Jun 12, 2026
Engineering
Intel Arc meets Backend.AI: What the Arc Pro B70's 32GB memory buys for agentic AI

Jinho Heo
Technical Writer

Kyujin Cho
AI Platform Architect

Gilliean Lee
AI Solutions Architect @Intel
Jun 12, 2026
Engineering
Intel Arc meets Backend.AI: What the Arc Pro B70's 32GB memory buys for agentic AI
Jinho Heo
Technical Writer
Kyujin Cho
AI Platform Architect
Gilliean Lee
AI Solutions Architect @Intel
Building on its existing support for Intel Gaudi 2/3 AI accelerators, Backend.AI now extends its Intel lineup to Arc graphics, starting with the Arc Pro B70. With a larger memory pool than competing desktop-grade options, the B70 shows its clearest advantage in agentic AI workloads, where sustained throughput and memory capacity matter more than peak single-user performance.
For LLM serving, the spec that increasingly decides whether a card is useful is memory, and the main reason is the KV cache. The KV cache, the data an inference engine keeps so it can reuse prior work instead of recomputing it, grows with both context length and the number of concurrent requests. Agentic workflows push on both axes at once. A coding agent carries a long base context and revisits it across many turns, and a production deployment runs many such agents in parallel. When a card runs out of memory for the KV cache, it starts evicting and recomputing, and throughput falls off a cliff. One answer is to move the cache off the GPU entirely (KV cache offloading); the other is to start with more memory on the card, so the cliff arrives later.
The following benchmark and analysis puts that to the test against the NVIDIA RTX PRO 4000 Blackwell, a common desktop-grade alternative, across several open models. As a result, the B70's lead widens as context and concurrency grow, which is the direction agentic workloads pull.
Meet the Arc Pro B70
The Intel Arc Pro B70 is a workstation GPU built on Intel's Xe2 (Battlemage) architecture, launched in March 2026 for AI inference and professional visualization.
 | ||||||||||||||||||||
|
The headline number for inference is the 32 GB of GDDR6, paired with 608 GB/s of bandwidth. Memory is what an LLM serving stack runs short of first. After the model weights load, whatever memory remains holds the KV cache, so a 32 GB card can keep far more context and far more concurrent requests resident before it runs short. At $1,099, that much memory is within reach of a single workstation, which is what makes the B70 worth a close look for local and small-cluster inference.
The benchmarks below were run on one card (tensor parallelism of 1), the way most desktop and workstation deployments will use it.
Where the B70 Earns Its Keep
A workstation card with a large memory budget changes what is possible on your desk. Instead of renting datacenter time to prototype an agent that needs a long context window, a team can run it locally, cost-effectively, and keep the same model serving stack it would use in production. The B70's strength is not raw speed on a single short request; it is headroom.
And that headroom matters most to agentic workflows. More KV cache means more agents, longer contexts, and higher concurrency on one card before throughput degrades. Each agent pins a long prefix, the codebase and its tools, and returns to it turn after turn. Run several agents at once and the card's memory, not its compute, becomes the binding constraint. That is exactly the regime the benchmarks below are built to expose.
The Benchmarks
Bandwidth and compute offer the greatest advantage on single, short requests; raw capacity matters most under sustained load. To evaluate the B70's memory in context, it was benchmarked against the NVIDIA RTX PRO 4000 Blackwell, a widely deployed desktop-grade workstation card. The two products occupy a similar market position, making them a suitable basis for comparison, though the RTX PRO 4000 Blackwell holds a narrow overall specification advantage. It carries 24 GB of GDDR7 memory with higher bandwidth (672 versus 608 GB/s) and better raw FP32 compute. The B70 offsets this with a larger memory pool, at 32 GB versus 24 GB.
Both cards were tested in identical nodes (Intel Xeon w9-3475X, Ubuntu 25.10), each running a single GPU with tensor parallelism of 1, under vLLM's bench sweep across input lengths, output lengths, and concurrency levels. Three open models were used, OpenAI's GPT-OSS 20B, Qwen3 4B Instruct 2507, and Qwen3 8B. Output throughput is the primary metric.
1. Under agentic load, the B70 keeps scaling
Agentic workloads combine long contexts with many concurrent requests, so the first test holds Qwen3 8B at an 8,192-token input and raises concurrency from 1 to 16.
