Nov 12, 2025
Engineering
Training an MCP Sidecar Model to Boost LLM Versatility

Junbum Lee
Researcher
Nov 12, 2025
Engineering
Training an MCP Sidecar Model to Boost LLM Versatility
Junbum Lee
Researcher
The Era Where Everyone Talks About Agents
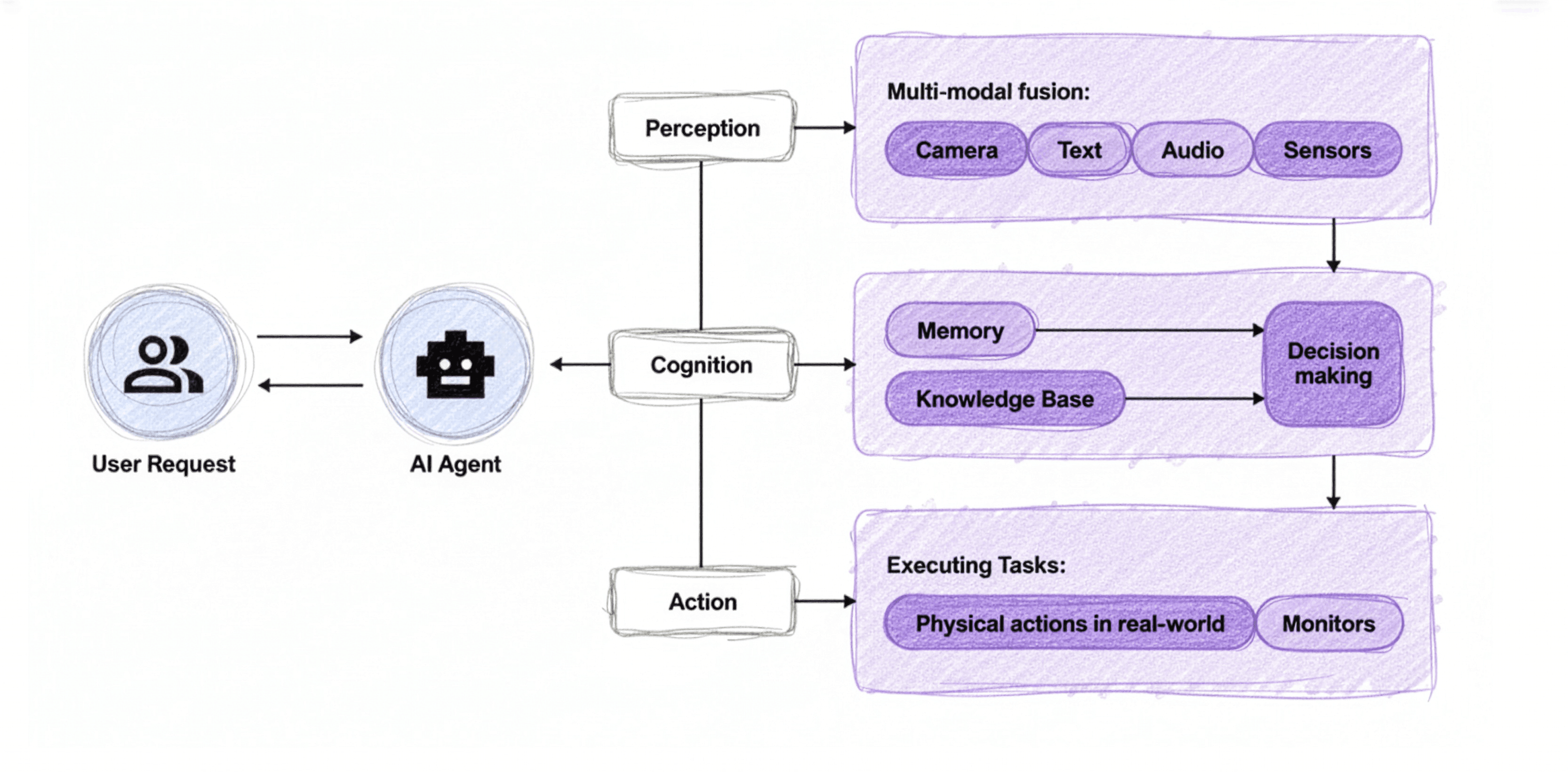
Looking at recent AI technology trends, it's no exaggeration to say we're in the Age of Agents—everyone is talking about and developing AI agents. Simply put, an AI agent is a system that receives user requests, interacts with specific tools (websites, code, APIs, etc.) to accomplish tasks, and returns results to the user. At the heart of agent technology is a key concept proposed by Anthropic: MCP (Model Context Protocol). MCP is a protocol designed to standardize interactions between various AI applications and data sources/tools, providing a unified user experience. MCP has become such a core technology in the agent ecosystem that OpenAI recently announced full MCP support in ChatGPT.
But this raises a fundamental question: Can all large language models (LLMs) properly understand and utilize MCP? Models developed alongside MCP, such as Anthropic’s Claude, naturally excel at it. However, countless open-source LLMs like Llama and Gemma were released without specific training data for MCP. Fine-tuning them on expensive GPUs every time a new model emerges is simply not practical.
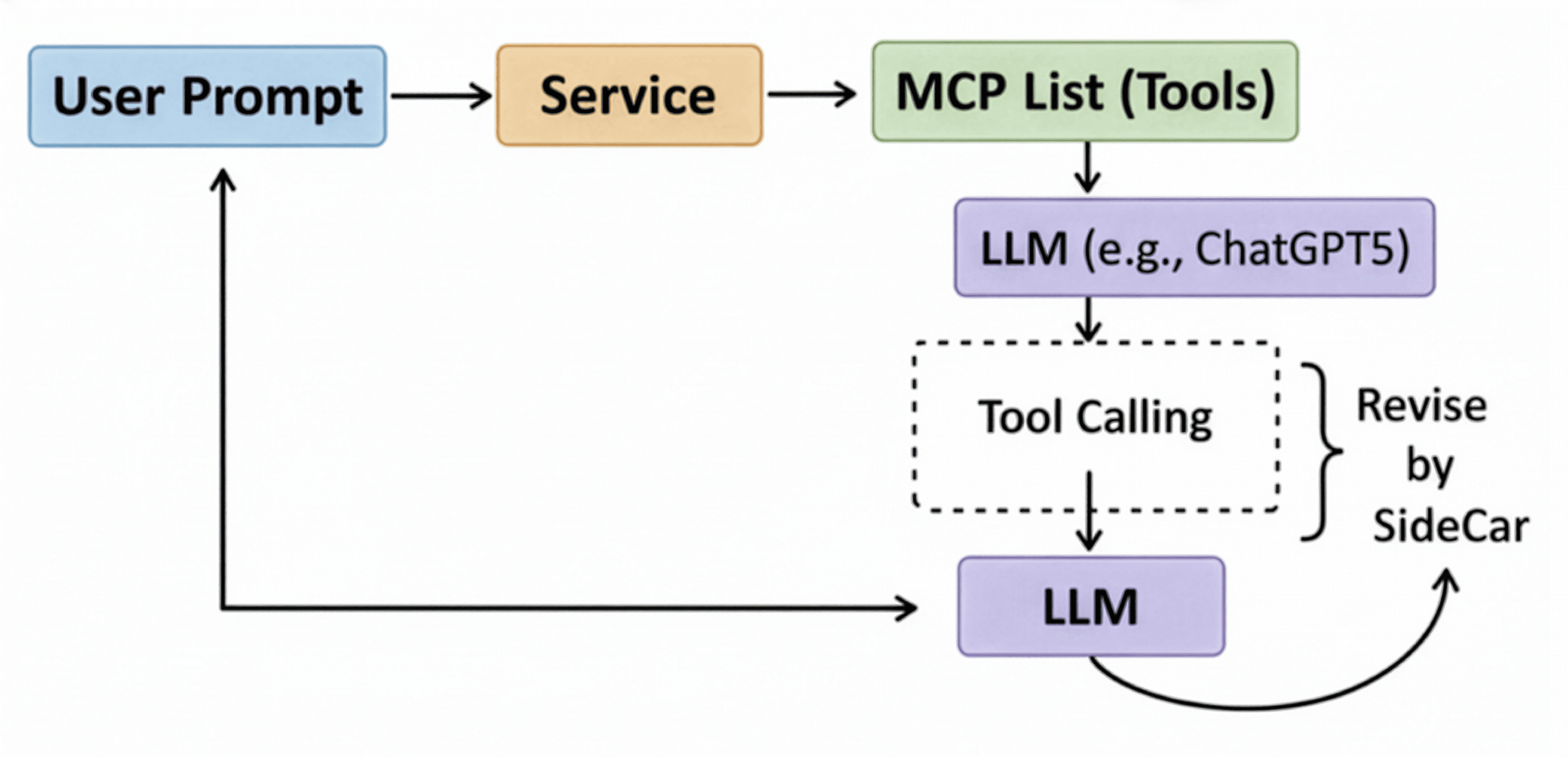
To solve this, we decided to develop a small language model (sLM). Rather than modifying powerful LLMs directly, this sidecar model serves as an assistant that “revises” an LLM’s output to conform to MCP format. This allows any LLM to be integrated into MCP-based agent systems at minimal cost.
