Engineering
Jun 29, 2025
Engineering
Backend.AI's approach to accessible AI utilization

Youngsook Song
Researcher
Jun 29, 2025
Engineering
Backend.AI's approach to accessible AI utilization
Youngsook Song
Researcher
Backend.AI: AI Infrastructure Operating Platform
1. Introduction
Backend.AI is an AI Infrastructure Operating Platform that manages the entire AI infrastructure, serving as the core technical achievement that realizes Lablup's vision of "Make AI Accessible." Recently, Lablup has been developing various product lines centered around Backend.AI to embrace a broader ecosystem, providing extensive support from research stages to production environments through AI model serving services such as 'PALI', 'PALI PALI', and 'PALANG' under the motto "What You Want Is What You Get." This article will examine the technical characteristics of Backend.AI's core technologies—fGPU virtualization and the Sokovan scheduler—as well as the key features of the PALI service suite.
Related Presentation: Backend.AI and AI Chip Harmony: All Tones of AI Hardware on One Stage!
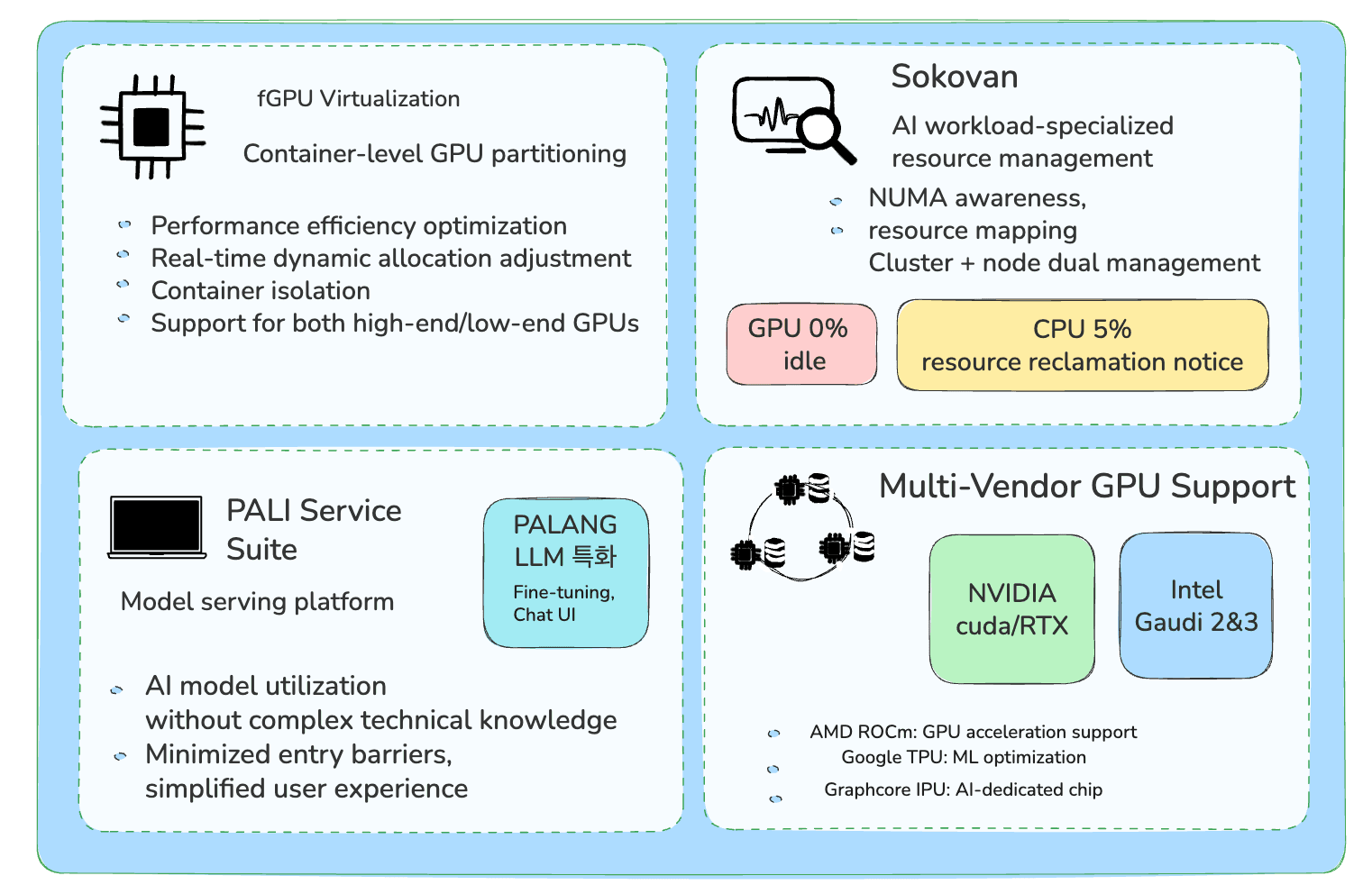
Figure 1: Backend.AI Core Technology Overview
2. Resource Efficiency
2.1. GPU Virtualization Technology: fGPU
GPU virtualization technology is a highly technical domain, with each approach having its unique design philosophy and use cases. While NVIDIA's MIG and MPS are both solutions that enable GPU sharing, their actual operation methods and suitable usage scenarios differ significantly. Backend.AI's proprietary technology, fGPU (Container-level GPU virtualization), adopts a container-level partitioning approach that allows sharing a single GPU by dividing it in multi-GPU environments or allocating multiple GPUs to a single container.
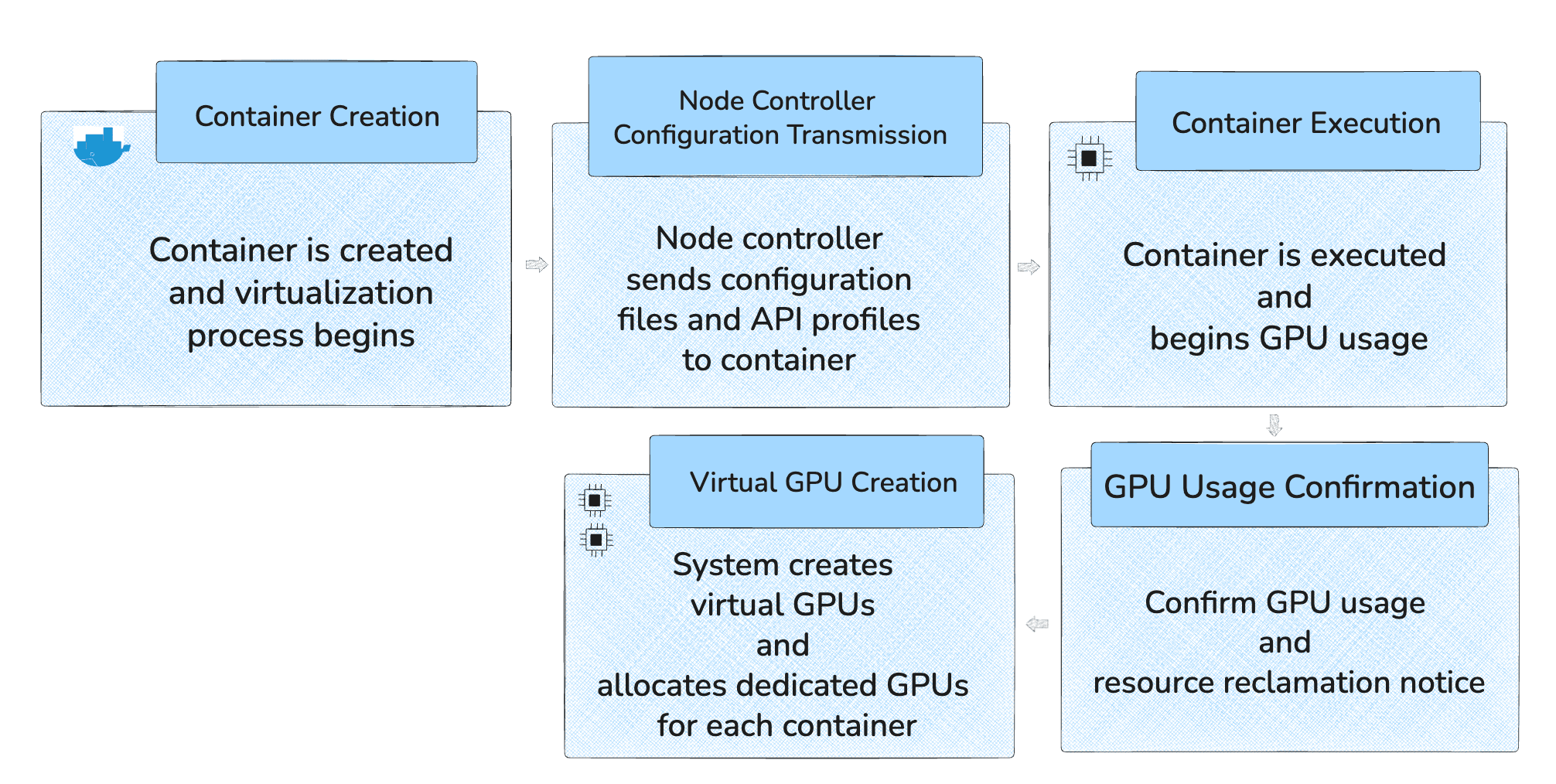
Figure 2: Container-level GPU Virtualization Process Flow
To explain container-based GPU virtualization simply: when a container is created, a management system called the node controller sends configuration files and API profiles containing information about "how much GPU can be used" to the container. Then, when the container runs, it checks and regulates whenever a program tries to use the GPU. Finally, through system commands, it creates virtual GPUs so that each container operates as if it has its own dedicated GPU. This partitioning method ensures that multiple users can safely share a single GPU. To use an analogy, it's like combining independent households into a single building complex. This allows each household to maintain its independent lifestyle while flexibly utilizing the space within the building.
*Reference Materials: GPU Allocation per Container through GPU Virtualization
Lablup's container-level GPU partitioning virtualization technology is a high-level solution that combines the flexibility of logical partitioning with robust process isolation mechanisms, securing both performance and security simultaneously. Additionally, it supports not only NVIDIA's data center GPU lineup but also consumer-level GPUs like the RTX series, providing broad versatility compared to technologies dependent on specific GPUs.
