엔지니어링

왜 Backend.AI FastTrack 2가 필요한가?
2014년 Google이 발표한 논문1에 따르면, 머신러닝 시스템에는 수많은 기술 부채가 내재되어 있으며, 실제 머신러닝 시스템에서 학습 및 추론에 필요한 코드가 차지하는 비중은 매우 낮습니다. 대부분의 코드는 다양한 컴포넌트를 통합하는 목적으로 작성되고 있음을 보입니다23.
현실: 머신러닝 코드는 빙산의 일각일 뿐
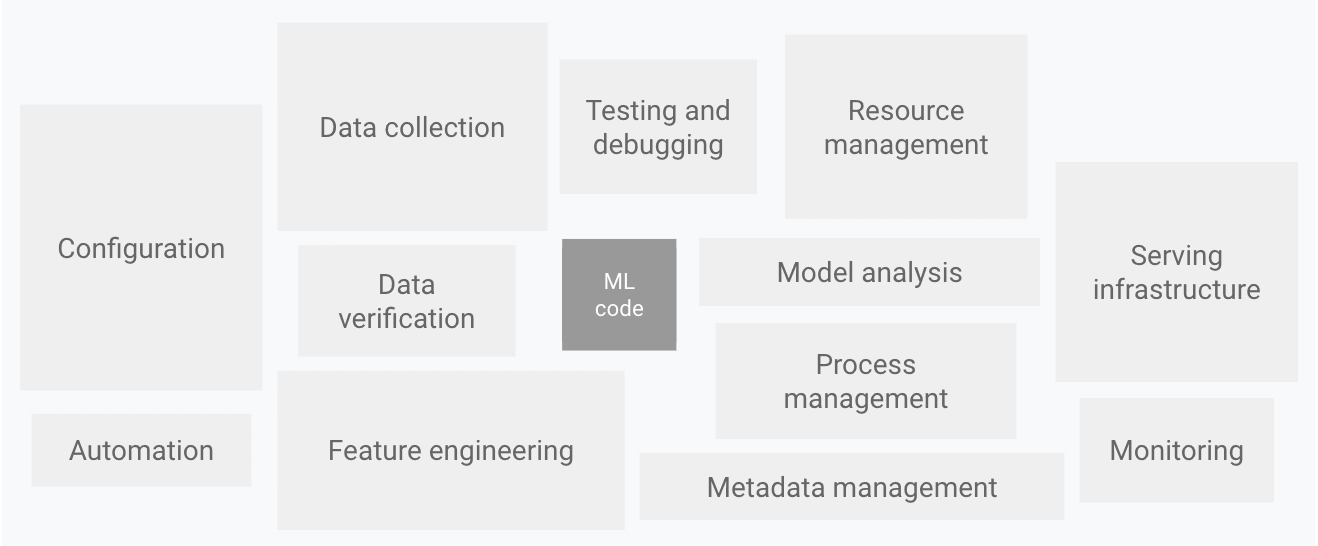 이미지 출처: Google Cloud - MLOps: Continuous delivery and automation pipelines in machine learning
이미지 출처: Google Cloud - MLOps: Continuous delivery and automation pipelines in machine learning
즉, 실제 머신러닝 코드는 빙산의 일각이고, 나머지는 모두 인프라, 모니터링, 데이터 파이프라인 등의 엔지니어링 작업입니다. 이러한 의존성 부채를 관리하고 체계적인 실험, 그리고 모니터링 및 알림을 가능하게 하는 MLOps 파이프라인이 나날이 중요해지고 있습니다.
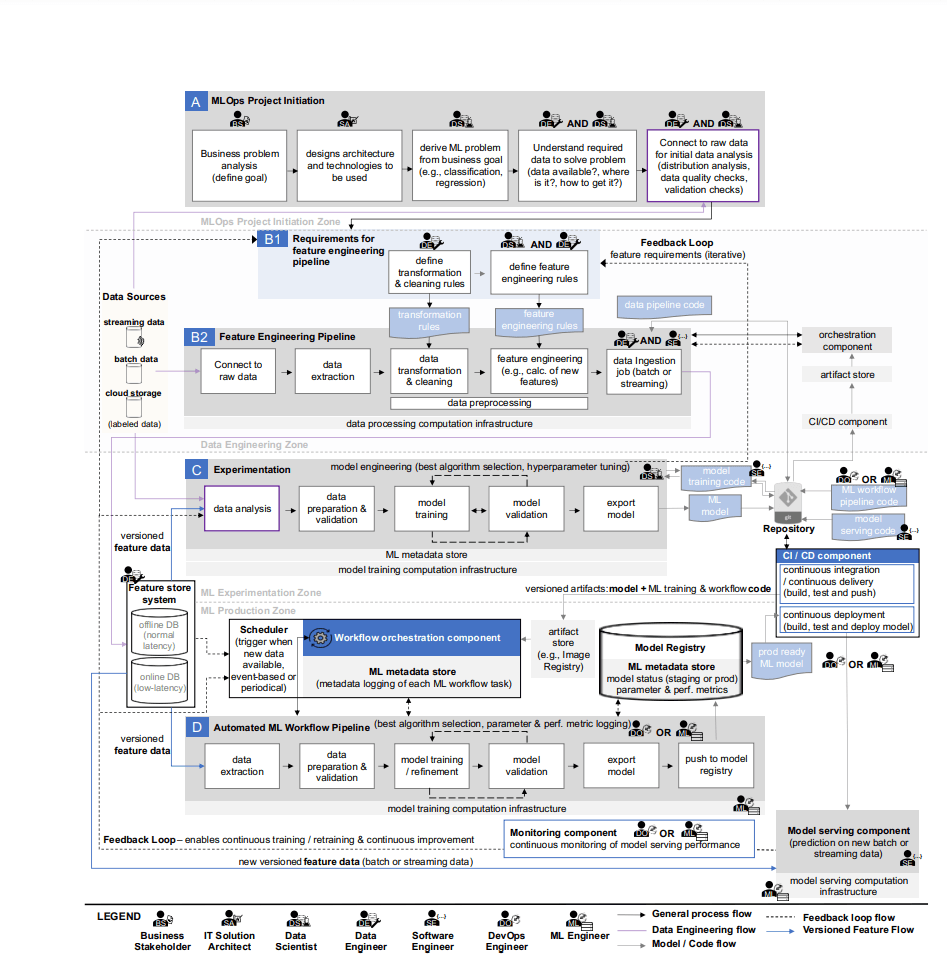 이미지 출처: Machine Learning Operations (MLOps): Overview, Definition, and Architecture
이미지 출처: Machine Learning Operations (MLOps): Overview, Definition, and Architecture
기존 MLOps 도구들의 한계
2023년에 발표된 한 리뷰 논문4에 따르면, 이미 Airflow5, Kubeflow6 등의 다양한 오픈소스 프로젝트들이 활발하게 사용되고 있습니다. 하지만 이들 도구들은 각각 고유한 한계를 가지고 있습니다:
- Airflow: 워크플로우 관리에는 탁월하지만, GPU 리소스 관리와 모델 서빙에는 추가 설정이 필요
- Kubeflow: 강력하지만 Kubernetes 전문 지식이 필요하고 설정이 복잡
- 기타 도구들: 각각 특정 영역에 특화되어 있어 통합된 경험을 제공하지 못함
문제의 핵심: 파편화된 ML 워크플로우
연구자와 엔지니어들은 다음과 같은 문제에 직면하고 있습니다.
- 복잡한 인프라 설정: 단순한 모델 학습을 위해 Docker, Kubernetes, 환경 변수 등 수많은 설정 필요
- GPU 리소스 관리의 어려움: 비싼 GPU 자원을 효율적으로 할당하고 관리하기 어려움
- 모델 서빙의 복잡성: 학습된 모델을 실제 서비스로 배포하기 위해 별도의 도구와 설정 필요
- 파편화된 워크플로우: 학습-검증-서빙 각 단계마다 다른 도구와 플랫폼 사용
해결책: Backend.AI FastTrack 2 모델 서빙
이러한 문제들을 해결하기 위해 Backend.AI는 이전 블로그에서 통합 모델 서빙 기능을 새롭게 소개했습니다. 이제 Backend.AI FastTrack 2에서도 모델 서빙 기능을 활용할 수 있어, 더욱 효율적인 AI 모델 배포와 관리가 가능해졌습니다.
모델 서빙이란? 학습된 ML 모델을 실제 운영 환경에서 API 엔드포인트로 배포하여, 실시간으로 추론 요청을 처리할 수 있게 하는 기능입니다. 이는 모델을 실제 비즈니스 가치로 전환하는 핵심 단계입니다.
이 통합으로 Backend.AI FastTrack 2는 아래와 같은 강력한 경쟁력을 제공합니다:
- ✅ 학습부터 서빙까지 원스톱: 모델 학습 → 검증 → 서빙까지 끊김 없는 파이프라인
- ✅ GPU 리소스 최적화: 자동 스케일링과 효율적인 GPU 할당
- ✅ 즉시 사용 가능한 API: 학습 완료 즉시 REST API 엔드포인트 제공
- ✅ 직관적인 UI: 웹 인터페이스에서 모든 작업 관리
 이미지 출처: Backend.AI 구조도
이미지 출처: Backend.AI 구조도
연구자들의 진정한 친구가 되다
Backend.AI FastTrack 2는 연구자들이 인프라 복잡성에 매몰되지 않고 본질적인 연구에 집중할 수 있도록 돕습니다. 더 이상 Docker 설정, Kubernetes 관리, 복잡한 배포 스크립트 작성에 시간을 낭비할 필요가 없습니다.

실제 사례: Airflow → Backend.AI FastTrack 2 마이그레이션
이번 블로그에서는 MNIST(Modified National Institute of Standards and Technology)7 분류 문제를 예시로 하여 기존에 Airflow로 운용하던 파이프라인을 어떻게 Backend.AI FastTrack 2에서 더 간단하고 효율적으로 구성할 수 있을지 보여드리겠습니다.
마이그레이션 전후 비교
| 구분 | Airflow | Backend.AI FastTrack 2 |
|---|---|---|
| 설정 복잡도 | Docker Compose, 환경 변수, 의존성 관리 | 웹 UI 클릭 몇 번 |
| GPU 관리 | 수동 설정 필요 | 자동 할당 및 최적화 |
| 모델 서빙 | 별도 도구 필요 (FastAPI, Gradio 등) | 통합 서빙 기능 |
| 운영 비용 | 높음 (복잡한 인프라 관리) | 낮음 (최적화된 리소스 사용) |
Airflow
Apache Airflow(이하 Airflow)는 2014년 Airbnb에서 개발된 오픈소스 워크플로 오케스트레이션 플랫폼입니다. 복잡한 데이터 파이프라인을 Python 코드로 정의하고 스케줄링할 수 있어 많은 기업에서 채택하고 있습니다.
본문에 포함된 예제는 Airflow 3.0.2 버전을 이용하여 작성되었습니다.
이번 블로그에서는 공식 Docker 이미지를 이용하여 Airflow를 실행합니다. Docker 환경에 익숙하지 않은 경우 Airflow 공식 문서를 참고하시기 바랍니다.
Airflow 초기 설정
Airflow를 사용하기 위해서는 여러 설정 파일이 필요합니다. 실제 예제를 통해 살펴보겠습니다.