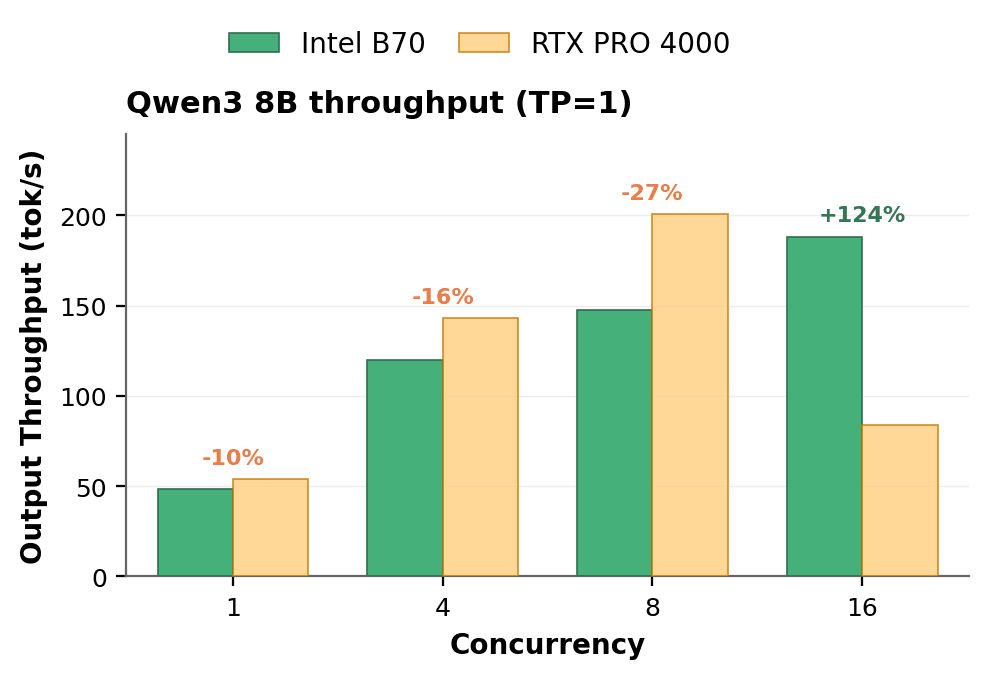
The B70 scales cleanly with load: 48.5 tok/s at a single request, 147.4 at 8 concurrent, and 188.2 at 16, climbing the whole way. The RTX PRO 4000 Blackwell is quicker early, leading through 8 concurrent requests. But at 16 it runs short of memory to hold every request at once, and its throughput drops to 83.9 tok/s, because past that point the card spends its time discarding and recomputing work instead of adding to it. The B70 has room for all 16 sessions, keeps serving them, and ends up 2.24x ahead at the busy end1.
Push the context longer and the B70 pulls ahead sooner. At a 32K-token input it sustains throughput by 4 concurrent requests where the RTX PRO 4000 Blackwell cannot hold even a handful of contexts that large, leading 3.6 to 4.4x2. Given the direction agentic AI workloads are heading, the B70's memory advantage translates into a tangible operational benefit.
2. The B70 keeps scaling even on a 20B model
A larger model takes a bigger fixed bite of GPU memory before any request arrives, leaving less for the work in flight, so it is the harder test of whether a card can stay productive under load. GPT-OSS 20B is the largest model in the set. The next test runs it at a 2,048-token input and 2,048-token output across the full concurrency range.