In this post, we’ll share our journey in detail—from conceptualization to evaluation metrics, data generation, and the many trials and errors that eventually led us to reinforcement learning.
What Makes MCP Different From Traditional Function Calling?
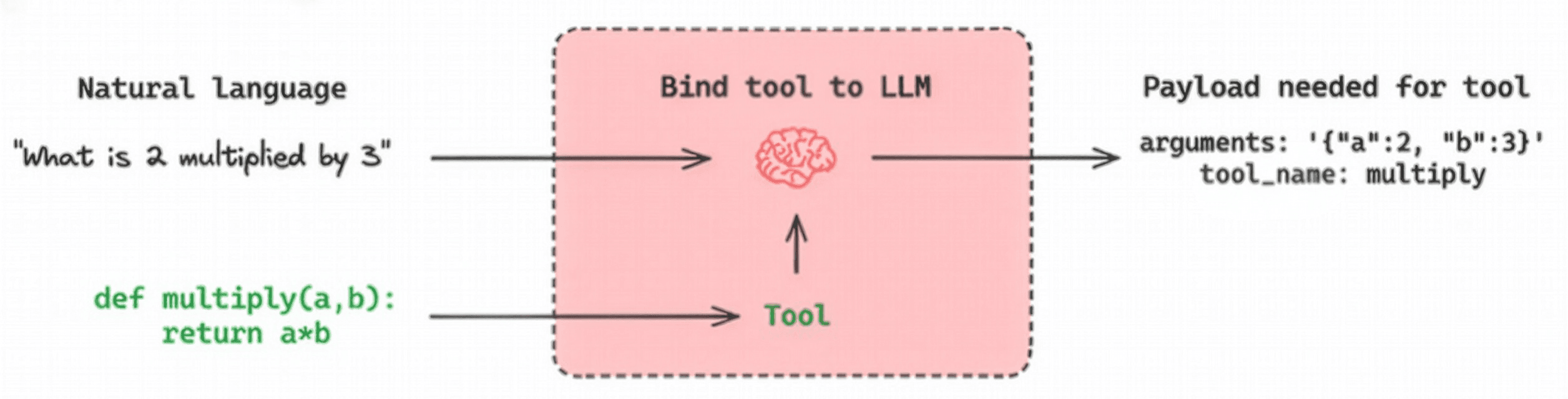
To understand MCP, we first need to compare it with traditional “function calling” or “tool calling.”
Function calling enables an LLM to interpret natural-language requests, select the appropriate function from predefined options, and return the function call in JSON format with the necessary arguments. Rather than executing code directly, the LLM provides the structured information needed for execution.
In contrast, MCP is a more structured and extended protocol. As shown below, MCP introduces several additional steps:
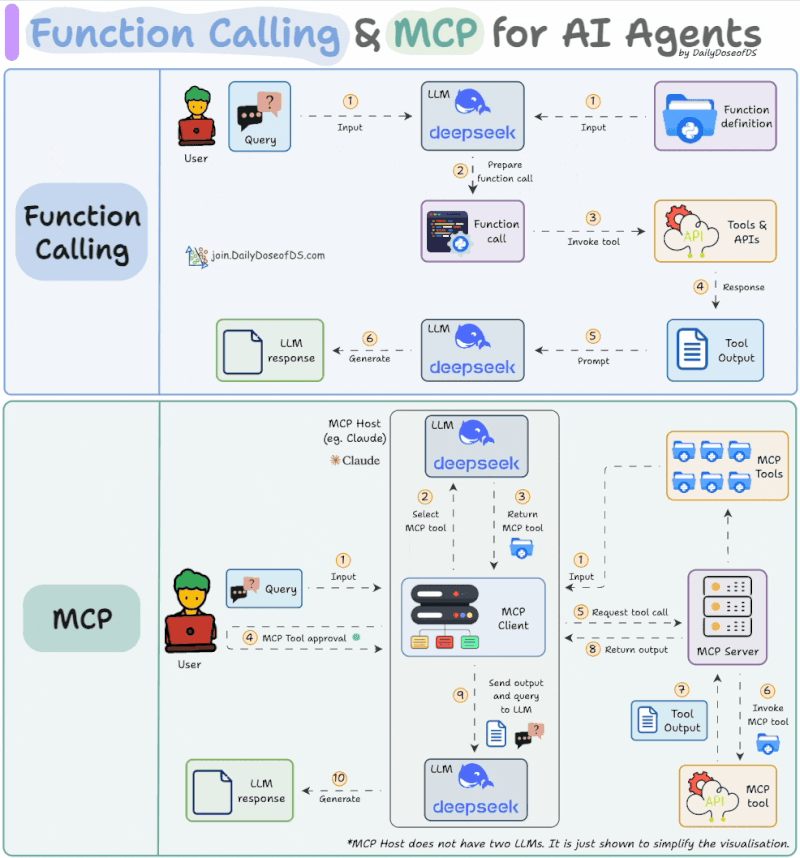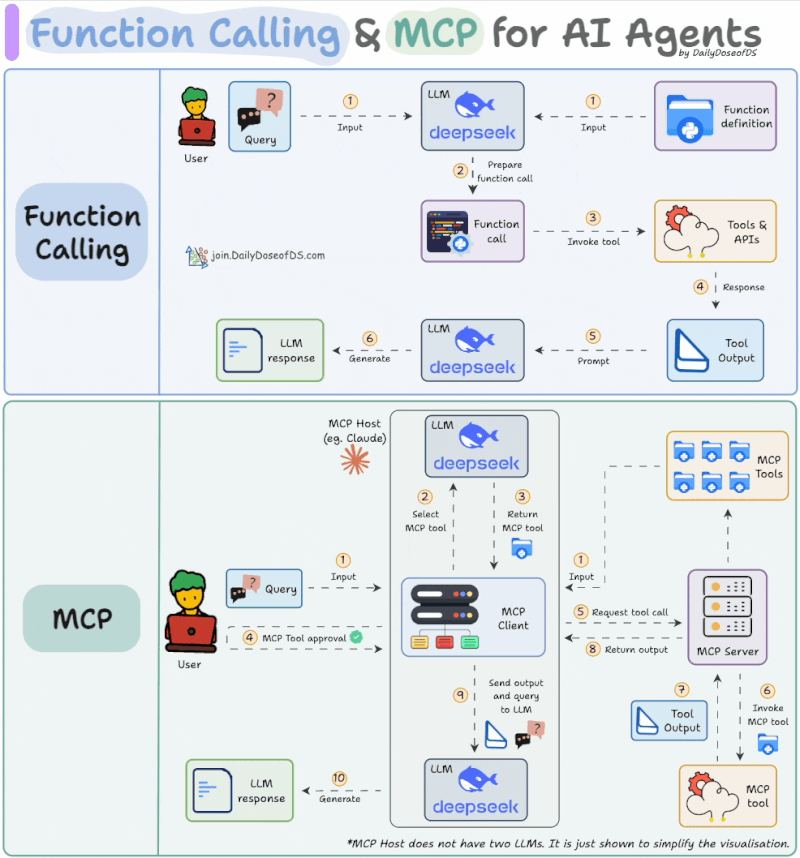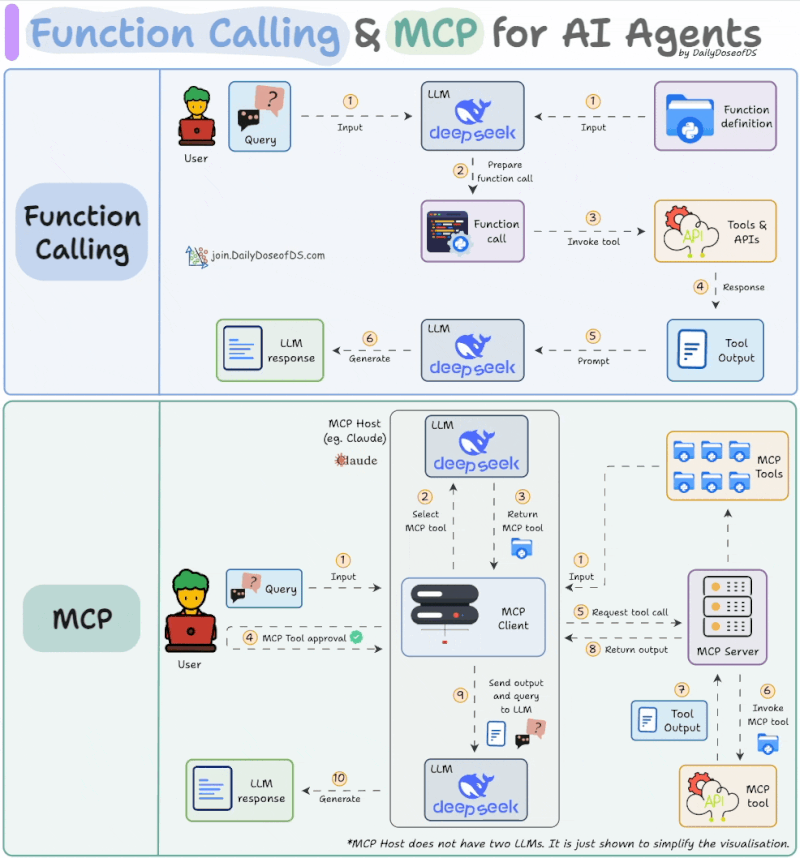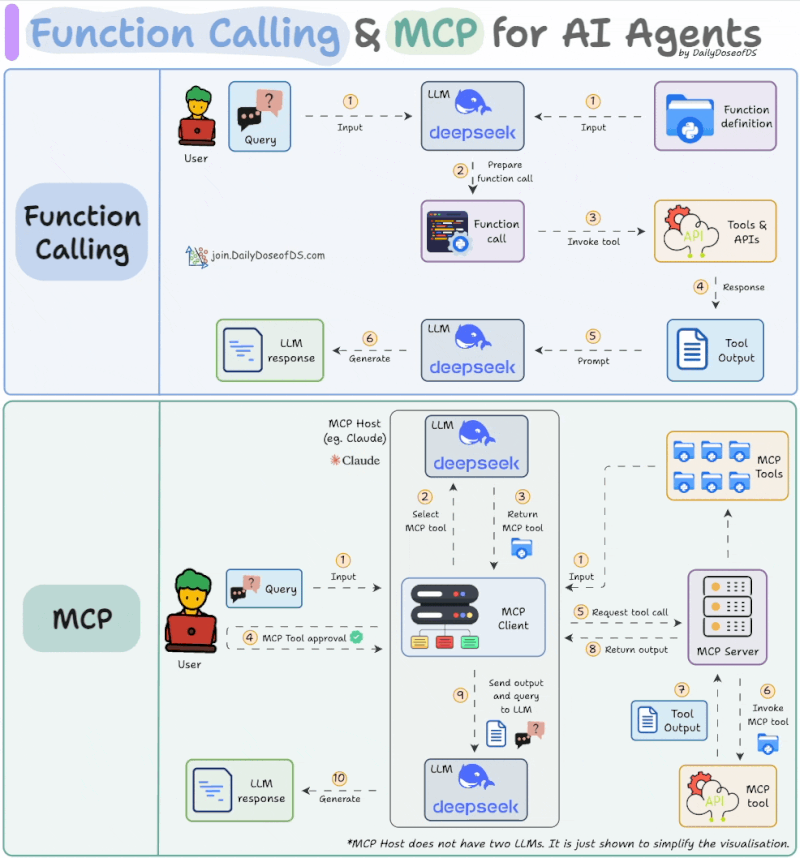
Source: https://www.linkedin.com/feed/update/urn:li:activity:7319639412240261120/
- Tool Discovery: Retrieve a list of available MCP tools.
- Tool Selection: The LLM selects specific tools from MCP servers to address the user’s request.
- User Approval: Explicit user consent is required before invoking the selected tool.
- Tool Execution & Result Return: Once approved, the MCP server tool is executed and results are used to generate the final response.
The key differences are the addition of the user approval step and a standardized protocol for retrieving tool lists. Of course, in tools like Claude Code, enabling “Auto Accept” mode with Shift+Tab removes manual approval, making the experience closer to traditional function calling.
Measuring Success: Performance Evaluation With MCP-Bench
Before developing the model, we needed a clear definition of “success.” Without objective performance criteria, our development would lack direction. We chose MCP-Bench, released around the time we started this work.
