Engineering
May 27, 2026
Engineering
eBPF security audit for GPU clusters with Backend.AI

Kyujin Cho
AI Platform Architect

Jinho Heo
Technical Writer
May 27, 2026
Engineering
eBPF security audit for GPU clusters with Backend.AI
Kyujin Cho
AI Platform Architect
Jinho Heo
Technical Writer
If you run an enterprise-grade server cluster, security auditing matters a great deal for compliance. When a breach happens, you can only trace what actually occurred if the sensitive actions were recorded: which IP connected to the system, who requested a shell privilege escalation, and so on. The problem is that logging everything for that kind of system tracing puts a heavy load on the machine. Take a GPU training cluster. While a model training job runs, tens of thousands to hundreds of thousands of syscalls pour out every second, and the moment you wedge in a sidecar process to trace each one, latency in inter-GPU communication rises. Because GPU training is sensitive to latency, that translates into lower overall training efficiency. Reaching for a traditional audit tool like auditd instead brings its own problems: faced with tens of thousands of events per second, the audit buffer overflows and events are lost, or synchronous write load drags performance down.
This is why eBPF has come up so often among infrastructure operators over the past few years. Short for extended Berkeley Packet Filter, eBPF plants a small event-detection program inside the kernel and sifts out only the meaningful events. This article looks at what eBPF is, how it manages to be both fast and safe, and how it can be applied to security auditing on Linux systems.
A Small Virtual Machine Inside the Kernel: A Short History of eBPF
eBPF (extended Berkeley Packet Filter) is a technology for running sandboxed programs inside the Linux kernel. The name alone makes it hard to see what this has to do with the auditing work described above, so a look at eBPF's history helps explain both how the technology evolved and where its name came from.
The roots of eBPF reach back quite far. It begins with the BSD Packet Filter paper presented by Steven McCanne and Van Jacobson of Lawrence Berkeley National Laboratory at the 1993 USENIX Winter Conference. The paper's core argument was that moving every packet up to user space to filter it there is too expensive, so a filter should run inside the kernel and pass only what is needed upward. As infrastructure technology advanced, that early spec, designed with nothing but network packet filtering in mind, ran into its limits. Inspecting things like CPU bottlenecks or I/O patterns required adding various modules, and on systems whose complexity grew as the number of services and Pods increased, networking performance suffered. To address this, BPF was extended so it could do more, which is where the "extended" in the name comes from. Registers and storage were expanded so that more complex logic could run inside the kernel, and event hooks grew to capture not only network packets but system calls and a range of hardware events, taking the technology well beyond its original purpose. Unlike auditd, where the kernel produces an event and a user-space daemon receives it and writes it to disk, eBPF plants a program directly inside the kernel where events occur and handles filtering and aggregation on the spot. Because the work stays inside the kernel, there is no context switching back and forth across the kernel boundary, and the overhead is lower than approaches that route everything through an interpreter.
Running every action inside the kernel does carry a risk: faulty code could threaten the system. So eBPF puts up a safety barrier. A user-written program is compiled into separate bytecode and submitted to the kernel, which verifies its safety before running it. The eBPF verifier checks that an arbitrary program does not read memory it shouldn't, contains no infinite loops, and calls only permitted helper functions; once a program passes, the JIT compiler turns it into native machine code and attaches it to hook points throughout the kernel. The result behaves like a kernel module but runs efficiently and safely, without threatening the system as a whole and without context switches.