To verify the effectiveness of GPU virtualization, let's assume operating a Llama-6B model on various GPU configurations. An administrator can partition an H100 80GB into 10 fGPUs with 8GB memory each, allowing the use of only necessary portions rather than occupying the entire H100 80GB single GPU. Running multiple tasks simultaneously using fGPU can increase overall GPU memory utilization.
If testing with one model before adding experiments, it would be necessary to establish a GPU selection strategy by model size. For this, small models of 7B and below could benefit from fGPU efficiency in multi-tenant environments. Theoretically, when allocating a Gemma-2B model to one fGPU, GPU memory utilization is 60% (41% utilization with 4-bit quantization), whereas allocating an entire RTX 4090 results in memory utilization of approximately 17-26% depending on the model and quantization method. Conversely, medium-sized models in the 13B-30B range might be better suited for high-performance single GPUs like RTX 4090 in single-task environments.
These differences become clear based on usage patterns. In multi-tenant environments like AI API services where various users utilize different small models, fGPU is optimal. Each user can independently operate various models such as GPT-2 (1.5B), BERT (340M), T5-small (60M) while efficiently sharing a single H100. Conversely, for dedicated services like proprietary chatbot services that intensively use a single model like Llama-2-13B, two RTX 4090s might be a better choice.
2.2 Resource Allocation and Recovery Scheduling Function: Sokovan Performance Optimization
2.2.1. Supporting All GPUs Available in the Market
Sokovan is Lablup's multi-level scheduling system, designed to simplify and optimize the management of complex AI infrastructure. Its architecture features a two-tiered structure: a high-level cluster manager and low-level node agents. At the top level, the cluster manager oversees container scheduling for the entire cluster. At the node level, an agent on each GPU node performs detailed resource management. These agents are responsible for mapping containers to specific devices, reporting hardware capacity and topology, and supporting various compute plugins, including NVIDIA CUDA, Intel Gaudi, AMD ROCm, Google TPU, and Graphcore IPU. The impact of this system architecture on AI workload performance is best understood with an analogy. Think of a CPU accessing physically close local memory. This is like getting a glass of water from your own refrigerator—the action is quick and efficient because it happens within your home. However, if the CPU needs to access remote memory located far away, it's like finding your refrigerator empty and having to go next door to borrow water. The process is much slower because of the extra distance you have to travel. Similarly, Sokovan optimizes performance by ensuring compute and data resources are as close to each other as possible.