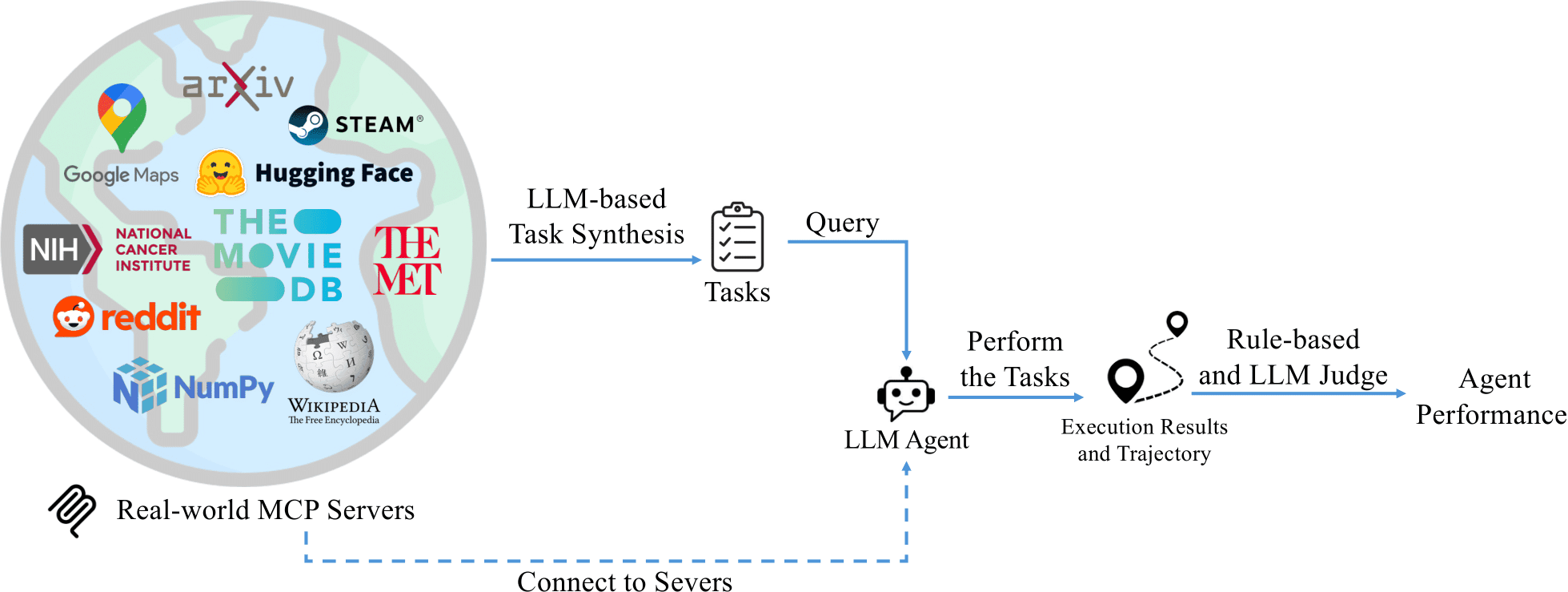 Image source: https://github.com/Accenture/mcp-bench
Image source: https://github.com/Accenture/mcp-bench
MCP-Bench is a benchmark that evaluates LLM agent performance across 28 MCP servers, including Google Maps, Wikipedia, and Steam. It evaluates models along two major axes:
-
Rule-based Evaluation : Checks how well the model adheres to technical specifications.
⦁ Schema Understanding : Verifies whether valid tool names are used, schema conventions are followed, and server calls succeed.
-
LLM as a Judge Evaluation : Measures contextual understanding and task efficiency. ⦁ Contextual Understanding : A stronger LLM (e.g., GPT-4) judges whether the given task was completed successfully, appropriate tools were used without unnecessary calls, and multi-tool workflows were planned and executed efficiently. The MCP-Bench leaderboard results were:
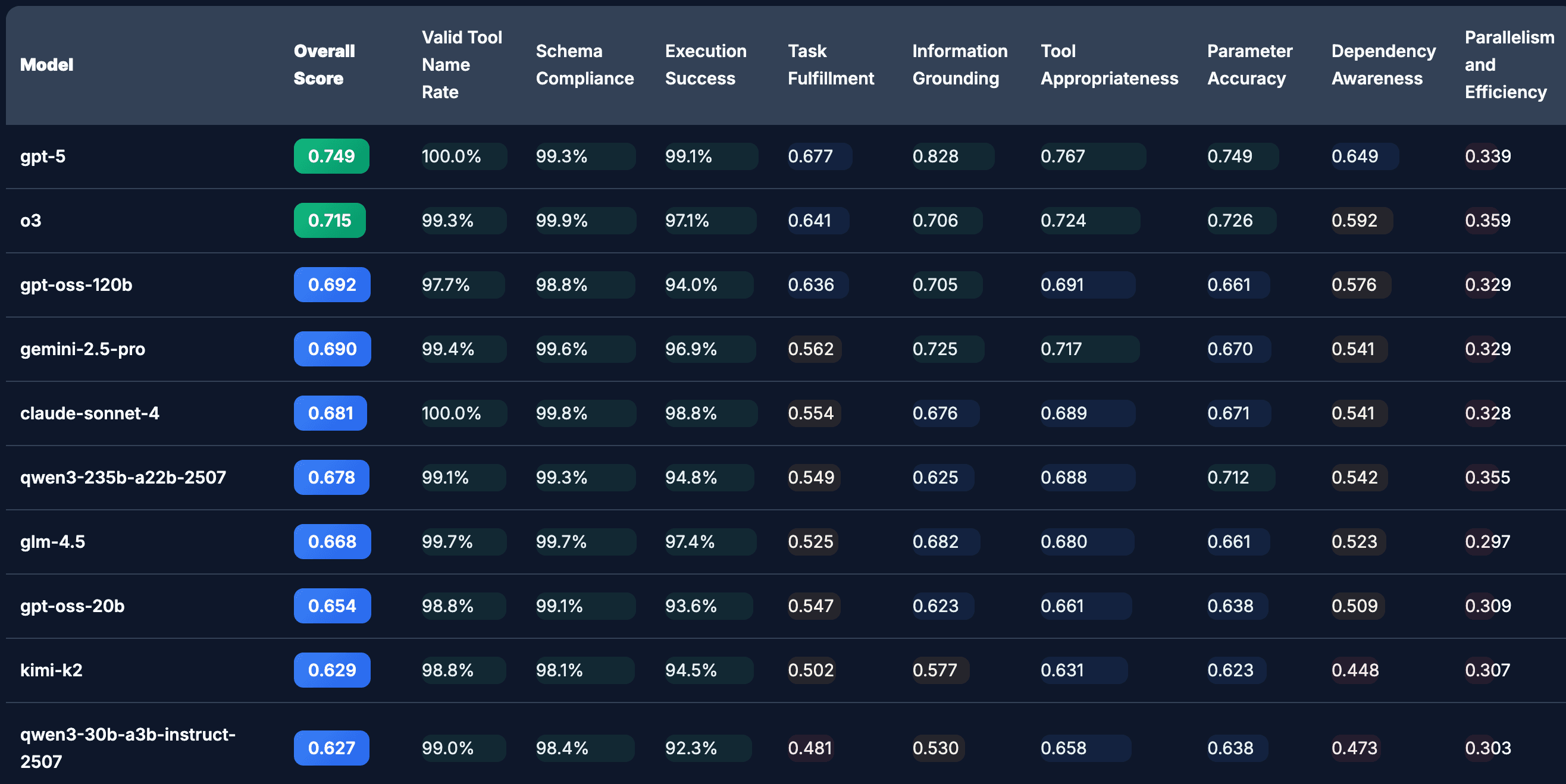 Source: https://huggingface.co/spaces/mcpbench/mcp-bench
Source: https://huggingface.co/spaces/mcpbench/mcp-bench
As expected, GPT-5 ranks at the top, while the open-source models we aimed to improve—Gemma-3-27B and Llama-3.1-8B—had significantly lower scores. Our goal was to use a sidecar model to elevate these lower-performing models to near–top-tier performance.