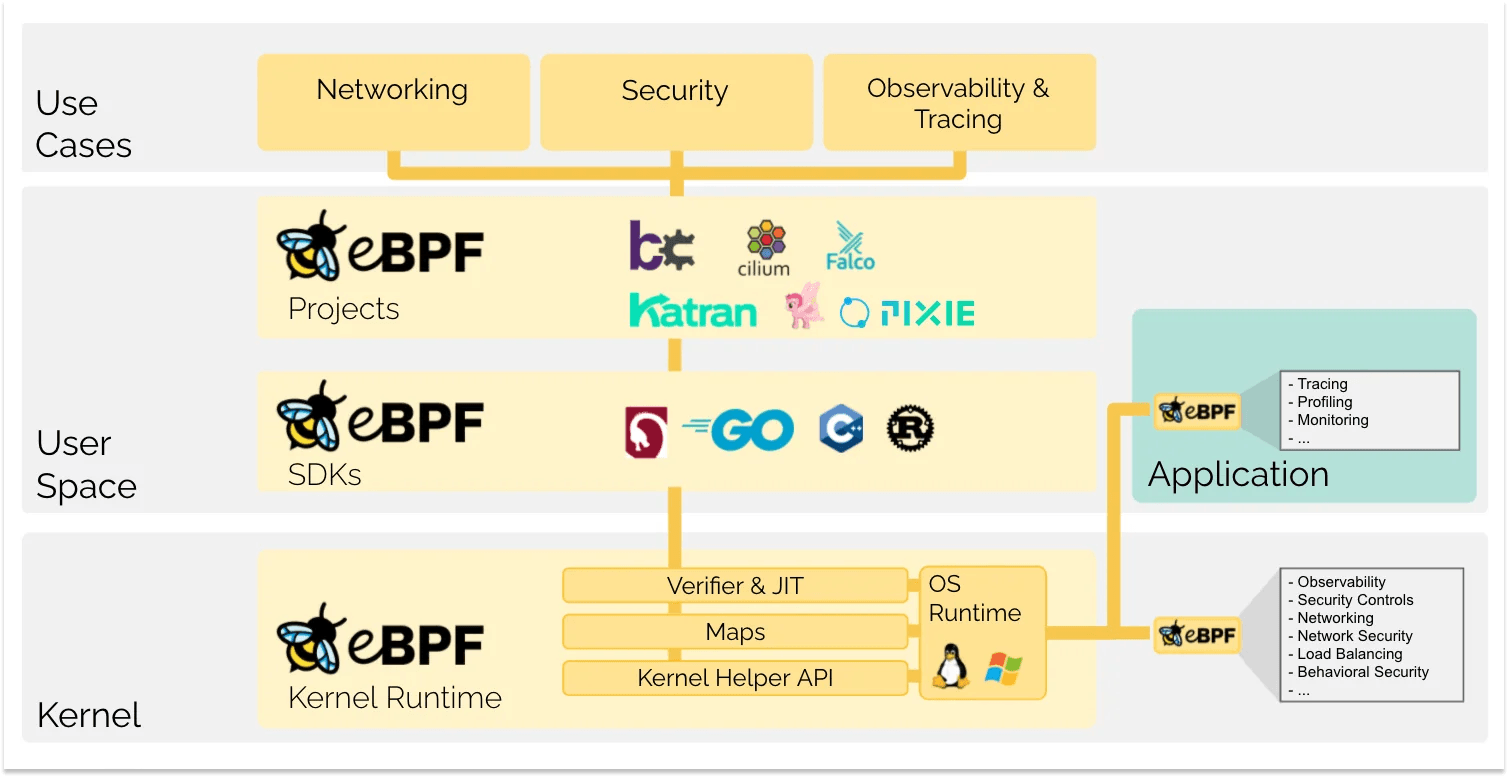
eBPF in this more developed form was merged into the Linux kernel in stages beginning in 2014 with kernel version 3.15. Tool chains like BCC, libbpf, and bpftrace then took hold, turning it into something operators could use directly, while networking and security products like Cilium pushed it into the standard toolkit for cloud-native infrastructure. In 2021 the eBPF Foundation was established under the Linux Foundation, giving the project formal governance as well.
Why Large-Scale Operators Are Turning to eBPF
Once the technology matured, eBPF began drawing attention from the people running large, complex AI infrastructure platforms. What won them over was the ability to handle everything right where an event happens, inside the kernel. In the traditional audit model, the kernel creates an event and hands it to a user-space daemon, which processes the data again and sends it off to disk or over the network. Every exchange in that handoff counts as a cost, and that cost repeats and accumulates with every event. Removing or sharply reducing it would obviously help. eBPF does away with the round trip and takes only the data that is actually needed, which cuts the cost of unnecessary events sharply and lets operators build the picture they want.
There is a second advantage, this one in compilation. BPF implementations before eBPF ran as interpreters, reading bytecode one line at a time and translating it to machine code on the fly for each event. eBPF changes that structure: when a program is loaded into the kernel, its CPU-architecture-independent intermediate representation (BPF bytecode) is converted to native machine code exactly once. Because it then runs with no interpreter overhead, it executes at effectively the same speed as code precompiled into the kernel. On a GPU training cluster fielding hundreds of thousands of events per second, that is not a small difference.
Finally, the verifier described earlier guarantees stability. Infinite loops and unverified memory access are blocked at the source, so you can attach an audit probe to the hot path (the core execution path called on every event) confident that the eBPF program will not break the system, whatever workload is running. In an HPC or AI cluster where milliseconds count, a well-designed eBPF audit system is a way to meet compliance requirements while keeping the extra CPU burden to a minimum.