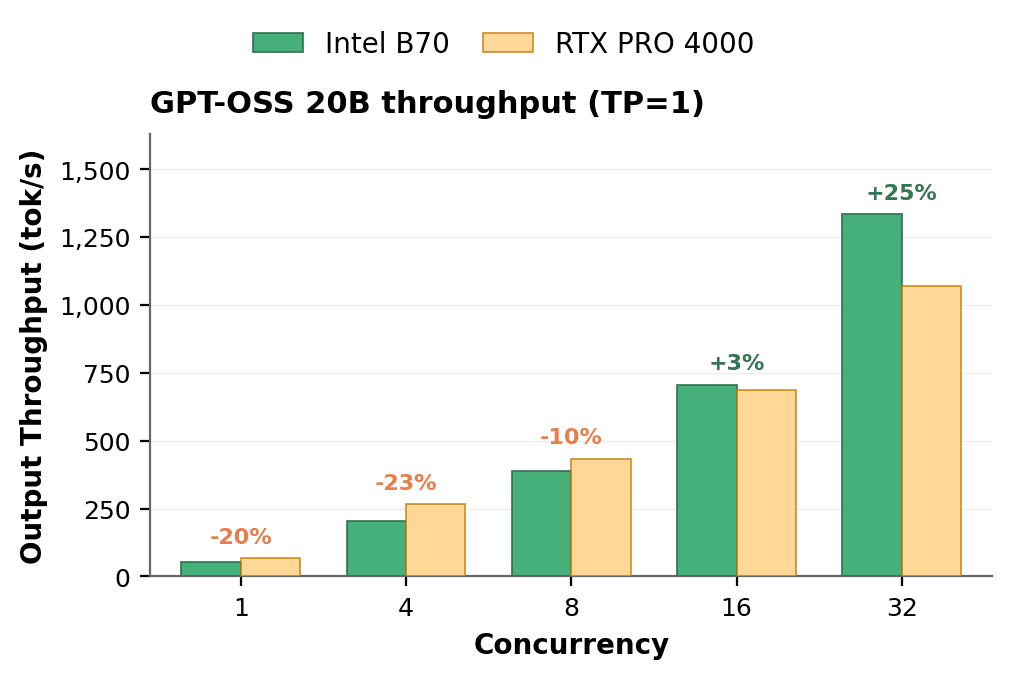
Even on this model, the B70's throughput keeps rising with every step up in concurrency: 54.8 tok/s serving a single request, 706.9 at 16, and 1,334.4 at 32. Each batch of added requests keeps adding throughput rather than saturating the card. The RTX PRO 4000 Blackwell follows the same shape as in the first test: faster on light load, but it stops gaining as requests pile up. The two cards draw even at 16 concurrent requests (706.9 versus 686.0 tok/s), and by 32 the B70 is 1.25x ahead (1,334.4 versus 1,071.6)3. With a model this large, less memory remains for in-flight requests, and the B70's larger free pool is what keeps it climbing where the RTX PRO 4000 Blackwell plateaus. This pattern held consistently across the full production range of load, underscoring the direct relationship between memory capacity and sustained throughput in agentic AI workloads.
3. Why the B70 holds up: ~2.1x more usable KV cache
Both crossovers trace back to one number, how much KV cache each card can hold once the model weights are loaded. To measure it, we recorded the maximum concurrent tokens each card sustains per model.
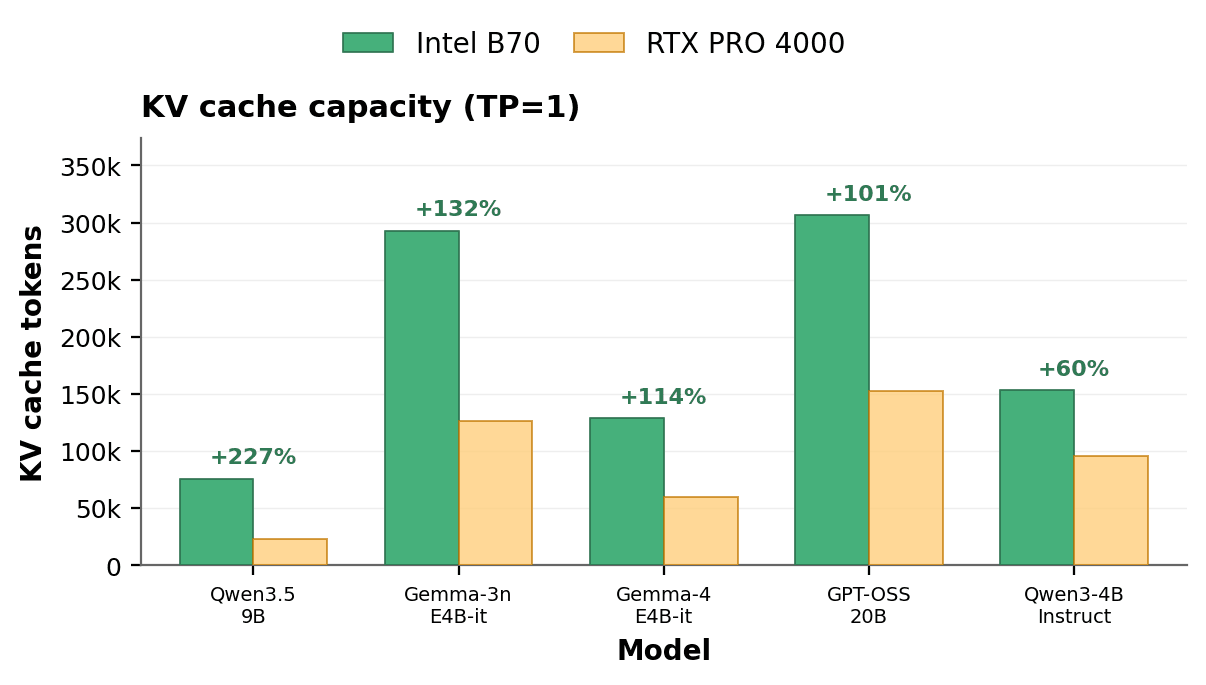
This comparison covers a broader model set than the throughput tests above, which focus on GPT-OSS 20B and Qwen3 8B.
