Engineering
Jun 19, 2026
Engineering
The era of diverse AI accelerators: Backend.AI's heterogeneous GPU operation strategy

Jinho Heo
Technical Writer
Jun 19, 2026
Engineering
The era of diverse AI accelerators: Backend.AI's heterogeneous GPU operation strategy
Jinho Heo
Technical Writer
When purchasing GPUs, selecting a single vendor would simplify things. In practice, that is often not the case. For example, you may still be operating NVIDIA H100 GPUs while adding AMD MI350X with this year’s budget. You might also introduce accelerators from another vendor to improve cost efficiency for specific inference workloads, or mix different types of accelerators to separate prefill and decode stages.
The data center AI accelerator market is diversifying rapidly. AMD has expanded adoption of the MI300X series among large customers and announced a next-generation MI450 deployment through a strategic partnership with OpenAI.1 ROCm 7.x improves PyTorch native support and performance, and the software ecosystem2 is maturing alongside it. Intel Gaudi is gaining traction with competitive price-performance, while in Korea, Rebellions ATOM has been deployed on KT Cloud and FuriosaAI has entered mass production with RNGD.3 Domestic NPUs are now a practical option.
There are many accelerators in the market because each one has strengths in different areas. NVIDIA H100 and B200 remain strong in large-scale distributed training with NVLink and NVSwitch. AMD MI300X is effective for large model inference with 192GB HBM3 capacity. Intel Gaudi targets cost-efficient training and inference workloads. Domestic NPUs provide optimized performance for specific models and services with inference-focused architectures. However, integrating heterogeneous accelerators into an existing cluster introduces operational complexity that often exceeds the difficulty of hardware procurement. This article reviews common challenges in heterogeneous GPU environments and outlines configuration strategies using resource groups.
Software stack differences by vendor
NVIDIA H100 and AMD MI300X are both data center AI accelerators, but their software stacks are fundamentally different. NVIDIA uses CUDA with libraries such as cuDNN, NCCL, and TensorRT. AMD uses ROCm with MIOpen, RCCL, and HIP. Intel Gaudi uses its own software suite, formerly known as SynapseAI. Domestic NPUs also rely on their own SDKs and compiler stacks. Frameworks like PyTorch support multiple backends, but differences in runtime and drivers prevent a single distributed training job from spanning accelerators from different vendors.
Collective communication libraries also differ. NVIDIA NCCL and AMD RCCL have similar APIs, but their underlying communication topologies are different. NVLink and NVSwitch optimization differs from AMD Infinity Fabric communication in bandwidth structure. Tuning for one does not directly translate to the other.
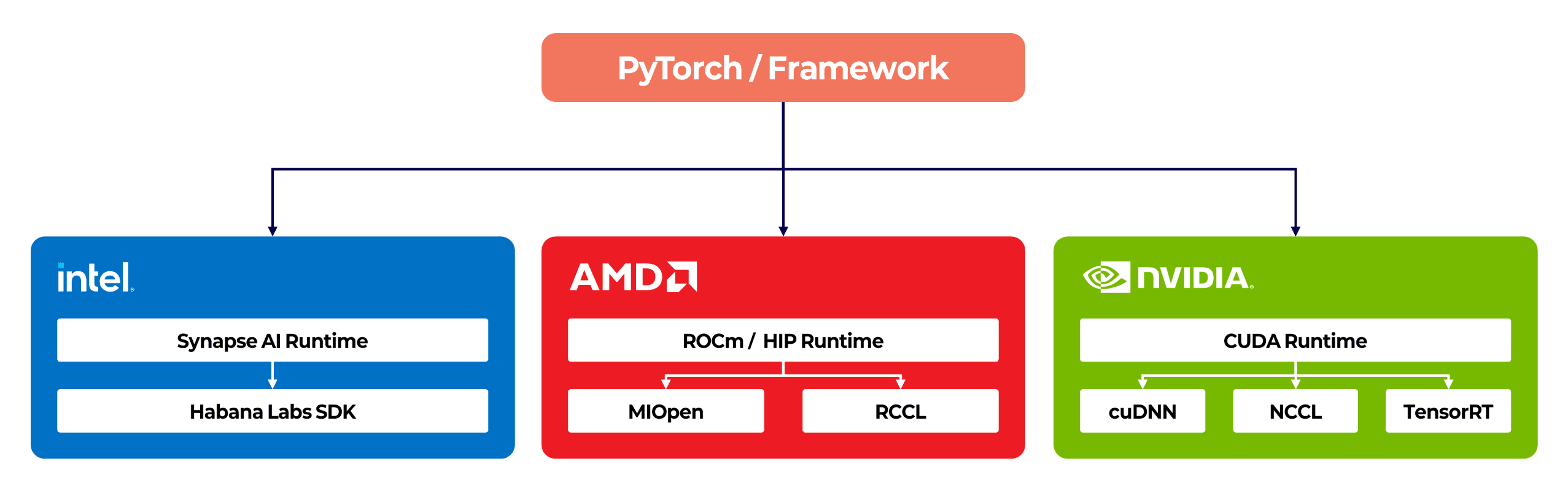
Placing accelerators from different vendors in the same cluster is still useful. While a single distributed training job cannot span multiple vendors, assigning workloads to appropriate accelerators is practical. For example, large-scale LLM training can run on an NVIDIA H100 NVLink cluster, while inference serving or fine-tuning can run on AMD MI300X with large HBM capacity. Specific inference workloads can also run on domestic NPUs.