[core] # https://airflow.apache.org/docs/apache-airflow/stable/configurations-ref.html#core
auth_manager=airflow.api_fastapi.auth.managers.simple.simple_auth_manager.SimpleAuthManager
simple_auth_manager_users = admin:admin,user:user
simple_auth_manager_passwords_file = ./passwords.json
dags_folder = /opt/airflow/dags
[api] # https://airflow.apache.org/docs/apache-airflow/stable/configurations-ref.html#api
host=0.0.0.0
port=8080
[api_auth] # https://airflow.apache.org/docs/apache-airflow/stable/configurations-ref.html#api-auth
jwt_secret={JWT_SECRET_KEY}
[secrets]
backend = airflow.secrets.local_filesystem.LocalFilesystemBackendPYTHONPATH=/opt/airflow/dags:$PYTHONPATH airflow standaloneservices:
airflow:
image: apache/airflow:3.0.2-python3.12
ports:
- 8080:8080
environment:
AIRFLOW_HOME: /opt/airflow
volumes:
- .:/opt/airflow
- ./dags/mnist/v1/.env:/opt/airflow/dags/mnist/v1/.env:ro
entrypoint: /opt/airflow/compose/entrypoint.sh컨테이너 실행 및 초기화
# Docker 컨테이너 시작
$ docker compose -f docker-compose.yaml up -d
# 데이터베이스 초기화
$ docker exec -it <container_id> airflow db reset -y이제 기본 주소(http://127.0.0.1:8080)를 통해 Airflow에 접속한 후, passwords.json에 생성된 계정 인증 정보를 통해 로그인합니다.
{"admin": "7PdAaKvPb3E3fasz", "user": "USmGxuNAvvCRuyYs"} Airflow - 로그인 화면
Airflow - 로그인 화면
이후 좌측 Dags 메뉴를 클릭하여 DAG 목록이 비어 있음을 확인할 수 있습니다.
 Airflow - DAG 목록 화면
Airflow - DAG 목록 화면
DAG 작성
Airflow에서는 DAG(Directed Acyclic Graph)를 Python 코드로 정의합니다. MNIST 데이터셋 다운로드와 모델 학습을 수행하는 DAG를 작성해보겠습니다.
import os
from datetime import datetime, timedelta, timezone
from airflow.providers.standard.operators.python import PythonVirtualenvOperator
from airflow.sdk import DAG
HF_TOKEN = os.getenv("HF_TOKEN")
with DAG(
dag_id="mnist",
default_args={
"depends_on_past": False,
"retries": 1,
"retry_delay": timedelta(minutes=5),
},
description="PyTorch MNIST classifcation example DAG",
params={
"hf_token": HF_TOKEN,
},
start_date=datetime.now(timezone.utc) + timedelta(seconds=10),
catchup=False,
tags=["example"],
) as dag:
def download_mnist_dataset(**kwargs) -> None:
import os
from pathlib import Path
import datasets
AIRFLOW_HOME = os.getenv("AIRFLOW_HOME", "/opt/airflow")
dataset_path = Path(AIRFLOW_HOME) / "datasets" / "mnist"
if not dataset_path.exists():
dataset_path.mkdir(parents=True, exist_ok=True)
dataset = datasets.load_dataset(
"ylecun/mnist",
token=kwargs.get("hf_token"),
)
dataset.save_to_disk(dataset_path)
download_mnist_dataset_task = PythonVirtualenvOperator(
task_id="download_mnist_dataset",
python_callable=download_mnist_dataset,
requirements=["datasets"],
system_site_packages=False,
op_kwargs={
"params": {
"hf_token": dag.params.get("hf_token"),
},
},
)
def train_mnist_model(**kwargs) -> None:
import os
from pathlib import Path
import torch
import torch.optim as optim
from torchvision import datasets, transforms
from torch.optim.lr_scheduler import StepLR
from mnist.v1.models import Net
from mnist.v1.trainer import Trainer
AIRFLOW_HOME = os.getenv("AIRFLOW_HOME", "/opt/airflow")
dataset_path = Path(AIRFLOW_HOME) / "datasets" / "mnist"
use_accel = not kwargs["params"]["no_accel"] and torch.accelerator.is_available()
torch.manual_seed(kwargs["params"]["seed"])
if use_accel:
device = torch.accelerator.current_accelerator()
else:
device = torch.device("cpu")
train_kwargs = {"batch_size": kwargs["params"]["batch_size"]}
test_kwargs = {"batch_size": kwargs["params"]["test_batch_size"]}
if use_accel:
accel_kwargs = {
"num_workers": 1,
"pin_memory": True,
"shuffle": True,
}
train_kwargs.update(accel_kwargs)
test_kwargs.update(accel_kwargs)
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])
dataset1 = datasets.MNIST(dataset_path, train=True, download=True, transform=transform)
dataset2 = datasets.MNIST(dataset_path, train=False, transform=transform)