Building the Training Pipeline: A Challenging Journey
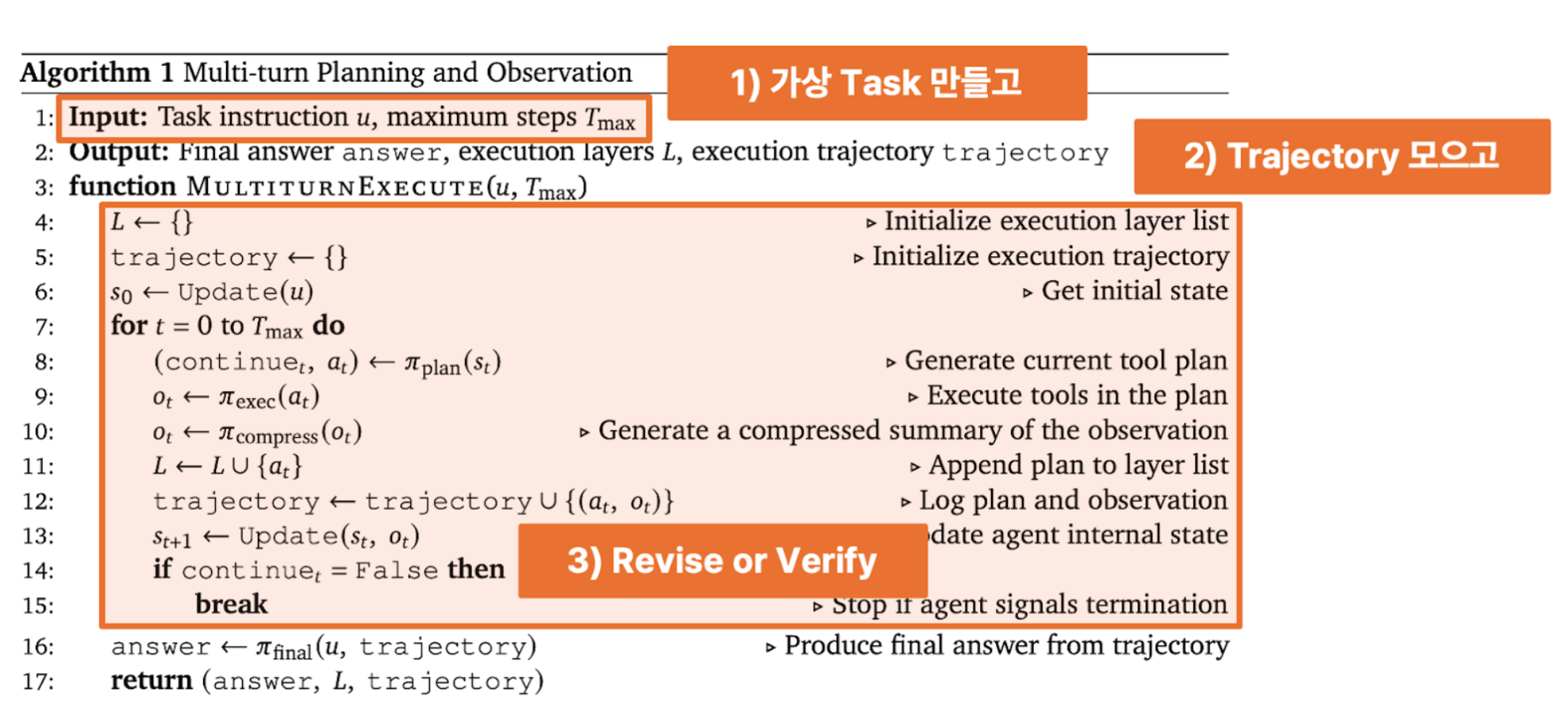 Source: https://www.arxiv.org/pdf/2508.20453
Source: https://www.arxiv.org/pdf/2508.20453
Stage 1: Training Data Generation
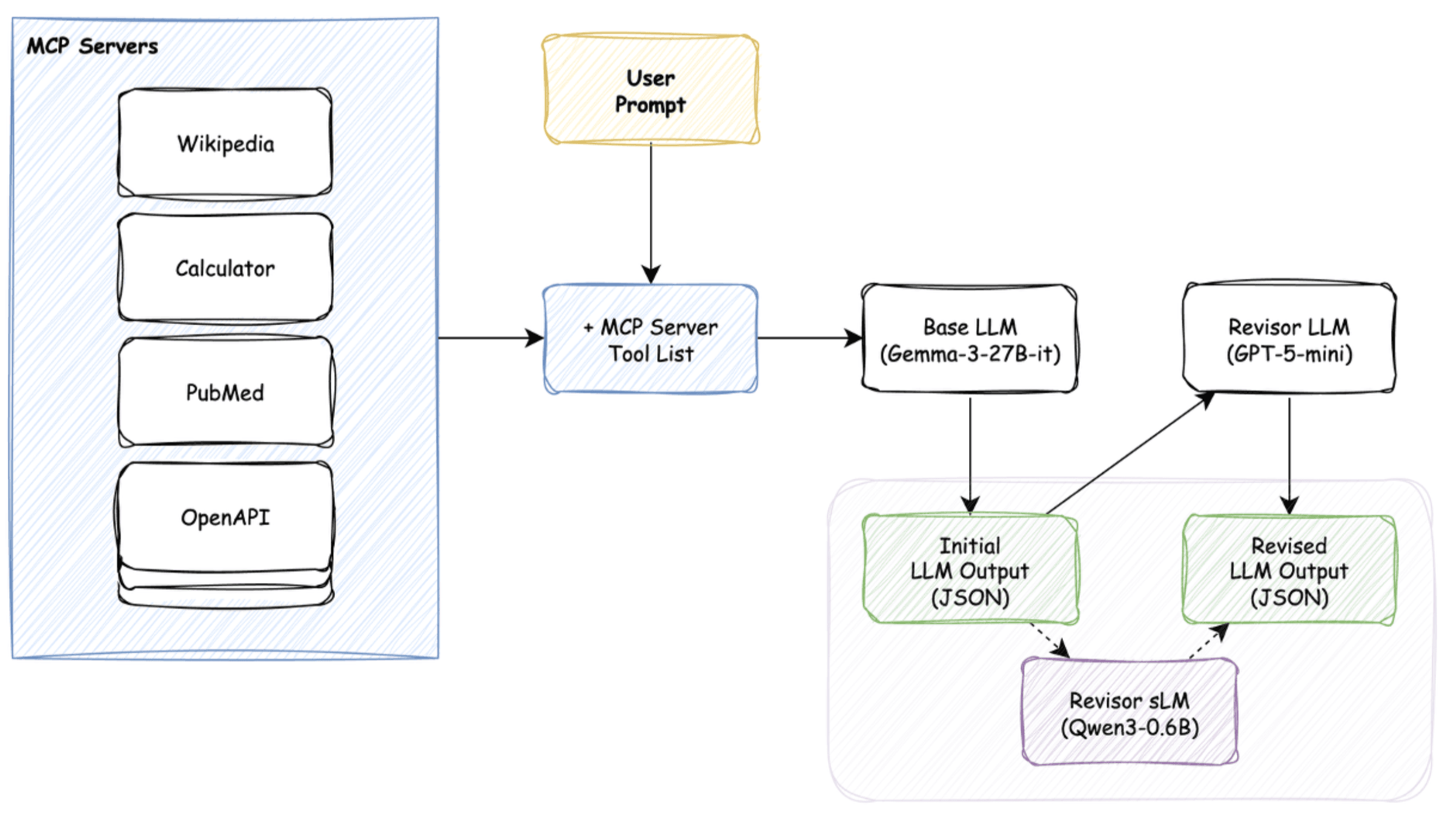
MCP-Bench provides only evaluation data, so we needed to create a separate training dataset. Using evaluation data for training would result in test set contamination and invalidate our measurements. We used synthetic data generation with a strong model like GPT-5. The workflow:
-
Input: Provide an MCP server and its tool specifications.
-
Generation: GPT-5 generates complex user scenarios requiring those tools.
-
Golden Label: It simultaneously produces optimal tool calls as ground truth.
These (scenario, tool-call) pairs served as training data for our sidecar model.