Averaged across the set, the B70 holds about 2.1 times the KV cache of the RTX PRO 4000 Blackwell (roughly 191,000 versus 92,000 tokens)4. That gap is wider than the raw 1.33x ratio of 32 GB to 24 GB, because the model weights take a fixed slice of each card first, and the B70's larger remainder is disproportionately bigger5. The advantage is largest on the newer, more memory-efficient model designs. This is what the throughput sweeps show on the ground: once a card runs out of cache it evicts and recomputes and throughput falls off, and the B70's larger budget pushes that point further out.
Tokens per dollar
Throughput is half the cost story; price is the other half. At list price the B70 is $1,099 against $2,199 for the RTX PRO 4000 Blackwell, cheaper before any throughput is counted. Fold the benchmark results in, and the efficiency gap widens.
The two effects compound in the agentic regime. Tokens per dollar is output throughput divided by card price. The B70's edge is therefore its throughput ratio times its price advantage of 2.0 (the RTX PRO 4000 Blackwell's $2,199 list price over the B70's $1,099).
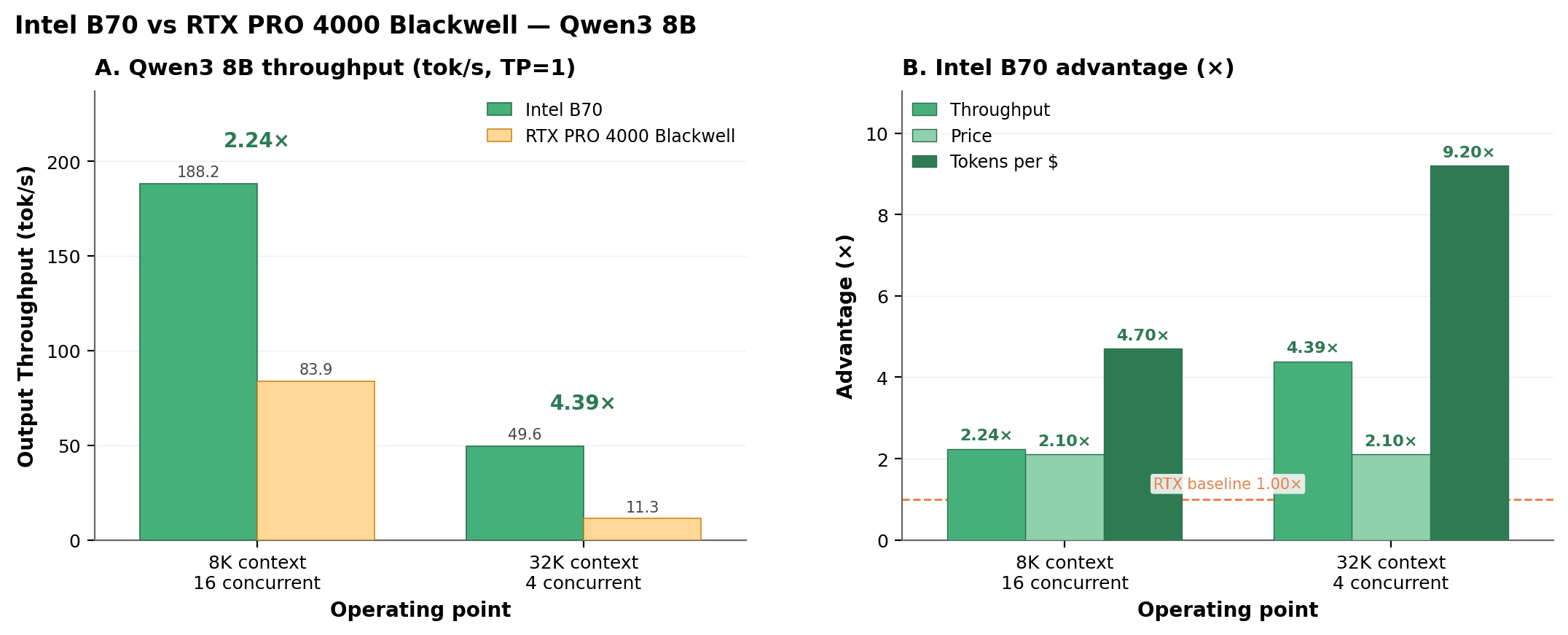
| Operating Point | Output Throughput B70 vs RTX PRO 4000 Blackwell | Price Advantage | Tokens per Dollar |
|---|---|---|---|
| Qwen3 8B, 8K context, 16 concurrent | 2.24x188.2 vs 83.9 tok/s | 2.0x | 4.48x |
| Qwen3 8B, 32K context, 4 concurrent | 4.39x49.6 vs 11.3 tok/s | 2.0x | 8.78x |
Even at low concurrency, where raw throughput trails by 10 to 20 percent, the lower price keeps the B70's tokens per dollar slightly ahead (a 0.90x throughput ratio still nets 1.9x the tokens per dollar). On output per dollar, the B70 is hard to beat across the range and decisive where agents run.
Power runs the other way at first. The B70 draws 230 W to the RTX PRO 4000 Blackwell’s 140 W, so in single-user, low-concurrency use the RTX PRO 4000 Blackwell is the more energy-efficient card. But that edge holds only in the regime the B70 was not built for. Pile on concurrent users and the B70's throughput lead more than offsets the higher draw, pulling it ahead on tokens per watt. So acquisition cost favors the B70 throughout, and under the many-user load where agents run, it leads on operating cost too.
