’m writing or debugging an organization instead of code. While the journey has been demanding, it’s far more rewarding than struggling for work or resources.
Surviving and thriving for 10 years in the startup world, achieving profitability, and growing steadily was beyond our imagination at the start. After years in school and research, another decade at Lablup feels like a new adventure. While I sometimes miss hands-on coding, “vibe coding” means I can always jump back in when needed.
I wrote this post sometimes on a plane, sometimes in a cafe, and with help from ChatGPT, reflecting on the context of my work and the industry’s history. Thank you to everyone who has supported Lablup over the past decade. We look forward to sharing more exciting stories of growth in the years to come.