train_loader = torch.utils.data.DataLoader(dataset1, **train_kwargs)
test_loader = torch.utils.data.DataLoader(dataset2, **test_kwargs)
model = Net().to(device)
optimizer = optim.Adadelta(model.parameters(), lr=kwargs["params"]["lr"])
scheduler = StepLR(optimizer, step_size=1, gamma=kwargs["params"]["gamma"])
trainer = Trainer(model)
class AttributeDict(dict):
def __getattr__(self, item):
return self[item]
for epoch in range(1, kwargs["params"]["epochs"] + 1):
trainer.train(AttributeDict(kwargs["params"]), device, train_loader, optimizer, epoch)
trainer.test(device, test_loader)
scheduler.step()
if kwargs["params"]["save_model"]:
torch.save(model.state_dict(), "mnist_cnn.ckpt")
train_mnist_model_task = PythonVirtualenvOperator(
task_id="train_mnist_model",
python_callable=train_mnist_model,
requirements=["torch", "torchvision"],
system_site_packages=False,
op_kwargs={
"params": {
"lr": 1.0,
"epochs": 14,
"batch_size": 64,
"test_batch_size": 1000,
"gamma": 0.7,
"no_accel": False,
"dry_run": False,
"seed": 1,
"log_interval": 10,
"save_model": True,
},
},
)
download_mnist_dataset_task >> train_mnist_model_taskimport torch
import torch.nn as nn
import torch.nn.functional as F
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(1, 32, 3, 1)
self.conv2 = nn.Conv2d(32, 64, 3, 1)
self.dropout1 = nn.Dropout(0.25)
self.dropout2 = nn.Dropout(0.5)
self.fc1 = nn.Linear(9216, 128)
self.fc2 = nn.Linear(128, 10)
def forward(self, x):
x = self.conv1(x)
x = F.relu(x)
x = self.conv2(x)
x = F.relu(x)
x = F.max_pool2d(x, 2)
x = self.dropout1(x)
x = torch.flatten(x, 1)
x = self.fc1(x)
x = F.relu(x)
x = self.dropout2(x)
x = self.fc2(x)
output = F.log_softmax(x, dim=1)
return outputimport torch
import torch.nn.functional as F
import torch.optim as optim
class Trainer:
def __init__(self, model: torch.nn.Module) -> None:
self._model = model
def train(
self,
args,
device: torch.device,
train_loader: torch.utils.data.DataLoader,
optimizer: optim.Optimizer,
epoch: int,
) -> None:
self._model.train()
for batch_idx, (data, target) in enumerate(train_loader):
data, target = data.to(device), target.to(device)
optimizer.zero_grad()
output = self._model(data)
loss = F.nll_loss(output, target)
loss.backward()
optimizer.step()
if batch_idx % args.log_interval == 0:
print("Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}".format(
epoch,
batch_idx * len(data),
len(train_loader.dataset),
100. * batch_idx / len(train_loader),
loss.item(),
))
if args.dry_run:
break
def test(
self,
device: torch.device,
test_loader: torch.utils.data.DataLoader,
) -> None:
self._model.eval()
test_loss = 0
correct = 0
with torch.no_grad():
for data, target in test_loader:
data, target = data.to(device), target.to(device)
output = self._model(data)
test_loss += F.nll_loss(output, target, reduction="sum").item()
pred = output.argmax(dim=1, keepdim=True)
correct += pred.eq(target.view_as(pred)).sum().item()
test_loss /= len(test_loader.dataset)
print("\nTest set: Average loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)\n".format(
test_loss,
correct,
len(test_loader.dataset),
100. * correct / len(test_loader.dataset),
))이후 작성한 DAG 스크립트를 실행하여 Airflow에 등록합니다.
$ docker exec -it <container_id> python dags/mnist/v1/dag.py Airflow - DAG 목록 화면
Airflow - DAG 목록 화면
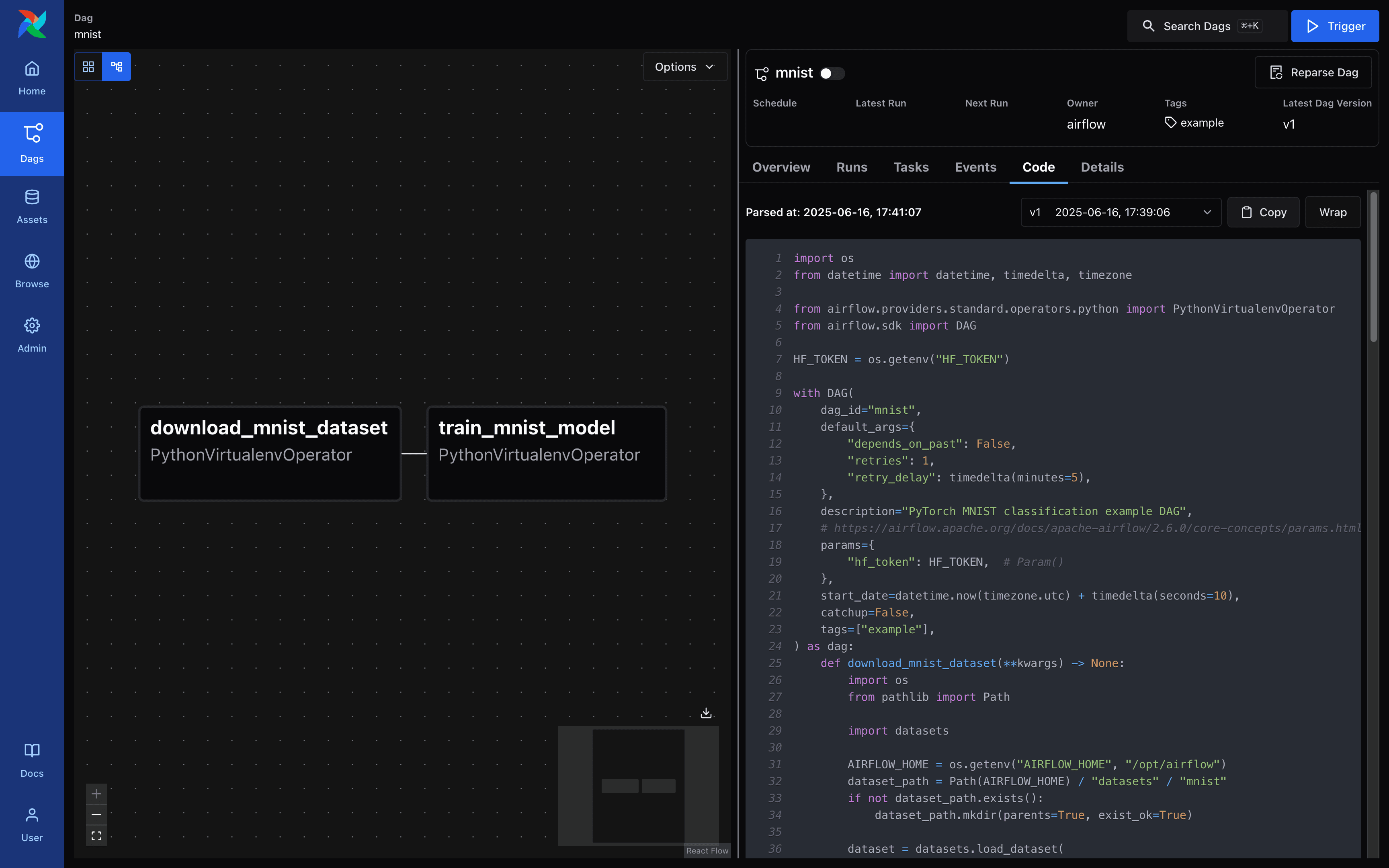 Airflow - DAG 세부 정보 화면
Airflow - DAG 세부 정보 화면
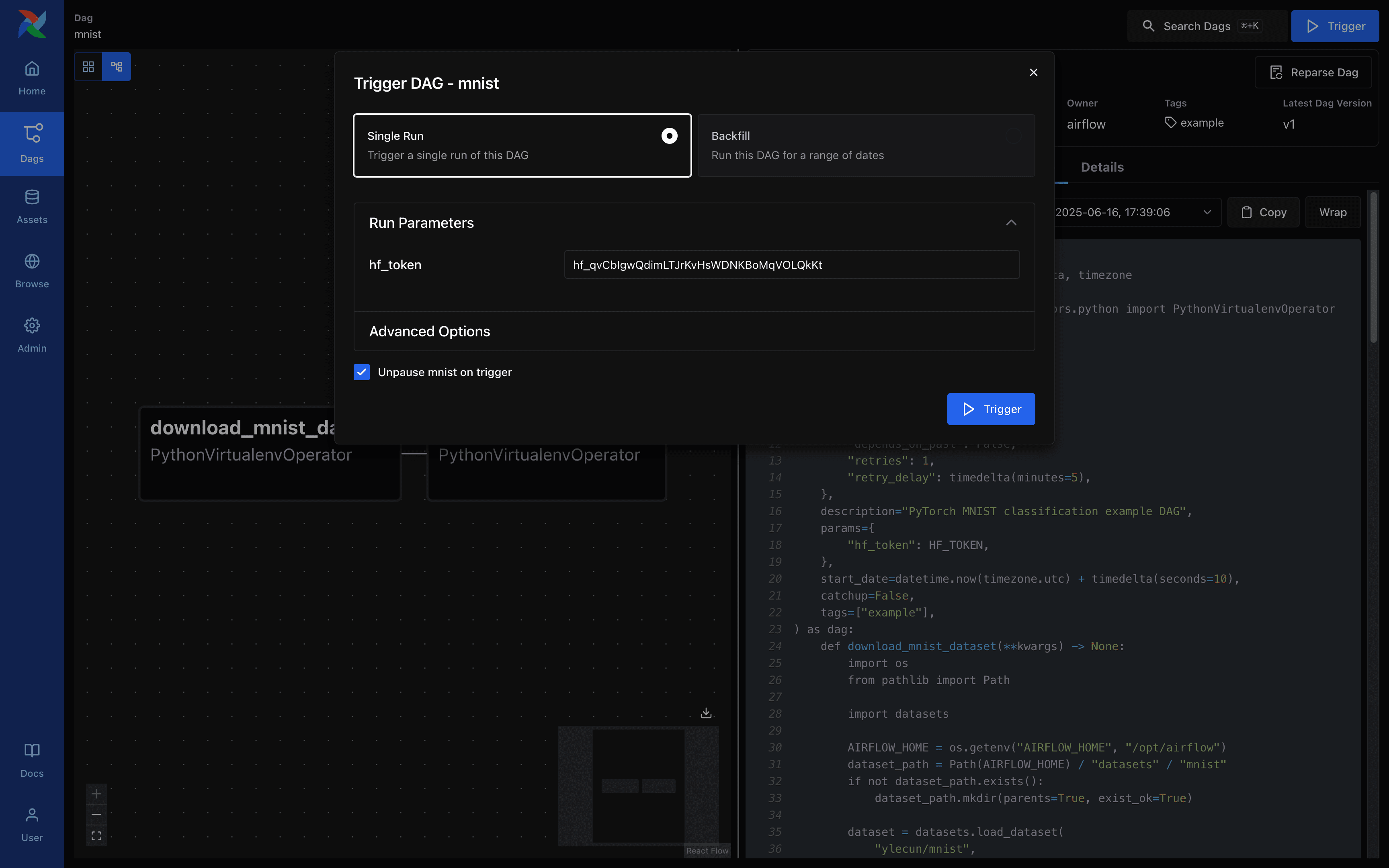 Airflow - DAG 실행 요청 화면
Airflow - DAG 실행 요청 화면
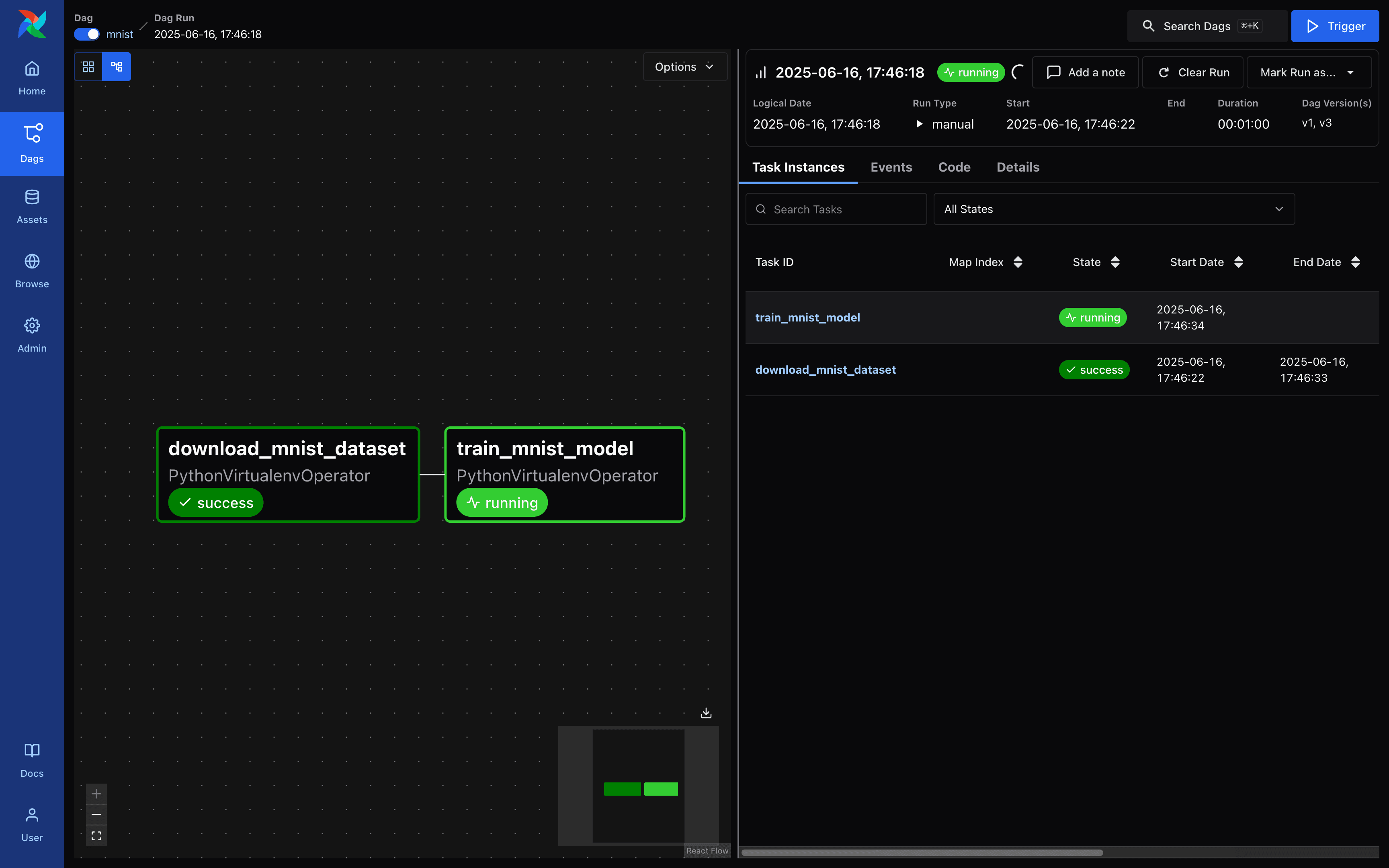 Airflow - DAG 실행 요청 화면
Airflow - DAG 실행 요청 화면
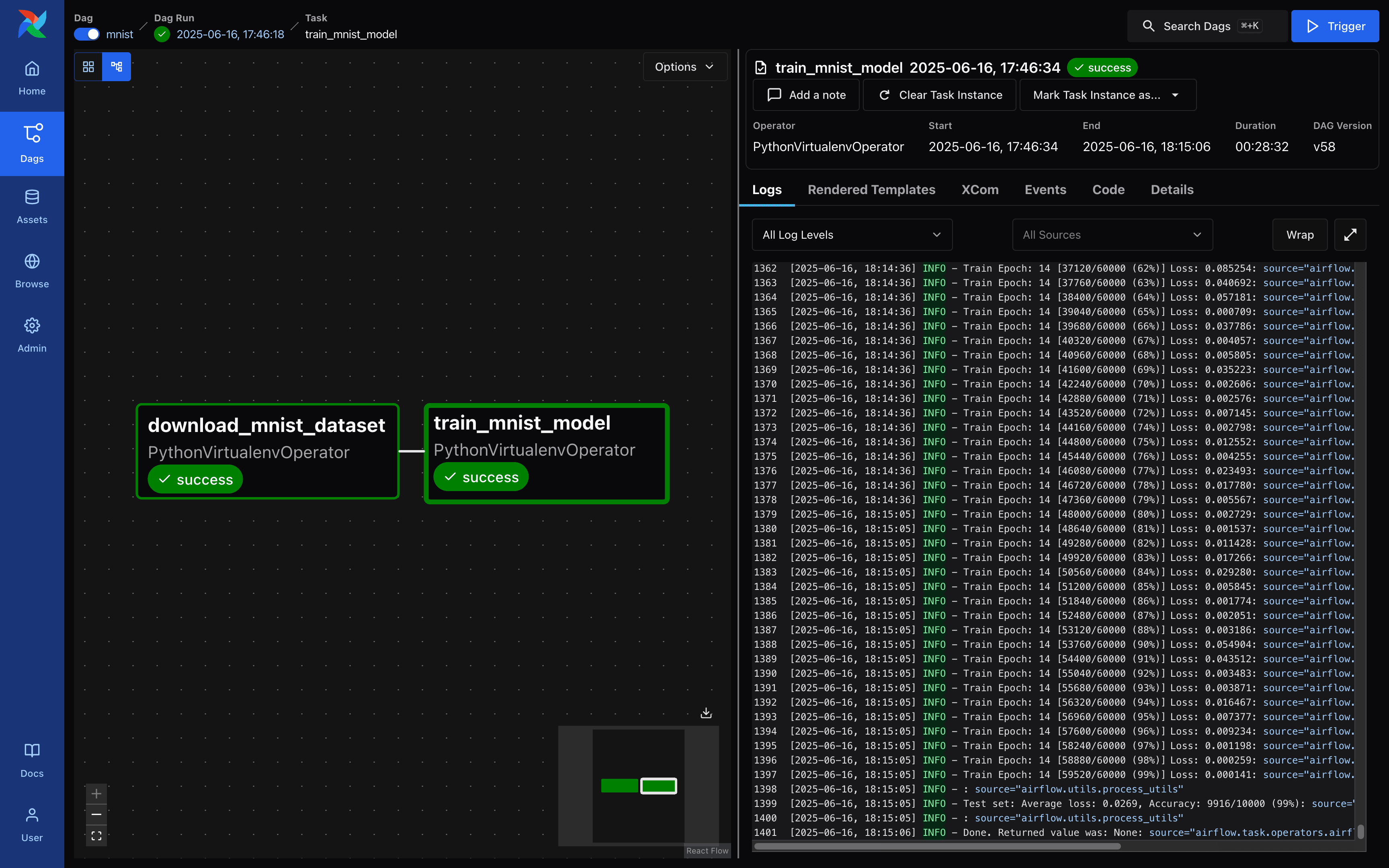 Airflow - DAG 실행 요청 화면
Airflow - DAG 실행 요청 화면
모델 학습이 완료되면 mnist_cnn.ckpt 파일이 생성된 것을 확인할 수 있습니다. 이후 아래와 같이 MNIST 모델을 실험해 볼 수 있는 간단한 Gradio 데모를 작성한 후 실행합니다.