From Desktop to Datacenter, One Platform
The B70 covers the desktop end of agentic AI well: one workstation card serving a long-context agent, or a handful of them at once. But teams sit at different points on a wider range, and not every team moves along it. Some run everything on a single card and stay there. Some pool a few nodes into a shared inference cluster for a team. Some run the same workload on a datacenter fleet. Backend.AI runs across all three from one control plane and one model serving stack, so the platform stays the same whichever point a deployment occupies. For teams whose work does span more than one, that consistency is what lets them move between points without rebuilding the pipeline. Adding Intel XPUs to the supported set extends that span downward, to the cards a team can put under a desk.
For agentic AI, where the binding limit is memory rather than raw compute, a card like the B70 widens the choice at the desktop end, and Backend.AI keeps the management consistent across the rest of the range. Wherever a given workload sits — one B70 under a desk, a shared cluster, or Gaudi in the datacenter — the hardware underneath becomes a choice, not a constraint. Pick the Intel card that fits, and Backend.AI puts it to work serving your models and agents, with nothing else in the stack to change.
Backend.AI runs AI workloads on any accelerator, from edge devices to datacenter clusters, including Intel XPUs. To evaluate Backend.AI with the B70 or your own hardware, contact Lablup at contact@lablup.com or visit backend.ai.
*The PDF version of this post can be downloaded from the following link.
Benchmark conditions
- Cards: Intel Arc Pro B70 (32 GB GDDR6) vs NVIDIA RTX PRO 4000 Blackwell (24 GB GDDR7 ECC).
- Nodes: Intel Xeon w9-3475X, Ubuntu 25.10. B70 node 96 GB RAM; RTX PRO 4000 Blackwell node 256 GB RAM. Single GPU per run, tensor parallelism of 1.
- Tool: vLLM
bench sweep, request rateinf(all prompts submitted simultaneously; concurrency equals prompt count). - Models: GPT-OSS 20B, Qwen3 4B Instruct 2507, Qwen3 8B. KV cache comparison also covers Gemma-4-E4B-it, Qwen3.5-9B, Gemma-3n-E4B-it.