Figure 3: Backend.AI's Resource Optimization Analogy
Unlike general container orchestration tools like Kubernetes that focus on versatility, Backend.AI's scheduler makes optimal resource placement decisions considering AI workload characteristics. Backend.AI's scheduler significantly improves AI task performance by positioning related components physically close together, reducing the time and distance data travels within the system.
Backend.AI's design philosophy is "maximizing efficiency without losing flexibility." According to this philosophy, Backend.AI has two characteristics. First, securing flexible computing session methods, and second, maximizing efficiency through customized schedulers.
To secure flexible computing sessions, Backend.AI doesn't use the Pod concept. It's implemented to create containers as needed without predetermined Pods. This treats containers like volatile processes while ensuring data persistence through volume mounts. Additionally, for efficient situational use, Backend.AI allows selection of FIFO, DRF (Dominant Resource Fairness algorithm), and user-defined algorithms according to circumstances.
In addition to these features, Backend.AI's strength lies in being software that supports multi-tenancy. The software is designed so that a single software instance can provide services to multiple tenants, enabling multiple users to access through a single instance. This approach enables public SaaS services and allows flexible data sharing with user customization and stable service scaling by separating users and projects from Linux system accounts.
2.2.2. Not Dependent on a Single Company and Supporting All Types of Hardware, Containers, and Devices
Sokovan's system architecture operates divided into cluster level and node level. When the upper-level cluster manager decides overall container placement, lower-level node agents handle detailed resource management at each GPU node. These agents support various hardware including NVIDIA CUDA, Intel Gaudi, AMD ROCm, Google TPU, Graphcore IPU, and connect hardware with containers and devices.
Sokovan's core strength lies in NUMA-aware resource mapping. Therefore, it understands computer hardware memory structure to efficiently arrange CPU-GPU-RAM. It maintains uniform data transfer speeds between GPUs and allocates appropriate CPU cores to GPUs in different memory regions. It also extends fair resource distribution algorithms (DRF) to GPUs, fairly distributing resources even in clusters with mixed GPU types.