Before You Reach for eBPF: Privilege Is Security
For all the advantages above, there is one area that demands care, and that is security. "If you gaze long into an abyss, the abyss also gazes into you." Just as eBPF can go deep into the kernel to inspect packets and calls, anyone with malicious intent who reaches that same position can do exactly the same thing. BPFDoor, a Linux backdoor that abuses BPF, is the textbook example of this shadow. Disclosed in May 2022 independently by PwC Threat Intelligence and Elastic Security Labs, BPFDoor exploits BPF's packet-filtering capability to lie dormant until a packet carrying a specific pattern (a "magic packet") arrives. Once it activates, the system hands control to the attacker and starts carrying out actions it was never meant to.
An attack delivered this way is genuinely hard to detect. It opens no port, so a port scan turns up nothing; it runs from a memory-based filesystem and then erases its own traces from disk; and because its command traffic is encrypted in both directions, it slips past network detection as well. In the 2025 security breach at a major Korean telecom, malware of this family was found to have evaded detection for years, and the same technique is known to have been used over long periods in attacks on telecoms, government agencies, and other large organizations.
The lesson is that a tool built to create visibility can be just as useful for erasing it, and that the permission to load an eBPF program is itself a security asset. Operating a system like this effectively means keeping that in mind. The basic security principle is worth committing to memory: if you do not design the watcher carefully, or if no one watches the watcher, the watcher can turn into the intruder.
eBPF-Based Auditing in Practice
Here are a few of the problems a cluster administrator faces that an eBPF-based audit system is well suited to solve.
Catching the curl … | sh pattern: Downloading an external script and running it immediately without any verification is, surprisingly, one of the most common attack patterns. With eBPF you can catch it as a precise chain: a process makes an outbound TCP connect(), and within one second the same process tree calls execve() on a shell binary (/bin/sh, bash, dash). Drop scripts left in temporary areas like /tmp or /dev/shm can be tracked alongside through LSM hooks, so the "downloaded, dropped, executed" sequence comes together as a single timeline.
Container escape attempts: Watching for calls like pivot_root, unshare(CLONE_NEWNS), mount, umount2, and capset inside a container lets you monitor most escape attempts from one place. The catch is that a normal runc init triggers the same calls when a container starts, so detecting the bare occurrence of a call would leave you buried in false alarms. The common approach is to scope monitoring to calls from the user containers where workloads run and to exclude calls from container-runtime helpers like runc, leaving only the genuinely suspicious cases.
Data exfiltration to the outside: Filter the cluster's internal RFC1918 private-range traffic out inside the kernel, pass up only the connect() calls headed for non-private ranges, and then join, in time order, whether the same container had just read a credential file under /etc/shadow, /root/.ssh/, or /workspace/. Do that and you can trace which container read what, where, and where it sent the result. Much of what makes post-incident cleanup drag on is the inability to trace this path, or tracing data that was designed to be hard to read afterward, and eBPF hooks are light enough to leave on even during normal operation.
SSH privilege-escalation chains: You can readily check whether a session that came in over SSH inherited root within a short window, and whether it then touched sensitive paths like /etc/sudoers or ~/.ssh/authorized_keys right afterward.
None of these scenarios were impossible to handle with earlier technology. What eBPF changes is that it makes them light enough to run even on top of an environment that is sensitive to workload latency.
Always-On Auditing Without the Tradeoff
Being able to leave security auditing on at all times does not simply mean keeping more logs. It means building up operational data day to day so that when an incident does hit, you can pinpoint the cause quickly and have the evidence you need to keep it from happening again. If the reason this obvious requirement has been so hard to meet was the performance cost, eBPF changes that premise from the start. By selecting only the events that matter inside the kernel, and by letting code compiled once at load time handle every event after that, it turns an always-on audit system into something other than a compromise against performance. Because it secures visibility into breaches without shaving training efficiency, eBPF is becoming a practical option for infrastructure operators who need performance and security at the same time.
The security audit component of Backend.AI, the operations platform for managing AI infrastructure and workloads, is being designed on top of eBPF. So that operators can see straight away what happened in which workload when a breach occurs, Backend.AI uses eBPF to track system calls, file access, network sockets, and privilege changes, recording the container ID and user information alongside each. When a suspicious pattern surfaces in that data, an operator can narrow the scope down to a single container and run a precise investigation. If you want to keep the AI workload performance your infrastructure delivers fully intact while still covering security auditing, Backend.AI is a good place to start.
To learn more about Backend.AI, visit the official website.