$ pip install fastapi==0.115.12 gradio==5.33.0 torch==2.7.1 torchvision==0.22.1from http import HTTPStatus
from pathlib import Path
import gradio
import numpy as np
import torch
from fastapi import FastAPI, Response
from fastapi.responses import JSONResponse
from torchvision import transforms
from models import Net
model = Net()
model.load_state_dict(torch.load(Path(__file__).parent.parent.parent / "mnist_cnn.ckpt"))
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,)),
transforms.Grayscale(),
])
app = FastAPI()
@app.get("/health", status_code=HTTPStatus.OK)
async def health_check() -> Response:
return JSONResponse({"healthy": True})
def fn(img: np.ndarray) -> int:
x = transform(img).unsqueeze(0)
x = model(x)
x = x.argmax(dim=1, keepdim=True)
return int(x.item())
gradio_app = gradio.Interface(
fn=fn,
inputs=["image"],
outputs=["number"],
)
app = gradio.mount_gradio_app(app, gradio_app, path="/")$ fastapi run model-defs/gradio/main.py
FastAPI Starting production server 🚀
Searching for package file structure from directories with __init__.py files
Importing from /Users/rapsealk/Desktop/git/airflow-demo/model-defs/gradio
module 🐍 main.py
code Importing the FastAPI app object from the module with the following code:
from main import app
app Using import string: main:app
server Server started at http://0.0.0.0:8000
server Documentation at http://0.0.0.0:8000/docs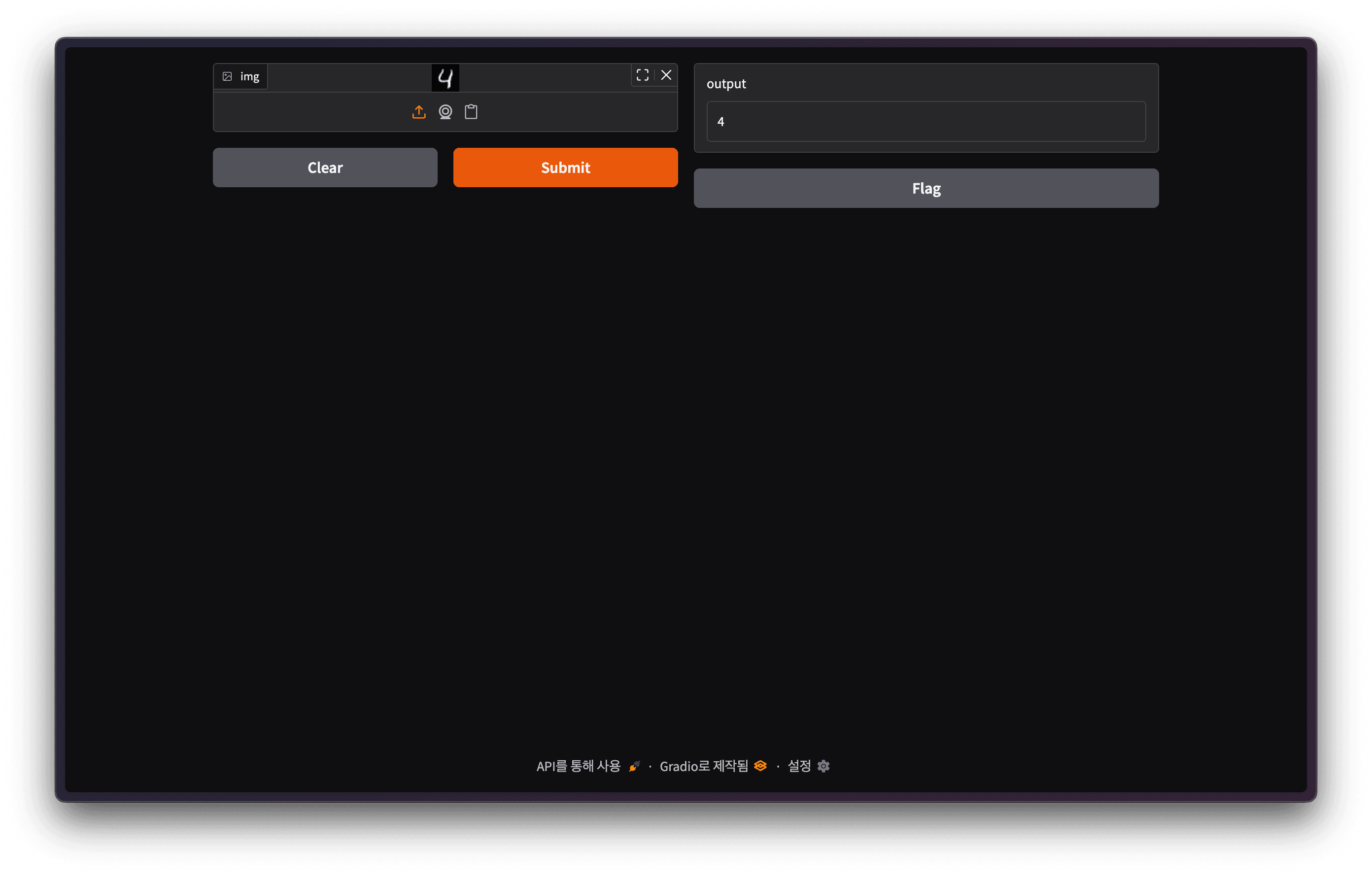 Gradio 데모 화면
Gradio 데모 화면
Backend.AI FastTrack 2
이번에는 Backend.AI FastTrack 2를 이용하여 MNIST 학습 및 배포 파이프라인을 작성해 보겠습니다. Backend.AI FastTrack 2 파이프라인에 익숙하지 않은 경우 이전 블로그를 참고하시기 바랍니다.
본문에 포함된 예제는 Backend.AI FastTrack 2 v25.9.0를 이용하여 작성되었습니다.
Backend.AI FastTrack 2에 접속한 후 로그인 버튼을 클릭합니다. Backend.AI FastTrack 2는 Backend.AI 계정을 통해 접속할 수 있습니다.
 Backend.AI FastTrack 2 로그인 화면
Backend.AI FastTrack 2 로그인 화면
 Backend.AI 로그인 화면
Backend.AI 로그인 화면
 Backend.AI FastTrack 2 메인 화면
Backend.AI FastTrack 2 메인 화면
새 파이프라인 만들기
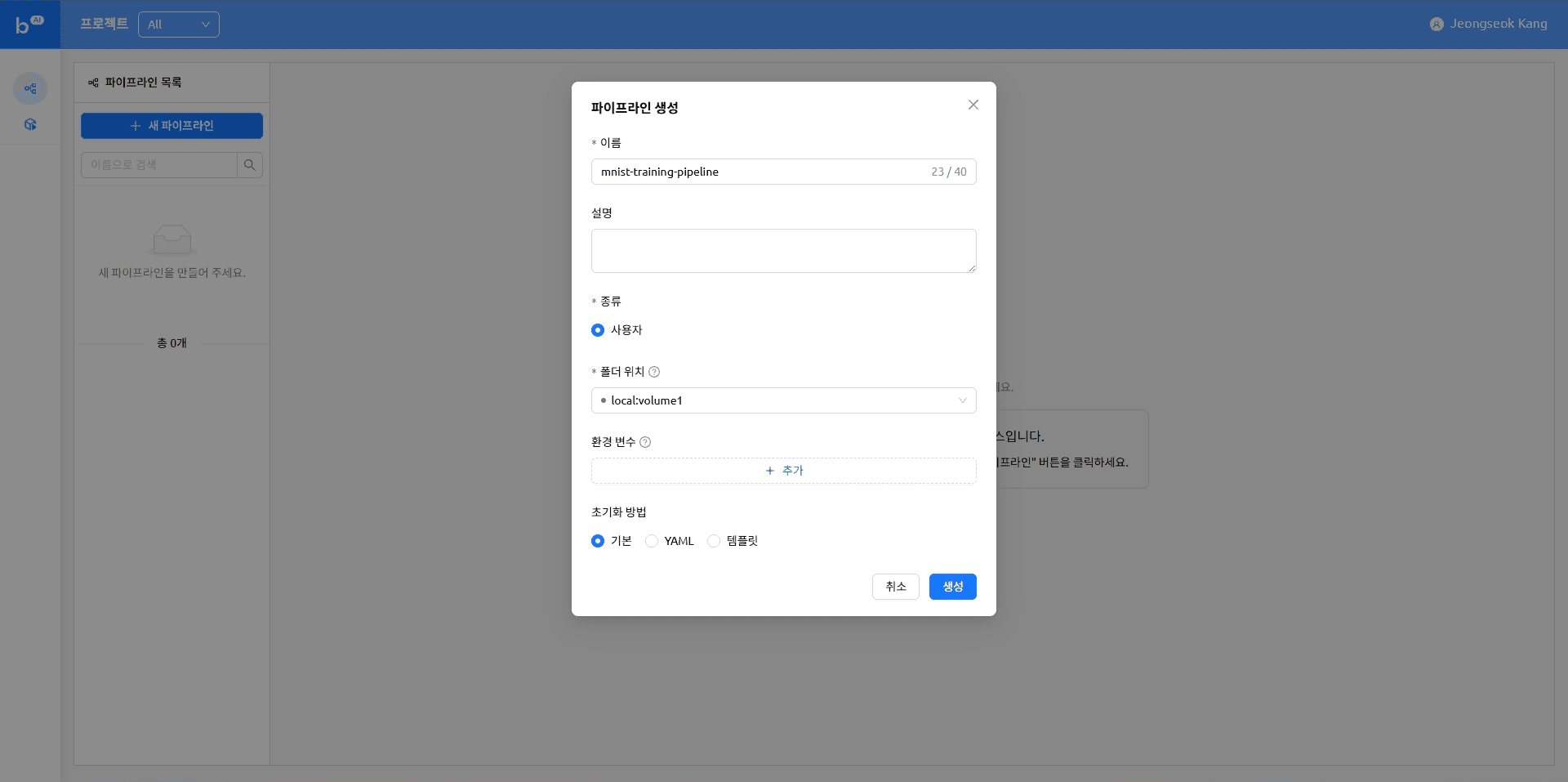
파일 업로드
이번에 작성하는 파이프라인은 VFolder에 저장된 Python 스크립트를 실행하도록 되어 있습니다. 이번 목차에서는 파이프라인 실행에 필요한 파일을 업로드하는 방법을 다룹니다.
Backend.AI 메인 화면에서 좌측 메뉴에 있는 '데이터' 항목을 클릭합니다.
 Backend.AI 메인 화면
Backend.AI 메인 화면
파이프라인을 생성하며 만들어진 파이프라인 폴더를 확인할 수 있습니다. 파이프라인 폴더를 클릭한 후 파일을 업로드합니다.