- Metric: output throughput (tokens/s); per-user throughput is output throughput divided by concurrency.
- Benchmark data: Intel & Lablup, April 2026.
Additional Disclaimer Info
- MSRP based on Newegg retail listings as of June 9, 2026: https://www.newegg.com/intel-arc-pro-b70-32gb-graphics-card/p/N82E16814883008. Prices for products at the point of sale are subject to a broad array of factors – including local tariffs, taxes, and other factors; Intel’s suggested pricing guidance does not constitute a formal pricing offer from Intel. Availability will vary by country and retailer. Customers can always confirm availability]and final price information with their preferred retailer(s) before making a purchase.
Footnotes
-
Benchmark testing based on measurement of token throughput while running Qwen3 8B LLM: https://huggingface.co/Qwen/Qwen3-8B. Intel results based on test system running Intel Xeon w9-3475X, Intel Arc Pro B70 GPU, and 96GB of memory on Ubuntu 25.10. Nvidia results based on test system running Intel Xeon w9-3475X, Nvidia RTX PRO 4000 GPU, and 256GB of memory on Ubuntu 25.10. Results as of April 14, 2026 ↩
-
Benchmark testing based on measurement of token throughput while running Qwen3 8B LLM: https://huggingface.co/Qwen/Qwen3-8B. Intel results based on test system running Intel Xeon w9-3475X, Intel Arc Pro B70 GPU, and 96GB of memory on Ubuntu 25.10. Nvidia results based on test system running Intel Xeon w9-3475X, Nvidia RTX PRO 4000 GPU, and 256GB of memory on Ubuntu 25.10. Results as of April 14, 2026 ↩
-
Benchmark testing based on measurement of token throughput while running GPT-OSS 20B LLM: https://huggingface.co/openai/gpt-oss-20b. Intel results based on test system running Intel Xeon w9-3475X, Intel Arc Pro B70 GPU, and 96GB of memory on Ubuntu 25.10. Nvidia results based on test system running Intel Xeon w9-3475X, Nvidia RTX PRO 4000 GPU, and 256GB of memory on Ubuntu 25.10. Results as of April 11, 2026 ↩
-
Benchmark testing based on measurement of KV cache capacity while running several separate LLMs, including: Gemma-4-E4B-it (https://huggingface.co/google/gemma-4-E4B-it), Gemma-3n-E4B-it (https://huggingface.co/google/gemma-3n-E4B-it), GPT-OSS 20B (https://huggingface.co/openai/gpt-oss-20b), Qwen3 4B Instruct 2507 (https://huggingface.co/Qwen/Qwen3-4B-Instruct-2507), Qwen3 8B (https://huggingface.co/Qwen/Qwen3-8B), and Qwen3.5-9B (https://huggingface.co/Qwen/Qwen3.5-9B). Intel results based on test system running Intel Xeon w9-3475X, Intel Arc Pro B70 GPU, and 96GB of memory on Ubuntu 25.10. Nvidia results based on test system running Intel Xeon w9-3475X, Nvidia RTX PRO 4000 GPU, and 256GB of memory on Ubuntu 25.10. Results as of April 14, 2026 ↩
-
Benchmark testing based on measurement of KV cache capacity while running several separate LLMs, including: Gemma-4-E4B-it (https://huggingface.co/google/gemma-4-E4B-it), Gemma-3n-E4B-it (https://huggingface.co/google/gemma-3n-E4B-it), GPT-OSS 20B (https://huggingface.co/openai/gpt-oss-20b), Qwen3 4B Instruct 2507 (https://huggingface.co/Qwen/Qwen3-4B-Instruct-2507), Qwen3 8B (https://huggingface.co/Qwen/Qwen3-8B), and Qwen3.5-9B (https://huggingface.co/Qwen/Qwen3.5-9B). Intel results based on test system running Intel Xeon w9-3475X, Intel Arc Pro B70 GPU, and 96GB of memory on Ubuntu 25.10. Nvidia results based on test system running Intel Xeon w9-3475X, Nvidia RTX PRO 4000 GPU, and 256GB of memory on Ubuntu 25.10. Results as of April 14, 2026 ↩