Figure 4: NUMA-aware Resource Mapping Design
Second, the automatic resource recovery system enhances operational efficiency. The system automatically recovers resources when GPU utilization is 0% or CPU utilization is below 5% for more than 10 minutes, when there's no network activity for 1 hour, or when 12 hours have passed since session start. Particularly for batch jobs, resources are immediately released when programs end, allowing other users to utilize them. Additionally, idle resources are automatically recovered through various criteria including automatic resource allocation based on maximum resource capacity settings per user/group, utilization (GPU utilization 0%, CPU utilization below 5% for more than 10 minutes), interaction (no network traffic for 1 hour), and usage time (12 hours elapsed since session start). This prevents situations where arbitrary users hold sessions without utilizing them, preventing other users from utilizing resources. For batch sessions and pipeline work, it has a smart management system that automatically releases resources when main programs terminate.

Figure 5: Example of Resource Recovery Applied in Operating Services
To help understand Sokovan, comparing Sokovan with existing orchestrators can be summarized as follows:
| Characteristic | Sokovan | Kubernetes | Slurm |
|---|---|---|---|
| Design Focus | Optimized for AI workloads | Container workloads | HPC workloads |
| Scalability | Single node to cluster | Cluster-centric | Cluster-centric |
| AI-specific Features | NUMA awareness, GPU optimization, model serving | Limited basic support | Limited GPU support |
2.2.3. Deployment Flexibility: Consistent AI Experience Anywhere

<그림 6> Figure 6: On-premises Hybrid Support Example
A key differentiator for Backend.AI is its deployment flexibility, which ensures a consistent user experience across diverse environments. For on-premises deployments, Backend.AI meets strict enterprise security policies and compliance requirements while seamlessly integrating with existing data center infrastructure. This makes it ideal for organizations needing to securely manage workloads with data sovereignty or high-security considerations. In public cloud environments, it can be easily deployed on major platforms like AWS, Azure, GCP, and Naver Cloud, integrating natively with each provider's services.
In a hybrid environment, workloads can move freely between the cloud and on-premises, enabling optimal decisions on cost and performance. This flexibility allows for strategic resource allocation—for instance, processing sensitive data on-premises while leveraging the cloud for scalability. Backend.AI unifies these diverse environments under a single management interface, significantly reducing operational complexity and boosting efficiency. When viewed from the perspective of the complete AI infrastructure lifecycle, from provisioning to monitoring, these functions are illustrated in the diagram below."