Mixing GPUs with different performance
A common planning mistake in heterogeneous environments is trying tom place accelerators with significantly different performance characteristics into a single resource pool. In multi-node distributed training, mixing GPUs with different performance leads to bottlenecks. Each training step requires gradient synchronization across all GPUs. Faster GPUs complete computation earlier and wait for slower ones. This delay accumulates at every step. Overall cluster utilization converges to the speed of the slowest accelerator, and the opportunity cost increases with higher-end GPUs.
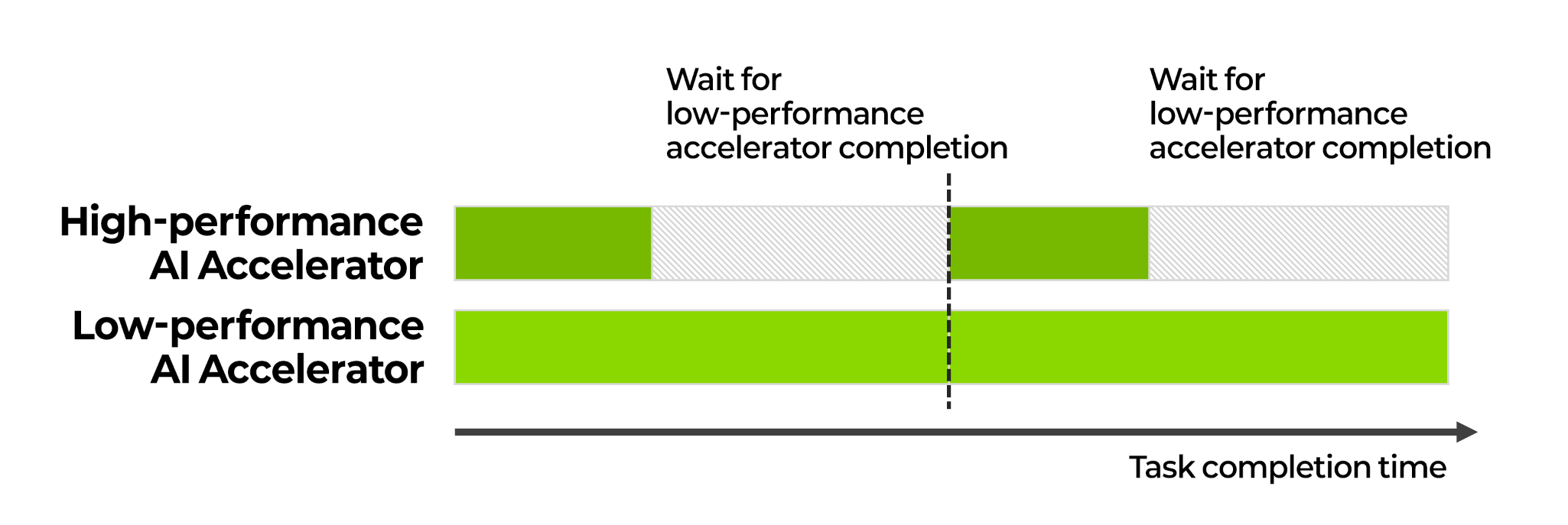
This issue also appears across GPU generations from the same vendor. If H100 and V100 are grouped together, H100 will wait for V100 due to differences in compute performance and NVLink bandwidth. This reduces the effective utilization of H100.