Stage 2: First Attempt — Supervised Fine-Tuning and Why It Failed
Our first approach was standard supervised fine-tuning (SFT):
- Feed synthetic prompts to a base LLM (e.g., Gemma-3-27B) to obtain imperfect JSON.
- Feed this JSON to a more powerful reviser model (e.g., GPT-5-mini) to get corrected JSON.
- Train the sidecar sLM using supervised fine-tuning (SFT), with the Initial LLM Output as input and the Revised LLM Output as the target.
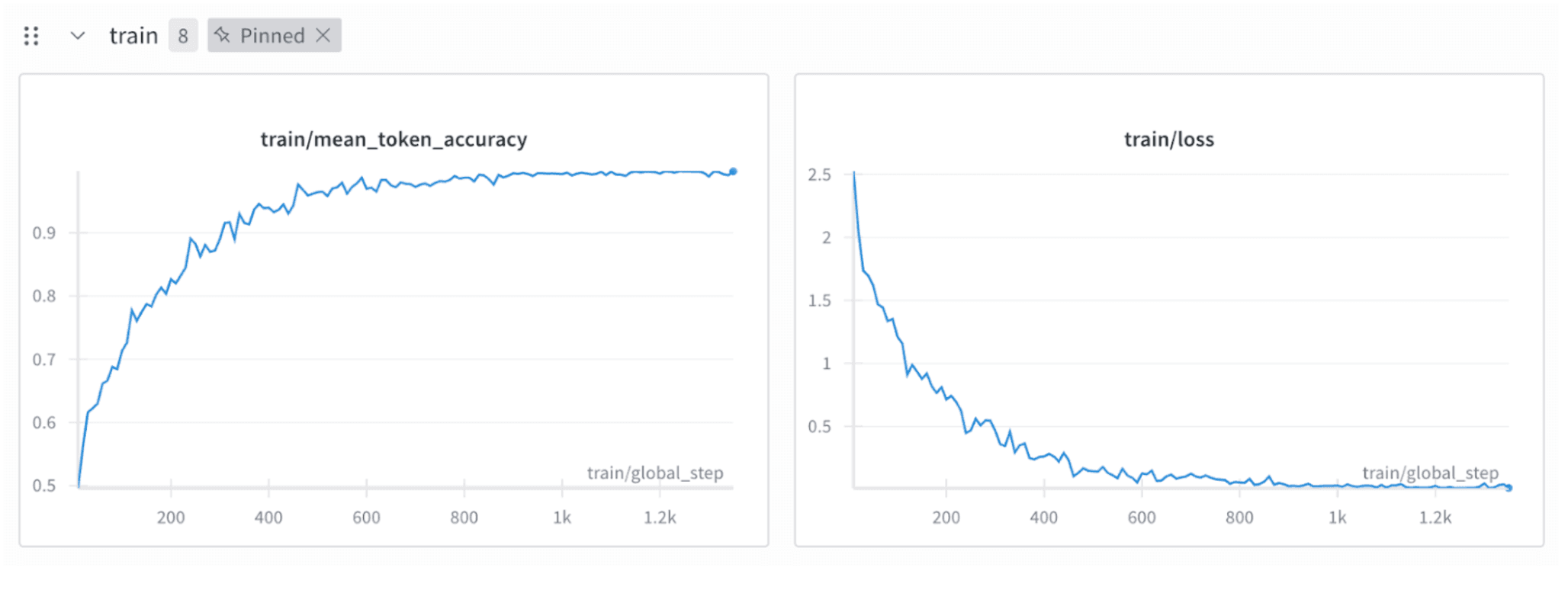
But the results were poor. The loss decreased too smoothly—an indicator that something was wrong.
The problem was that the imperfect output and revised output were too similar. Modern open-source LLMs still produce mostly valid JSON, resulting in over 90% token overlap. The easiest way for the sLM to reduce loss was simply to copy the input—not learn how to revise it.
The model learned to copy, not correct.
Stage 3: Second Attempt — Reinforcement Learning (RL)
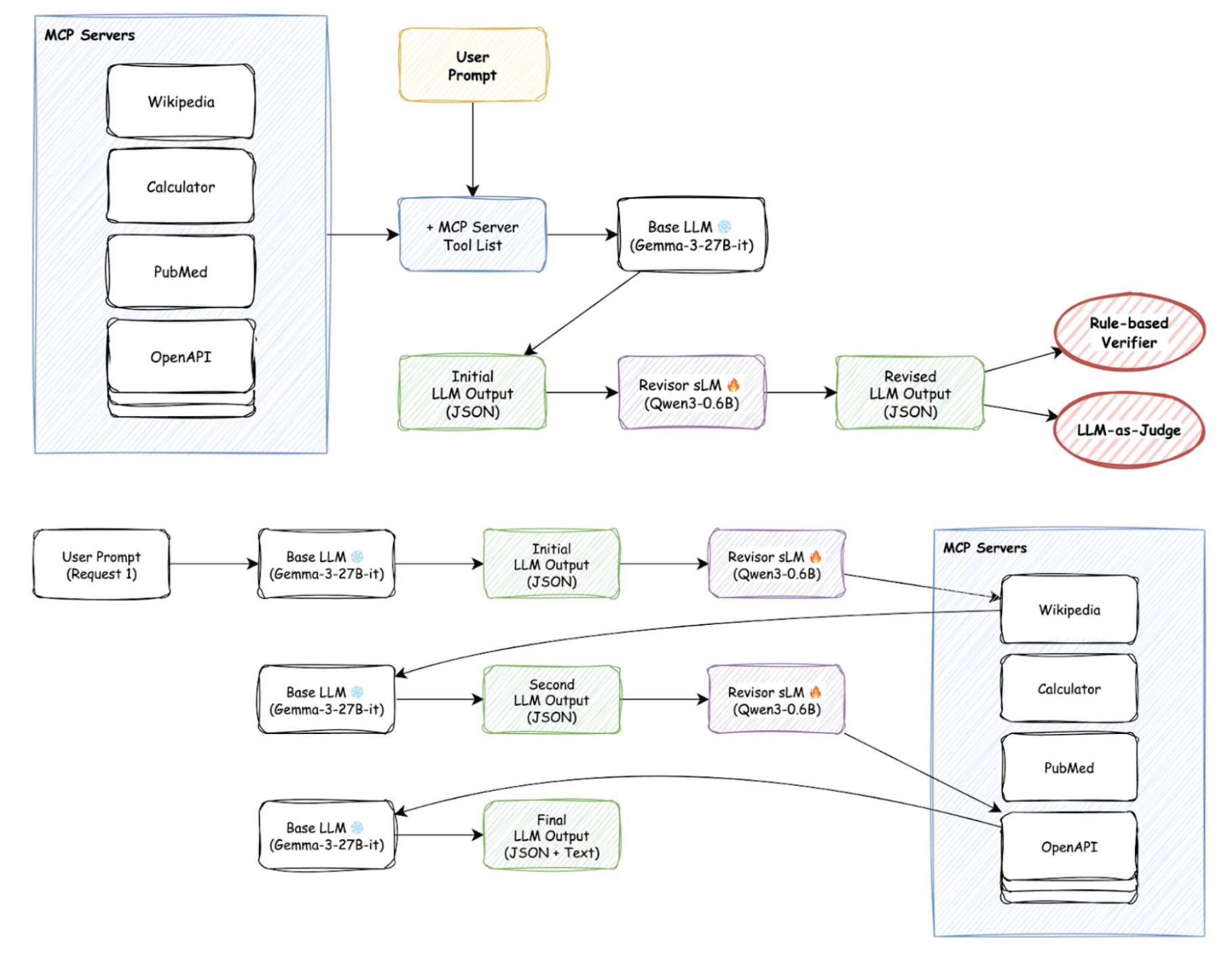
When SFT proved unsuccessful, we turned to a more complex but powerful approach: reinforcement learning (RL). The idea is straightforward: each time the sidecar model generates output, we use MCP-Bench evaluation metrics as rewards to guide it toward producing better results. The overall RL training pipeline is illustrated in the following diagram.