Figure 7: AI Infrastructure Lifecycle Management
First, Provisioning Adapters automatically allocate and configure new resources, such as servers and storage. Through these adapters, the necessary infrastructure is rapidly provisioned in clouds or data centers. The Cloud Service Provider (CSP) API layer then connects with various cloud environments like OpenStack, AWS, Azure, and GCP to proceed with deployment. This layer integrates the unique features of each cloud service into Backend.AI, ensuring a consistent user experience regardless of the environment. Once resources are allocated, the Hardware Layout Awareness feature analyzes the physical hardware configuration and topology. It identifies the physical relationships between GPUs, CPUs, memory, and network interfaces to determine optimal resource placement for AI workloads. For example, it selects a placement that minimizes the physical distance between data and compute devices, thereby reducing data transfer latency. Finally, after all resources are deployed and workloads are running, the Hardware Monitoring system continuously observes the environment. This system tracks resource utilization, temperature, power consumption, and error states in real-time. When an anomaly is detected, it can immediately send a notification, initiate an automated response, or alert an administrator, ensuring constant system stability and performance.
3. User-Centric Model Serving Services Focused on Change
While Lablup has traditionally focused on B2B services that empower AI developers and enhance organizational productivity, the company is now expanding its portfolio to support individual developers. At the forefront of this initiative are three new AI model serving services—"PALI," "PALI PALI," and "PALANG"—along with the chatbot interface, Talkativot. These services are designed to lower the barriers to using AI models and to simplify the overall user experience.
3.1. PALI: Model Serving
'PALI (Performant AI Launcher)' is a model serving platform that enables easy and fast deployment of pre-trained AI models, supporting easy system construction and operation even in on-premises and air-gapped environments. It particularly offers advantages including service portal and endpoint provision functionality premised on application use, as well as integrated management of simulation functionality and license management from NIM in one place. Users can quickly serve models without complex CLI or difficult processes and easily receive and utilize service endpoints.

Figure 8: Model Service Flow
| Category | Definition | Features | Partner or Product Examples |
|---|---|---|---|
| PALI | AI launcher for AI model inference | Combination of Backend AI's model player and model store | Support for various pre-trained models (Gemma 2, Qwen, Llama 2, Llama 3, etc.) |

Figure 9: PALI Model Store
PALI supports not only self-provided models but also various third-party models from Hugging Face, NVIDIA NIM, Kaggle, etc. The model catalog (model store) presents various models like Llama and Gemma in intuitive card format, and users can simply execute inference services by clicking model cards.
It features the ability to run latest generative AI models like language models and image generation models as easily as apps, specializing in inference functionality. It particularly provides simple license management and simulation functionality, configured so that artists, researchers without development knowledge, and general users wanting image processing can easily experience and utilize various AI models.
3.2. PALANG: Language Model Specialized Platform
'PALANG' is a platform specialized for language model (LLM) utilization, with fine-tuning and chat interface (Talkativot) added to basic model serving functionality.

Figure 10: Chat Interface Example
| Category | Definition | Features | Partner or Product Examples |
|---|---|---|---|
| PALANG | Platform with language model management tools added to PALI functionality. PALI + LANGuage model. | Basic model inference (play) functionality provided (same as PALI). Fine-tuning functionality for pre-trained models added (FastTrack planned). | Chatbot comparison interface (Talkativot). Language model fine-tuning like Llama |
PALANG is a platform where users can easily turn customized language models into services. It provides functionality including fine-tuning through natural language interfaces, model import through text commands, and comparison and utilization of fine-tuned models through chatbot interface (Talkativot).
*Related Presentation: [Track3_6] I'm Getting Dizzy!: PALI, PALI PALI and PALANG - Hwang Eun-jin (Lablup)
4. Conclusion: AI Infrastructure Feature Summary
Backend.AI provides an integrated platform that enables companies to efficiently develop, deploy, and manage ML models based on four core technologies: fGPU virtualization, Sokovan scheduler, PALI service suite, and multi-vendor GPU support. Through this architecture, complex AI workflows can be simplified and consistent services can be implemented across various environments.
Particularly, performance efficiency optimization through container-level GPU partitioning and real-time dynamic allocation adjustment, along with NUMA awareness and resource mapping technology for AI workload-specific resource management, constitute Backend.AI's differentiated competitive advantages. It also possesses PALI service suite technology that enables AI model utilization without complex technical knowledge and technical capabilities supporting various vendor GPUs and AI accelerators.

Figure 11: Infrastructure Feature Summary
AI infrastructure challenges will certainly become more complex in the future. As models become larger and learning and inference become generalized, workload management and coordination across multiple devices is becoming a core challenge. It will particularly help companies operating large-scale ML workloads, companies pursuing multi-cloud strategies, companies using hybrid environments combining on-premises and cloud, and providing flexibility to start small and expand as needed. Complete functionality can be implemented even on single servers or small clusters, and when business scale grows, nodes can be added to expand to thousands of units. Most importantly, resources can be added without affecting existing services, supporting stable and continuous AI service operation. Going forward, Backend.AI aims to contribute to building an ecosystem where more companies and developers can enjoy the benefits of AI technology under the vision of 'Make AI Accessible.'