Resource group based heterogeneous strategy
A common approach to heterogeneous clusters is to separate accelerators with different characteristics into distinct resource groups and assign workloads accordingly. Kubernetes node labels and taints, Slurm partitions, and Ray placement groups implement similar patterns at different layers. Backend.AI resource groups follow the same concept, with a focus on AI workloads and multi-vendor environments.
Clusters are divided into logical resource groups, each with independent scheduling policies. Even if NVIDIA, AMD, and Intel nodes are physically located in the same data center or rack, they are managed as separate resource pools in software.
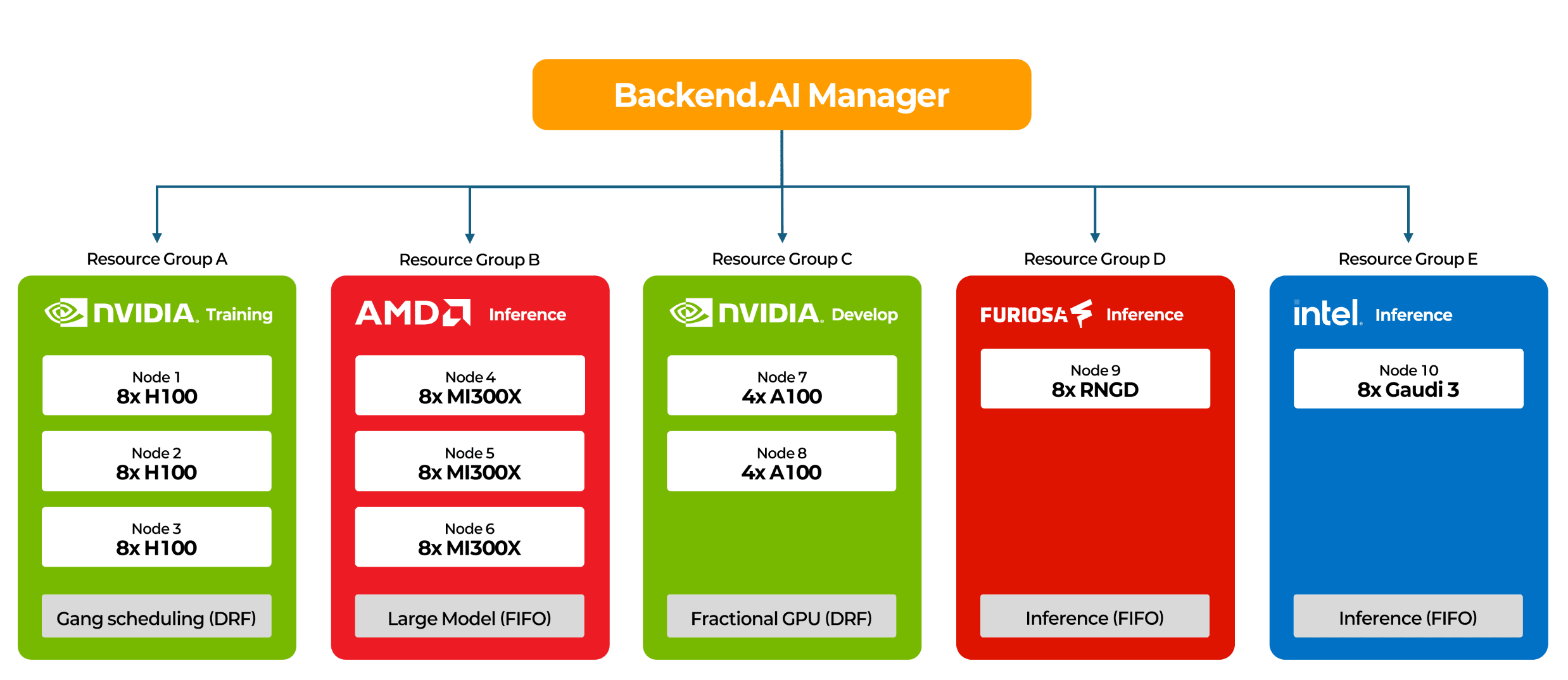
This structure prevents unintended placement. CUDA-based training jobs are submitted only to NVIDIA groups, ROCm-based inference runs only on AMD groups, and NPU workloads run in dedicated groups. Runtime mismatches are eliminated by design. Each group can apply scheduling policies tailored to its use case. For example, an H100 training group can use DRF and gang scheduling to avoid partial allocation deadlocks in multi-node jobs. An MI300X inference group can use FIFO and leverage 192GB HBM3 to run large models on a single card. A development group can enable container-level GPU virtualization to allow multiple workloads to share a single GPU.