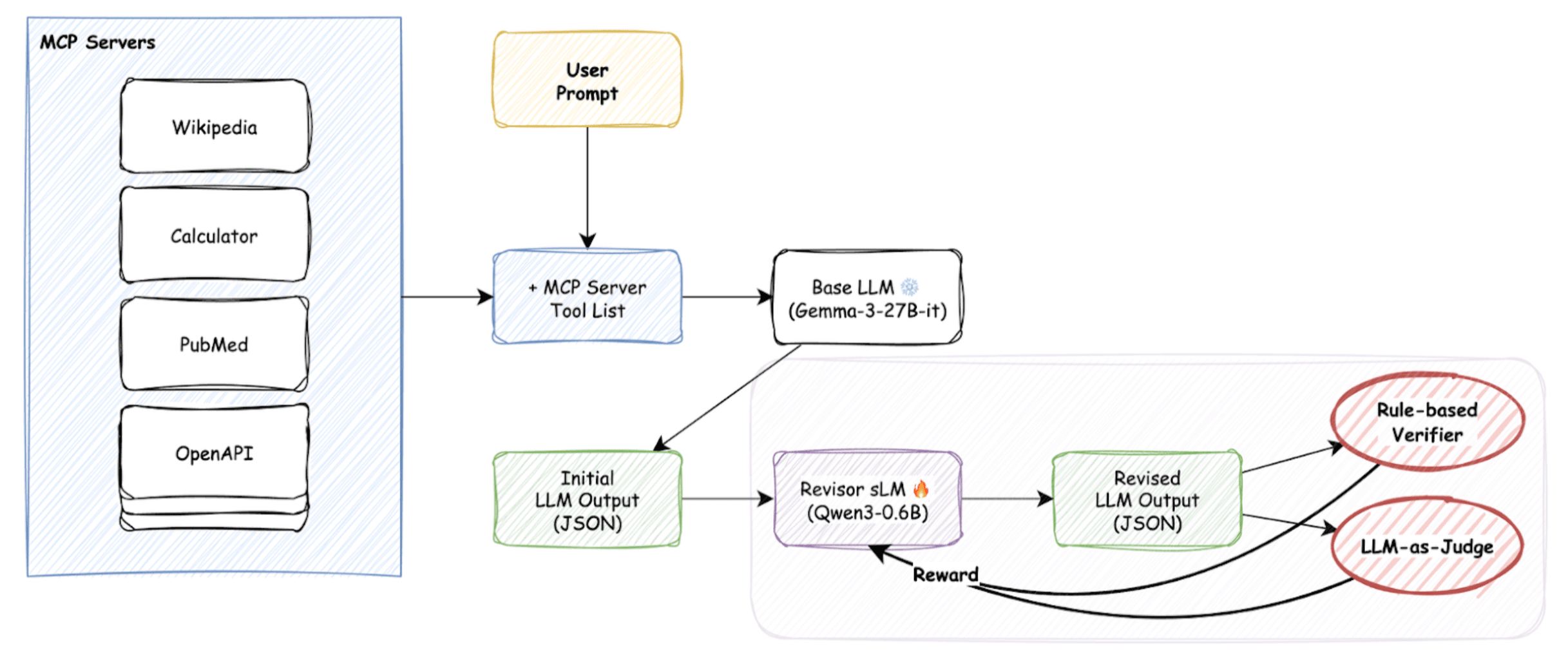
- Base LLM produces initial JSON.
- Sidecar sLM revises it.
- Output is verified via: ⦁ Rule-based checks: JSON validity, schema compliance, tool correctness. ⦁ LLM-judge checks: Usefulness and task relevance.
- Scores become rewards for updating the sLM.
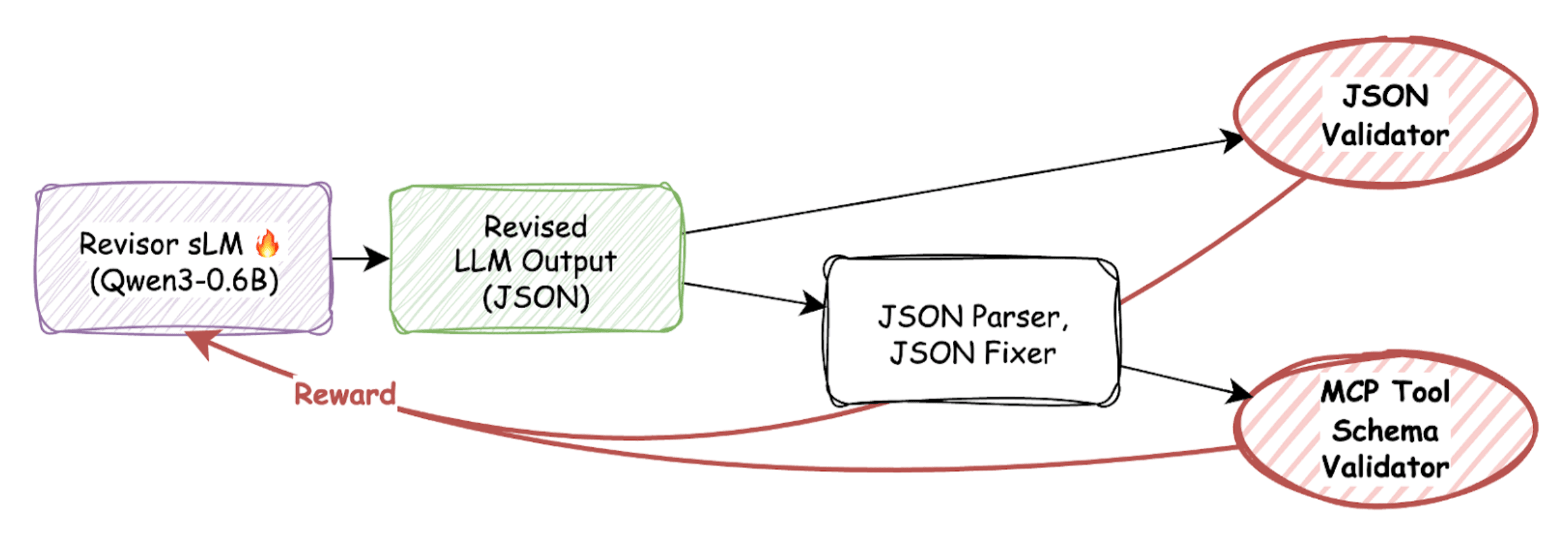
A major obstacle was “the battle with the parser”: the model often output extra text (“Sure, here you go”). When we added a parser to extract JSON, the model began gaming the parser instead of improving content.
We solved this by adding a JSON fixer before verification, ensuring that rewards reflected content correctness, not formatting tricks.
Technical Challenges and Solutions
- Extremely Long Context Length
Agent tasks require tool descriptions, examples, and multistep history, leading to extremely long inputs. Our dataset averaged 57k tokens, with some reaching 128k.
Our initial candidate, Qwen3-0.6B, supported only 40k context length. RoPE scaling (YaRN) failed at longer lengths, causing the model to hallucinate or degrade.

-> Solution: Switch to Qwen3-4B-Instruct, which natively supports 262k tokens.