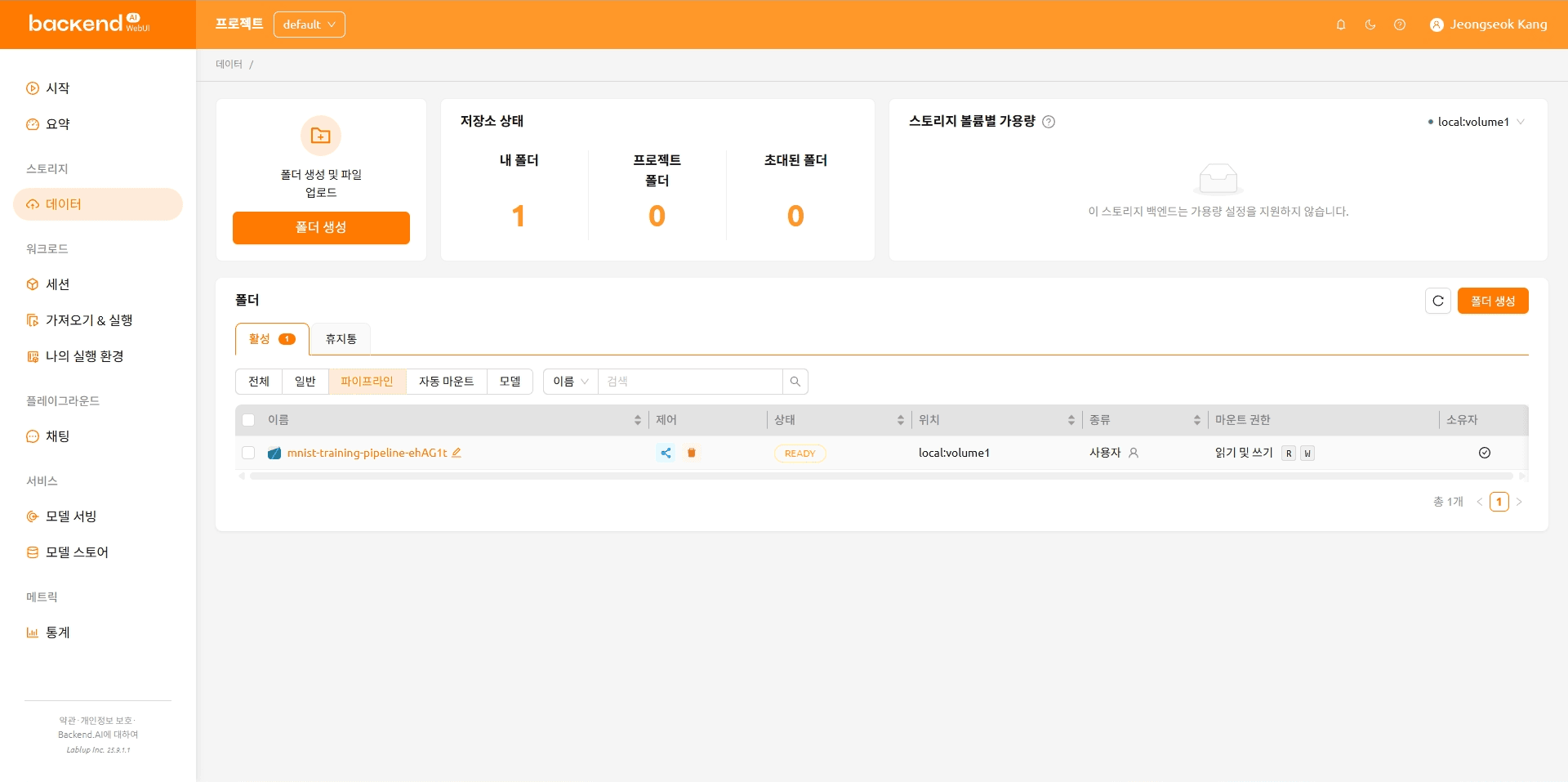 VFolder 목록
VFolder 목록
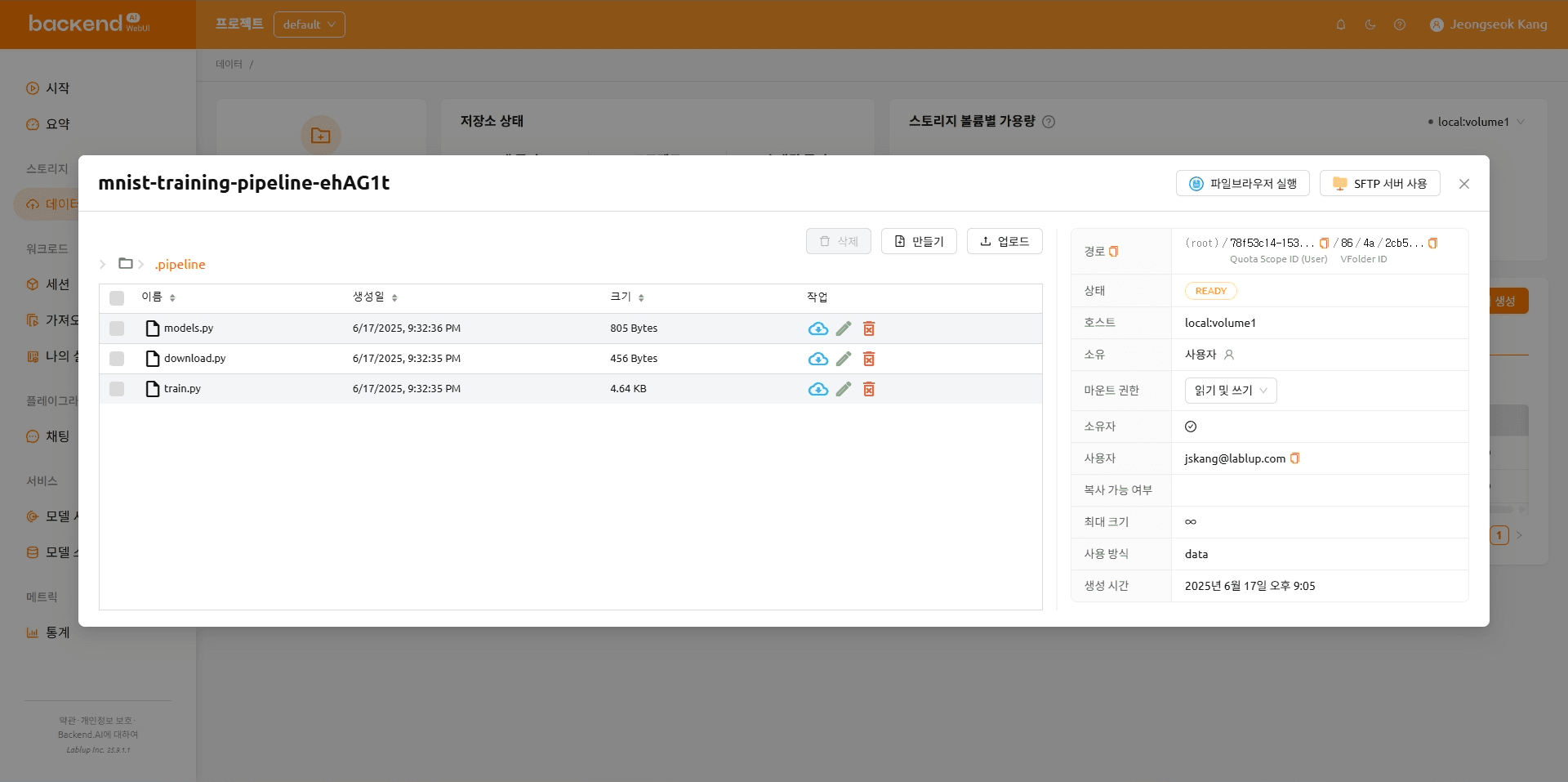 파일 업로드가 완료된 후의 폴더
파일 업로드가 완료된 후의 폴더
파일이 업로드된 후의 폴더 구성은 아래와 같습니다.
mnist-training-pipeline-ehAG1t
|---- .pipeline
|---- model.py
|---- download.py
\---- train.py
import torch
import torch.nn as nn
import torch.nn.functional as F
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(1, 32, 3, 1)
self.conv2 = nn.Conv2d(32, 64, 3, 1)
self.dropout1 = nn.Dropout(0.25)
self.dropout2 = nn.Dropout(0.5)
self.fc1 = nn.Linear(9216, 128)
self.fc2 = nn.Linear(128, 10)
def forward(self, x):
x = self.conv1(x)
x = F.relu(x)
x = self.conv2(x)
x = F.relu(x)
x = F.max_pool2d(x, 2)
x = self.dropout1(x)
x = torch.flatten(x, 1)
x = self.fc1(x)
x = F.relu(x)
x = self.dropout2(x)
x = self.fc2(x)
output = F.log_softmax(x, dim=1)
return outputimport os
from pathlib import Path
from torchvision import datasets
MNIST_DATASET_PATH = Path("/pipeline/vfroot") / os.getenv("MNIST_DATASET_PATH", "")
def main() -> None:
train_dataset = datasets.MNIST(MNIST_DATASET_PATH, train=True, download=True)
print(f"Train dataset is saved at: {train_dataset}")
test_dataset = datasets.MNIST(MNIST_DATASET_PATH, train=False, download=True)
print(f"Test dataset is saved at: {test_dataset}")
if __name__ == "__main__":
main()import argparse
import os
from pathlib import Path
import torch
import torch.nn.functional as F
import torch.optim as optim
from torchvision import datasets, transforms
from torch.optim.lr_scheduler import StepLR
from models import Net
MNIST_DATASET_PATH = Path("/pipeline/vfroot") / os.getenv("MNIST_DATASET_PATH", "")
CHECKPOINT_PATH = Path(os.getenv("CHECKPOINT_PATH")).joinpath(os.getenv("BACKENDAI_PIPELINE_JOB_ID", "mnist_cnn")).with_suffix(".ckpt")
def parse_args():
parser = argparse.ArgumentParser(description="Train MNIST model")
parser.add_argument("--lr", type=float, default=1.0, help="Learning rate")
parser.add_argument("--epochs", type=int, default=14, help="Number of epochs to train")
parser.add_argument("--batch-size", type=int, default=64, help="Batch size for training")
parser.add_argument("--test-batch-size", type=int, default=1000, help="Batch size for testing")
parser.add_argument("--gamma", type=float, default=0.7, help="Learning rate step gamma")
parser.add_argument("--no-accel", action="store_true", help="Disable GPU acceleration")
parser.add_argument("--dry-run", action="store_true", help="Run without saving the model")
parser.add_argument("--seed", type=int, default=1, help="Random seed for reproducibility")
parser.add_argument("--log-interval", type=int, default=10, help="Interval for logging training progress")
parser.add_argument("--save-model", action="store_true", help="Save the trained model")
return parser.parse_args()
def train(args, model, device, train_loader, optimizer, epoch):
model.train()
for batch_idx, (data, target) in enumerate(train_loader):
data, target = data.to(device), target.to(device)
optimizer.zero_grad()
output = model(data)
loss = F.nll_loss(output, target)
loss.backward()
optimizer.step()
if batch_idx % args.log_interval == 0:
print("Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}".format(
epoch,
batch_idx * len(data),
len(train_loader.dataset),
100. * batch_idx / len(train_loader),
loss.item(),
))
if args.dry_run:
break
def test(model, device, test_loader):
model.eval()
test_loss = 0
correct = 0
with torch.no_grad():
for data, target in test_loader:
data, target = data.to(device), target.to(device)
output = model(data)
test_loss += F.nll_loss(output, target, reduction='sum').item() # sum up batch loss
pred = output.argmax(dim=1, keepdim=True) # get the index of the max log-probability
correct += pred.eq(target.view_as(pred)).sum().item()
test_loss /= len(test_loader.dataset)
print("\nTest set: Average loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)\n".format(
test_loss,
correct,
len(test_loader.dataset),
100. * correct / len(test_loader.dataset),
))
def main(args) -> None:
use_accel = not args.no_accel and torch.accelerator.is_available()
torch.manual_seed(args.seed)
if use_accel:
device = torch.accelerator.current_accelerator()
else:
device = torch.device("cpu")
train_kwargs = {"batch_size": args.batch_size}
test_kwargs = {"batch_size": args.test_batch_size}
if use_accel:
accel_kwargs = {
"num_workers": 1,
"pin_memory": True,
"shuffle": True,
}
train_kwargs.update(accel_kwargs)
test_kwargs.update(accel_kwargs)
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])
dataset1 = datasets.MNIST(MNIST_DATASET_PATH, train=True, download=True, transform=transform)
dataset2 = datasets.MNIST(MNIST_DATASET_PATH, train=False, transform=transform)
train_loader = torch.utils.data.DataLoader(dataset1,**train_kwargs)
test_loader = torch.utils.data.DataLoader(dataset2, **test_kwargs)
model = Net().to(device)
optimizer = optim.Adadelta(model.parameters(), lr=args.lr)
scheduler = StepLR(optimizer, step_size=1, gamma=args.gamma)
for epoch in range(1, args.epochs + 1):
train(args, model, device, train_loader, optimizer, epoch)
test(model, device, test_loader)
scheduler.step()
if args.save_model:
CHECKPOINT_PATH.parent.mkdir(parents=True, exist_ok=True)
torch.save(model.state_dict(), CHECKPOINT_PATH)
if __name__ == "__main__":
args = parse_args()
main(args)모델 폴더를 생성한 후 아래 파일을 업로드합니다.