From an operational perspective, administrators need usage visibility across groups. Backend.AI provides group-level accounting. When integrated with billing systems, usage by vendor or group can be tracked, and quotas can be applied per group.
Sokovan HAL and two-level scheduling
Backend.AI implements this architecture through the Sokovan orchestrator. Sokovan integrates accelerators from multiple vendors through a hardware abstraction layer. Physical devices are exposed as resource slots such as cuda.device, cuda.shares, rocm.device, and atom.device. Users can request specific hardware or request a general class such as high-performance GPUs.
Sokovan’s two-stage scheduling operates by first having the global scheduler filter candidate nodes across the entire cluster that satisfy a job’s requirements, such as accelerator type, quantity, and memory. It then selects the most appropriate node by considering resource availability and policy-based priorities. If fractional GPU is enabled, GPUs can be partitioned based on memory allocation and shared across multiple workloads.
Resource groups act as scheduling boundaries. Jobs submitted to one group are not scheduled to nodes in another group. Each group can define its own scheduling policy, agent selection strategy, and queueing behavior. For more details on how Sokovan works, please refer to the following post.
To address monitoring fragmentation, Lablup provides all-smi as an open source tool. It unifies metrics such as utilization, memory usage, temperature, and power across NVIDIA GPUs, AMD GPUs, and Intel Gaudi. It also exposes Prometheus-compatible endpoints for integration into existing monitoring pipelines.
Key considerations
Container images should be separated by accelerator type. CUDA, ROCm, and NPU SDK environments should be built and managed independently. Backend.AI supports both catalog images and custom images, allowing users to map images to resource groups.
Network topology is also important. If multi-node training is expected within a group, nodes should be placed in close network proximity. NVIDIA clusters typically use InfiniBand, while AMD clusters use RoCE. Consistency within a group is important for stable distributed training performance.
For inference and development workloads, full GPUs are often unnecessary. Fractional GPU can improve utilization. Backend.AI supports container-level GPU virtualization, allowing memory and compute units to be partitioned across workloads. Unlike hardware partitioning methods such as MIG, this approach does not depend on specific hardware features and allows flexible partitioning. Currently, this feature is available on NVIDIA GPUs, with support for AMD and Intel in progress.
Finally, cluster design should account for future accelerator additions. Even if only NVIDIA and AMD are used today, Intel Gaudi or domestic NPUs may be introduced later. A resource group based architecture allows new accelerators to be integrated by adding new groups without restructuring the system.
Closing remarks: Design criteria for heterogeneous configurations
The AI accelerator market is expanding across AMD Instinct, Intel Gaudi, and domestic NPUs such as Furiosa RNGD and Rebellions ATOM. Multi-accelerator strategies are becoming practical for matching workloads to the most suitable hardware. The key challenge is how to logically separate accelerators with different software stacks and assign workloads based on their strengths. Resource groups and appropriate scheduling policies enable efficient utilization in heterogeneous environments.
Backend.AI is designed to support this model at the software level. It has been deployed across more than 120 sites globally, supporting accelerators from multiple vendors in heterogeneous configurations. These deployments span GPU-as-a-Service platforms, financial sector LLM systems, and large-scale research infrastructure.
If you are looking to optimize heterogeneous GPU operations, consider consulting with Lablup to evaluate your current accelerator mix and workload characteristics.
Footnotes
-
AMD, AMD and OpenAI Announce Strategic Partnership (2025). ↩
-
AMD, ROCm 7.0: Supercharging AI and HPC Infrastructure (2025). ROCm 6 대비 학습 성능 3배, 추론 성능 3.5배 향상 벤치마크 (동일 하드웨어 기준 소프트웨어 개선치). ↩
-
FuriosaAI, RNGD enters mass production (2026). Rebellions ATOM의 KT Cloud 상용 배치는 Rebellions 공식 뉴스룸 참조. ↩