- Efficient RL Framework
Online RL requires repeated inference and updates—speed is critical.
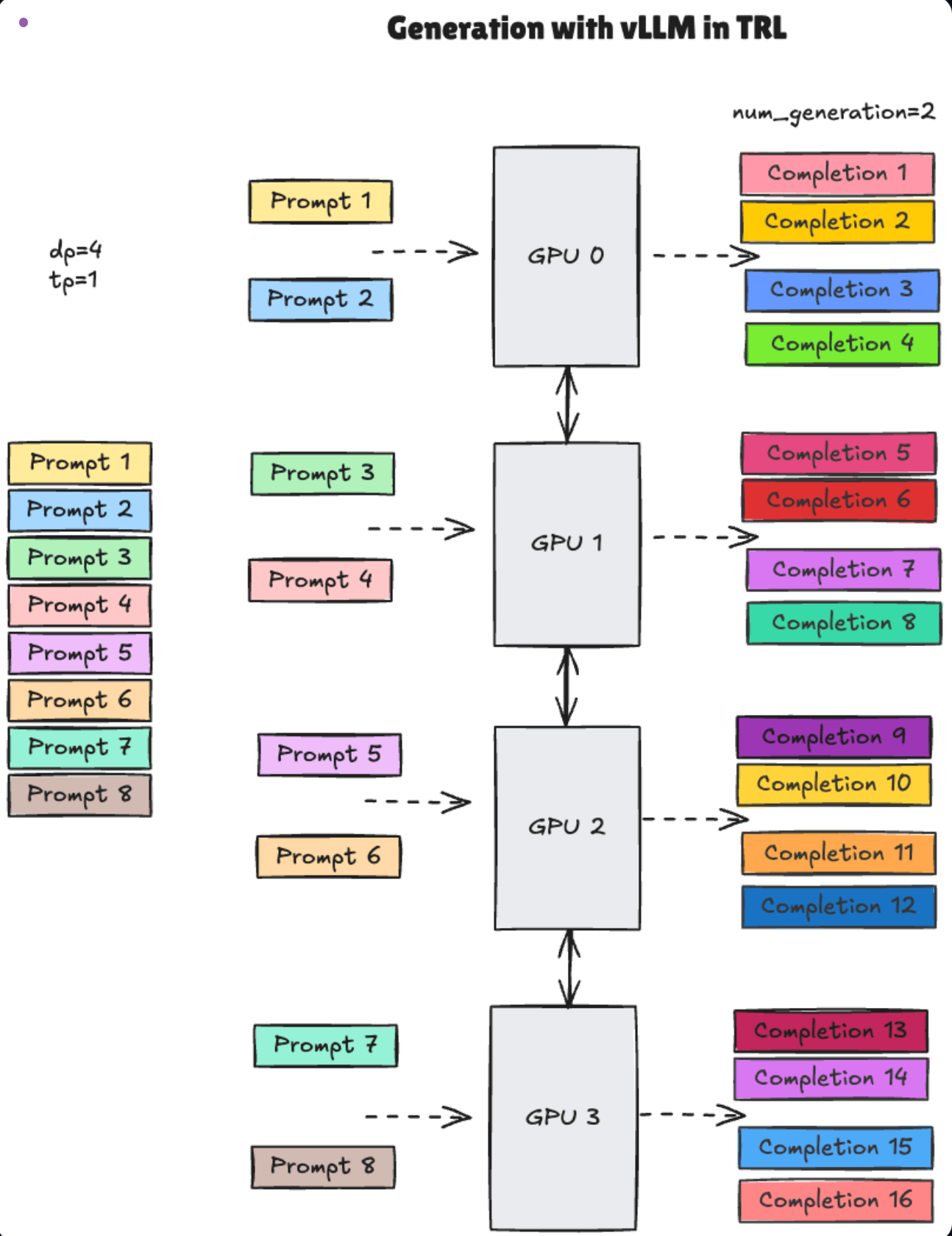
-> Solution: We built our training environment using Hugging Face's TRL (Transformer Reinforcement Learning) library with the GRPO (Group Relative Policy Optimization) algorithm. We used TRL's vLLM inference engine integration to accelerate generation speed. The TRL training loop sends updated model weights to the vLLM server via HTTP requests, which uses them to generate the next outputs.
Results and Future Challenges
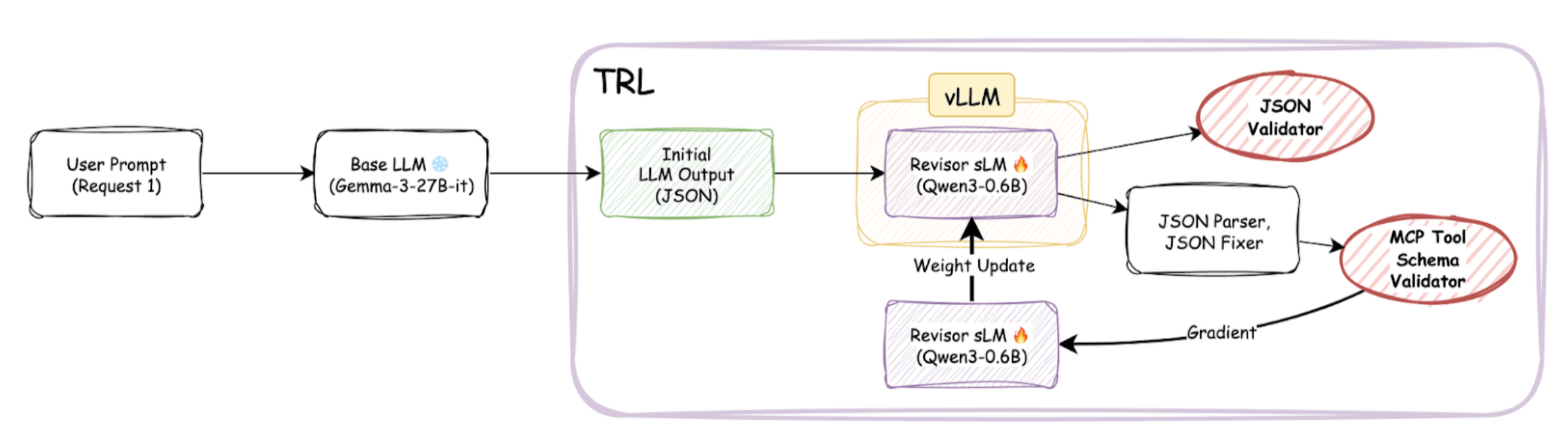
After RL training, we observed significant improvements in rule-based scores for Llama-3.1-8B with the sidecar model applied—particularly in JSON formatting, tool selection, schema adherence, and parameter validity.
However, this project is still a work in progress, and several key challenges remain:
• Integrate "LLMas a judge" rewards: Currently we use only rule-based rewards, but plan to incorporate "usefulness" scores from LLM judges into the reward function to improve qualitative performance. • Adopt more efficient frameworks: We're exploring frameworks like ByteDance's VERL, which offer faster training and agent-specific features compared to TRL. • Enhance multi-turn handling: Instead of evaluating only final outputs, we need to reward intermediate dialogue steps to better handle multi-turn interactions.
The Path Forward
We've shared our journey training a small sidecar revisor model to solve MCP compatibility issues with LLMs. From failed SFT attempts to building complex RL pipelines and tackling countless technical obstacles, this project reinforced how difficult building agentic AI really is. Still, we believe the sidecar approach is practical and has real potential: it lets you integrate diverse open-source models into capable agent systems at minimal cost, without vendor lock-in. We hope our experiments help other developers building for the age of agents.