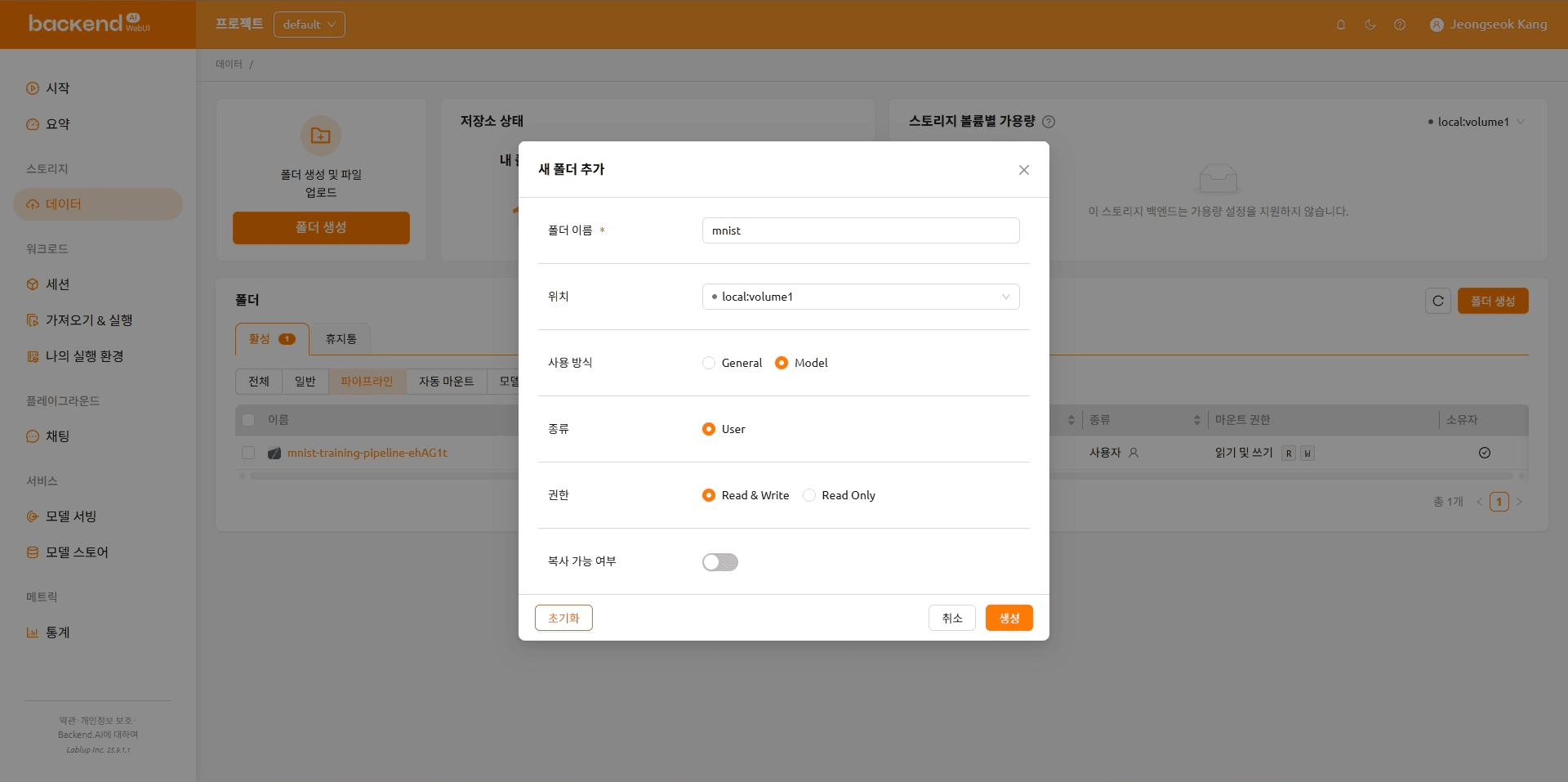 모델 폴더 생성
모델 폴더 생성
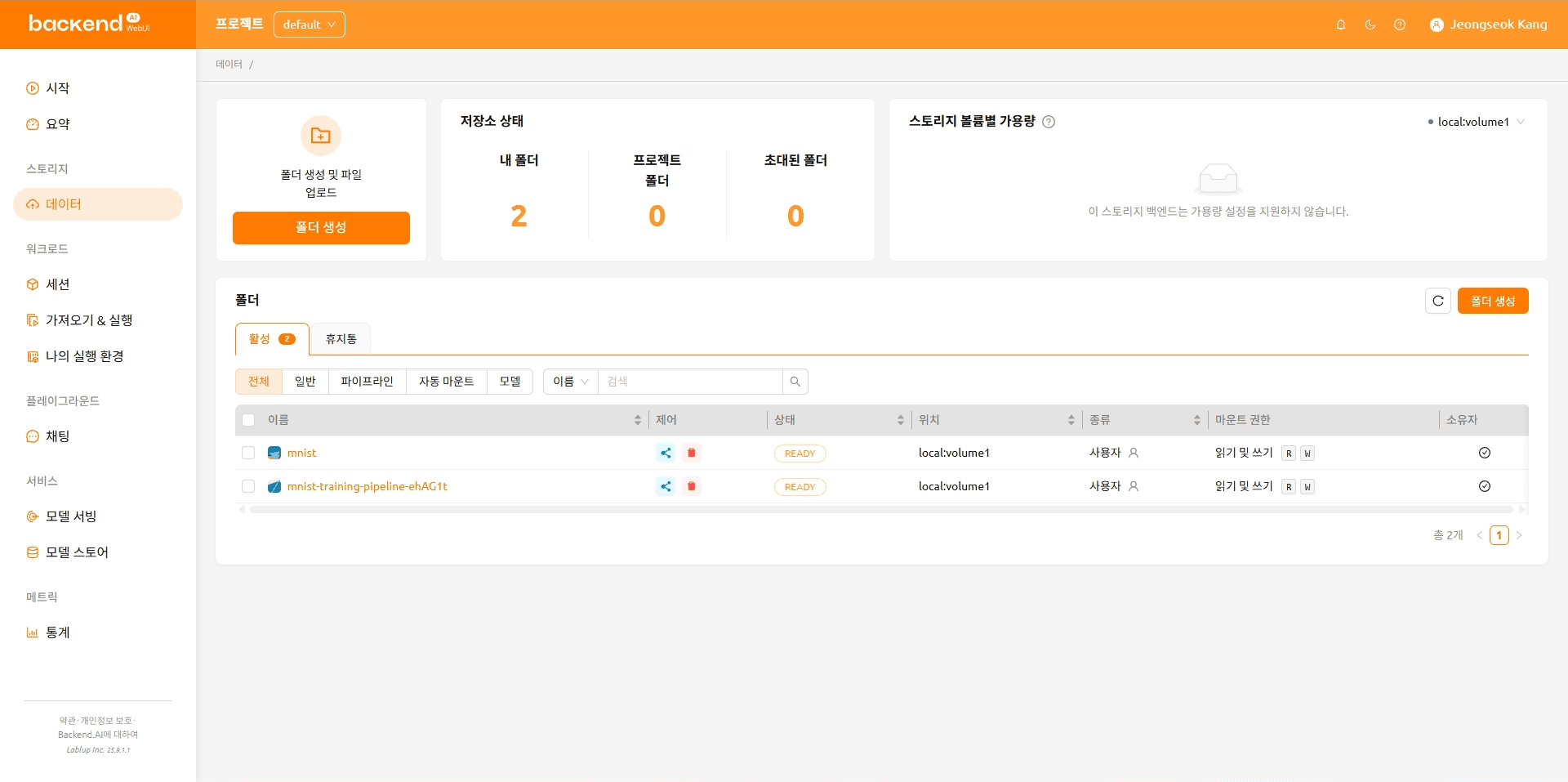
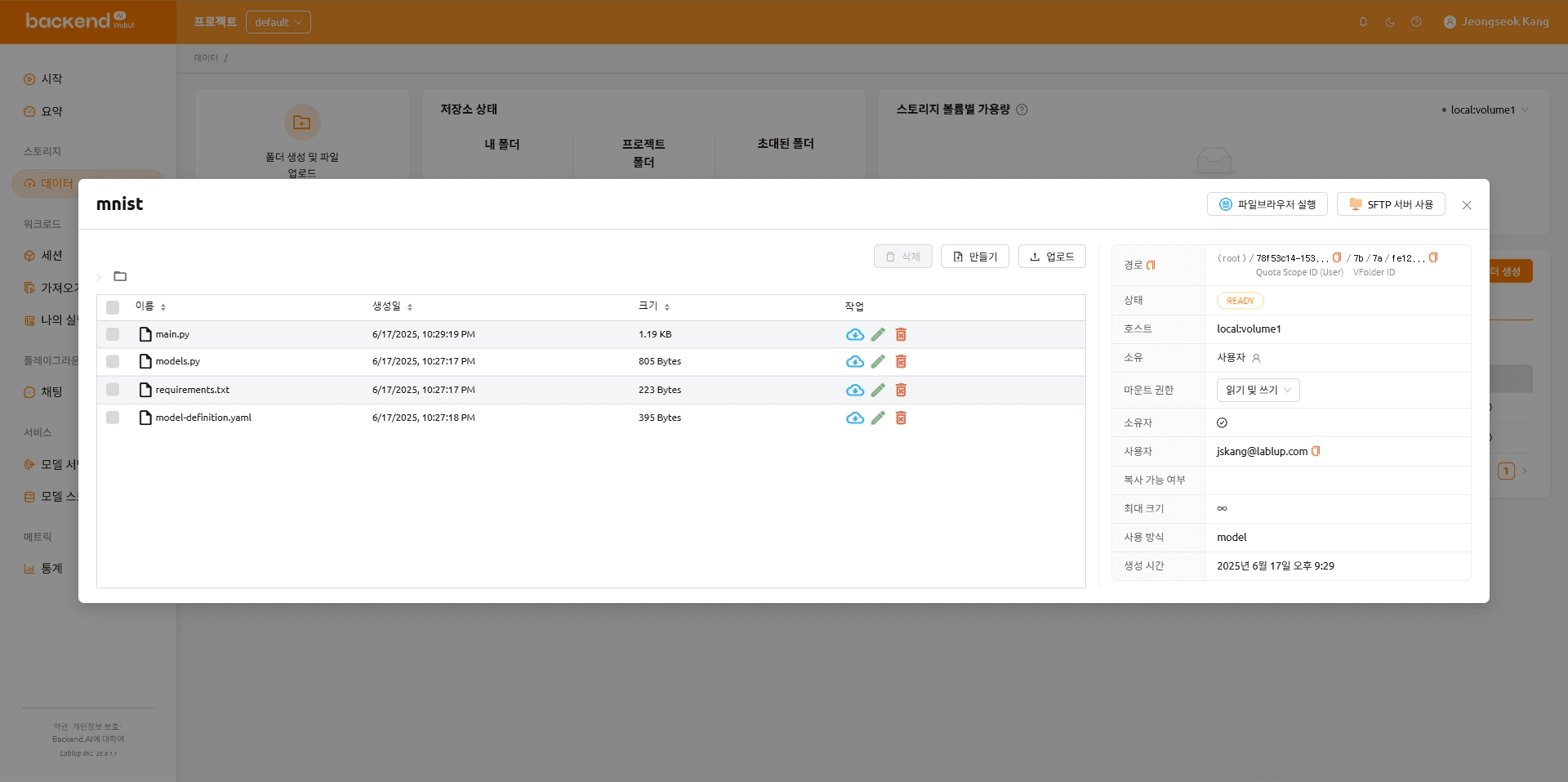
파일이 업로드된 후의 폴더 구성은 아래와 같습니다.
mnist
|---- main.py
|---- models.py
|---- requirements.txt
\---- model-definition.yaml
import os
from http import HTTPStatus
from pathlib import Path
import gradio
import numpy as np
import torch
from fastapi import FastAPI, Response
from fastapi.responses import JSONResponse
from torchvision import transforms
from models import Net
CHECKPOINT_PATH = Path(os.getenv("CHECKPOINT_PATH")).joinpath(os.getenv("BACKENDAI_PIPELINE_JOB_ID", "mnist_cnn")).with_suffix(".ckpt")
model = Net()
model.load_state_dict(torch.load(CHECKPOINT_PATH))
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,)),
transforms.Grayscale(),
])
app = FastAPI()
@app.get("/health", status_code=HTTPStatus.OK)
async def health_check() -> Response:
return JSONResponse({"healthy": True})
def fn(img: np.ndarray) -> int:
x = transform(img).unsqueeze(0) # Add batch dimension
x = model(x)
x = x.argmax(dim=1, keepdim=True) # Get the index of the max log-probability
return int(x.item()) # Convert tensor to int and return
gradio_app = gradio.Interface(
fn=fn,
inputs=["image"],
outputs=["number"],
)
app = gradio.mount_gradio_app(app, gradio_app, path="/")import torch
import torch.nn as nn
import torch.nn.functional as F
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(1, 32, 3, 1)
self.conv2 = nn.Conv2d(32, 64, 3, 1)
self.dropout1 = nn.Dropout(0.25)
self.dropout2 = nn.Dropout(0.5)
self.fc1 = nn.Linear(9216, 128)
self.fc2 = nn.Linear(128, 10)
def forward(self, x):
x = self.conv1(x)
x = F.relu(x)
x = self.conv2(x)
x = F.relu(x)
x = F.max_pool2d(x, 2)
x = self.dropout1(x)
x = torch.flatten(x, 1)
x = self.fc1(x)
x = F.relu(x)
x = self.dropout2(x)
x = self.fc2(x)
output = F.log_softmax(x, dim=1)
return outputfastapi[standard]==0.115.12 # https://github.com/fastapi/fastapi
gradio==5.33.0 # https://github.com/gradio-app/gradio
torch==2.7.1 # https://github.com/pytorch/pytorch
torchvision==0.22.1 # https://github.com/pytorch/visionmodels:
- name: mnist-gradio-demo
model_path: /models
service:
pre_start_actions:
- action: run_command
args:
command: ["pip", "install", "-r", "/models/requirements.txt"]
start_command:
- fastapi
- run
- /models/main.py
port: 8000
health_check:
path: /health
max_retries: 5작업 추가하기
다시 Backend.AI FastTrack 2로 돌아와 파이프라인에 순서대로 작업을 추가합니다.
아래와 같이 작업 템플릿 목록에서 원하는 작업을 끌어다 배치할 수 있습니다. 자세한 내용은 이전 블로그의 '태스크 생성하기' 항목을 참고해 주시기 바랍니다.
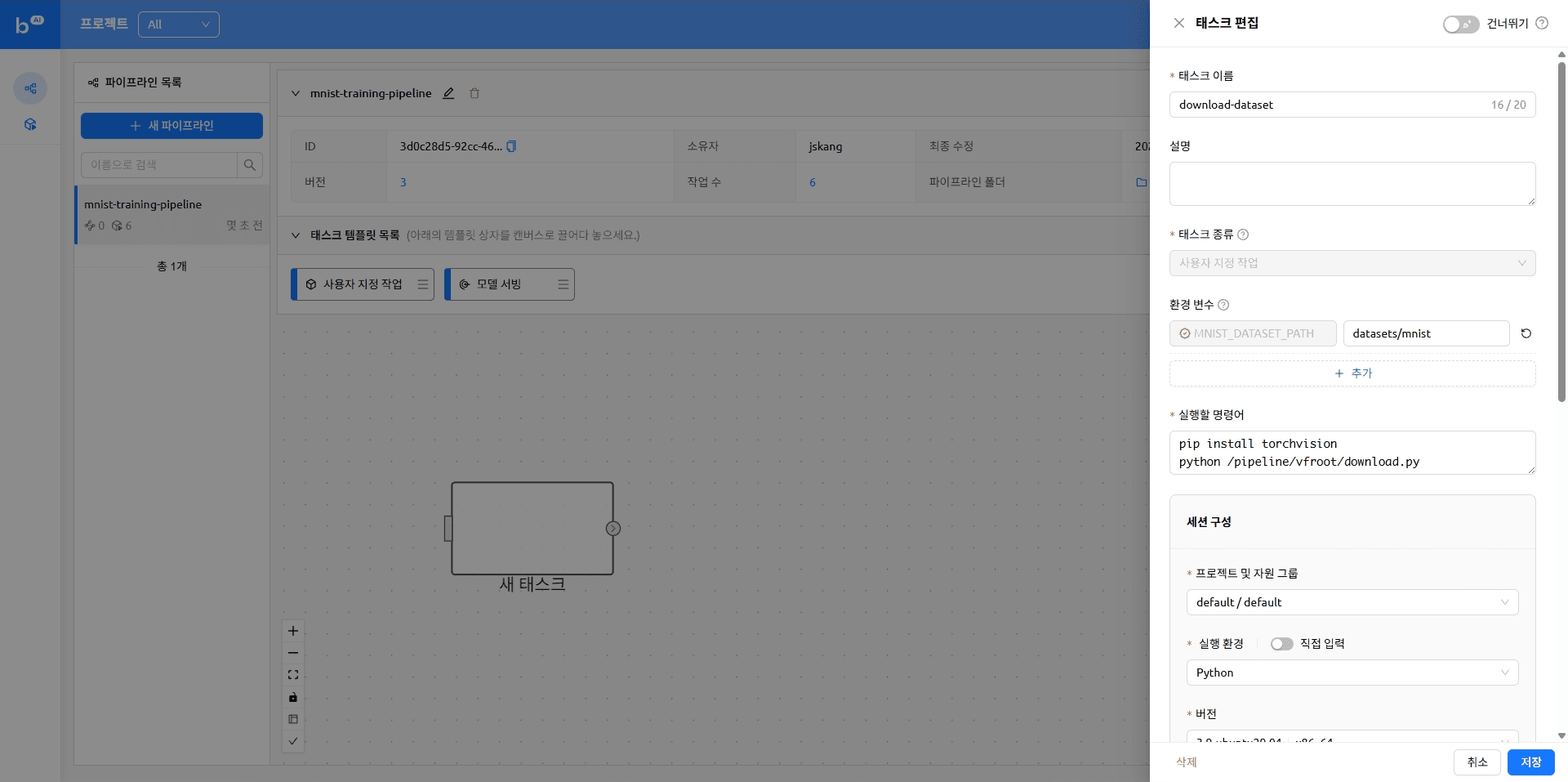 작업 끌어오기
작업 끌어오기
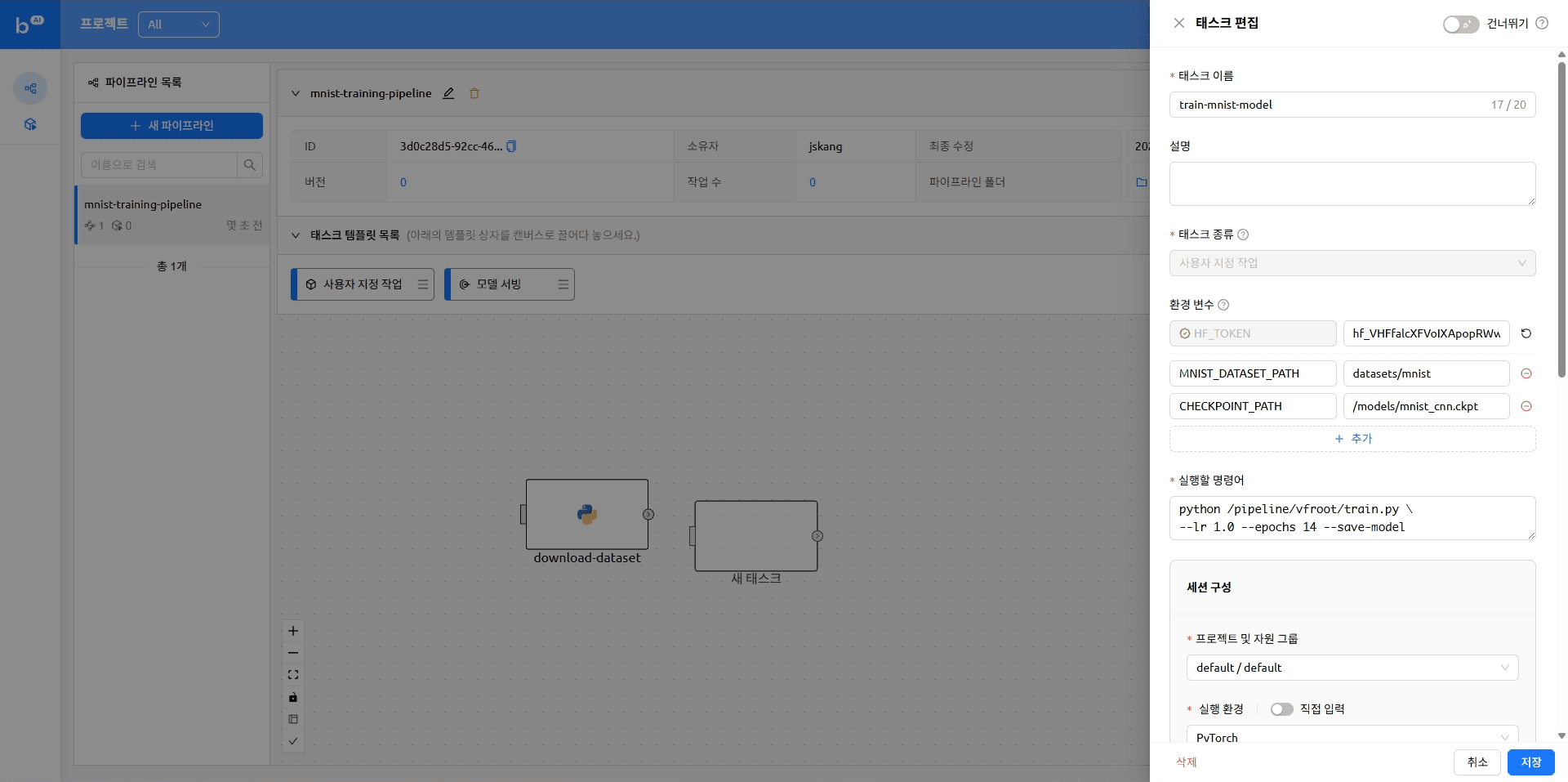
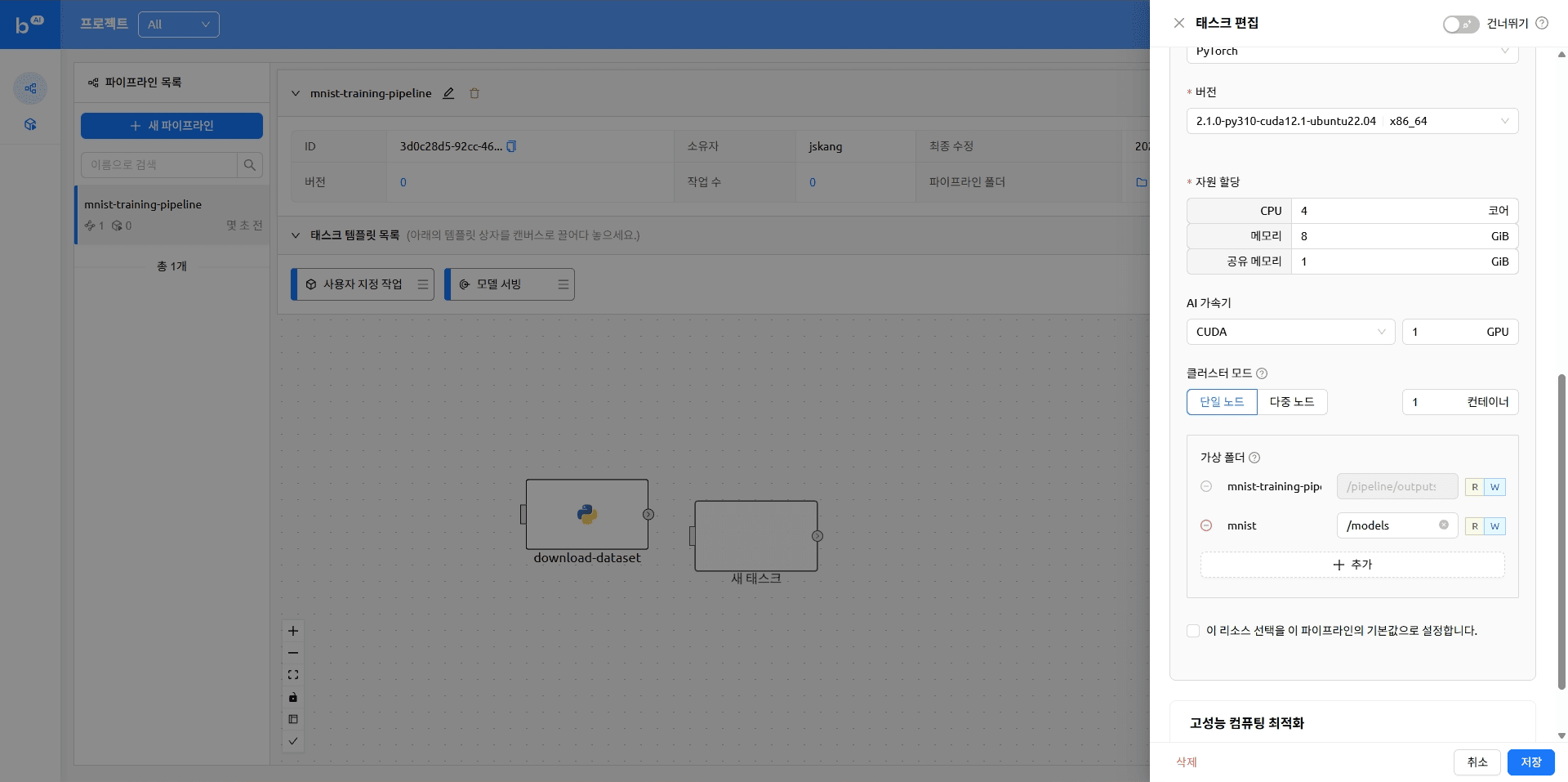
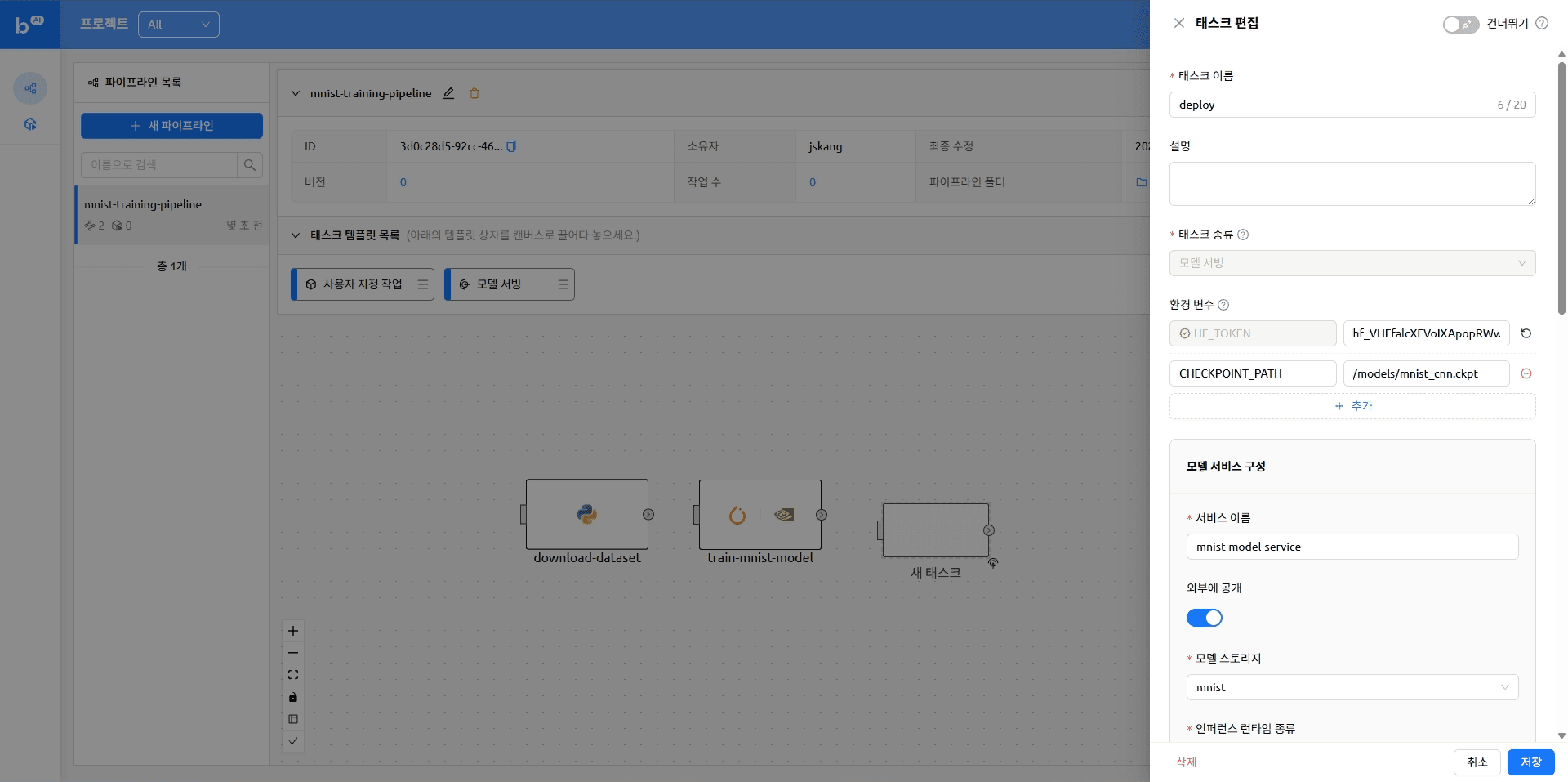
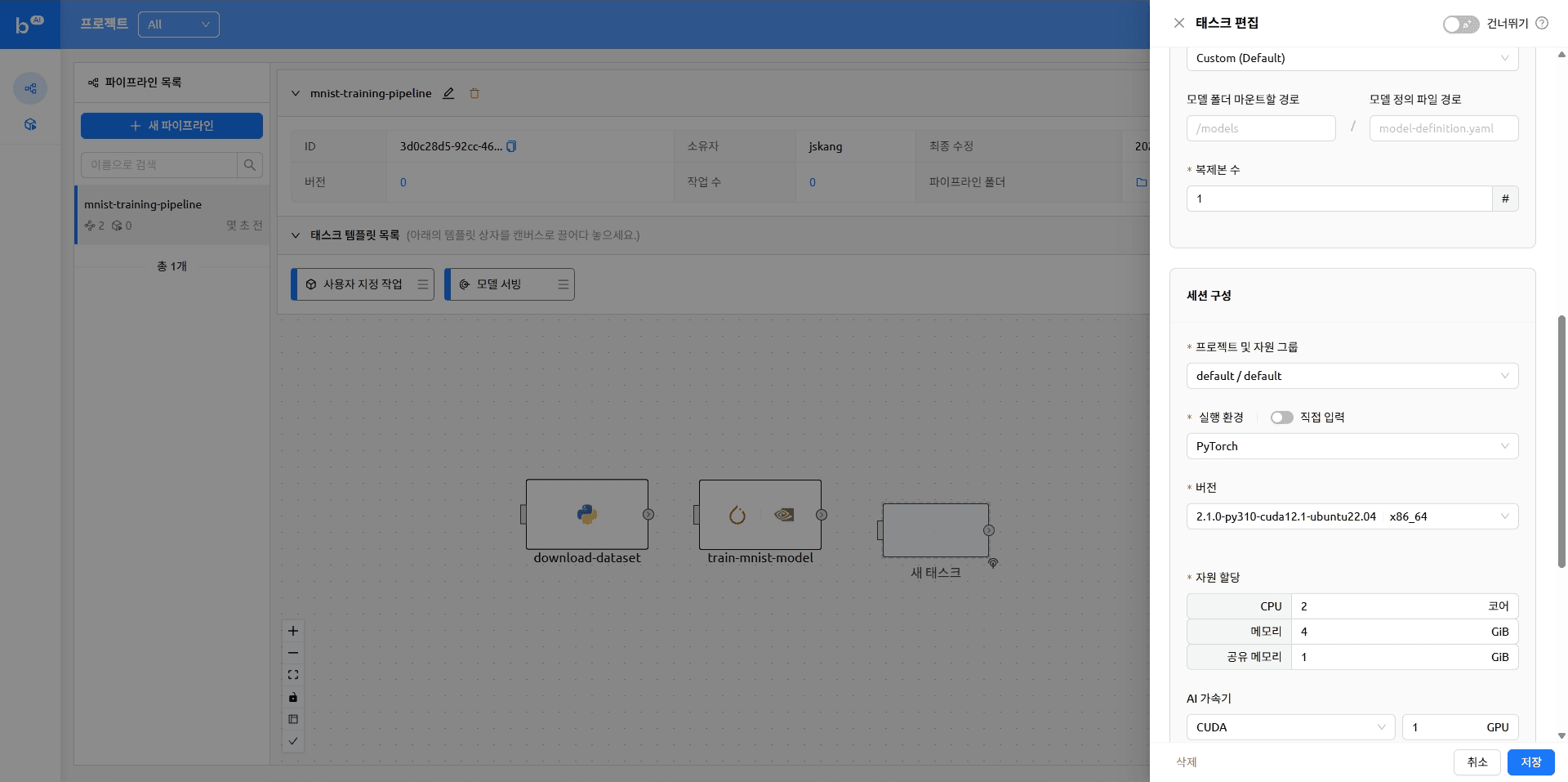
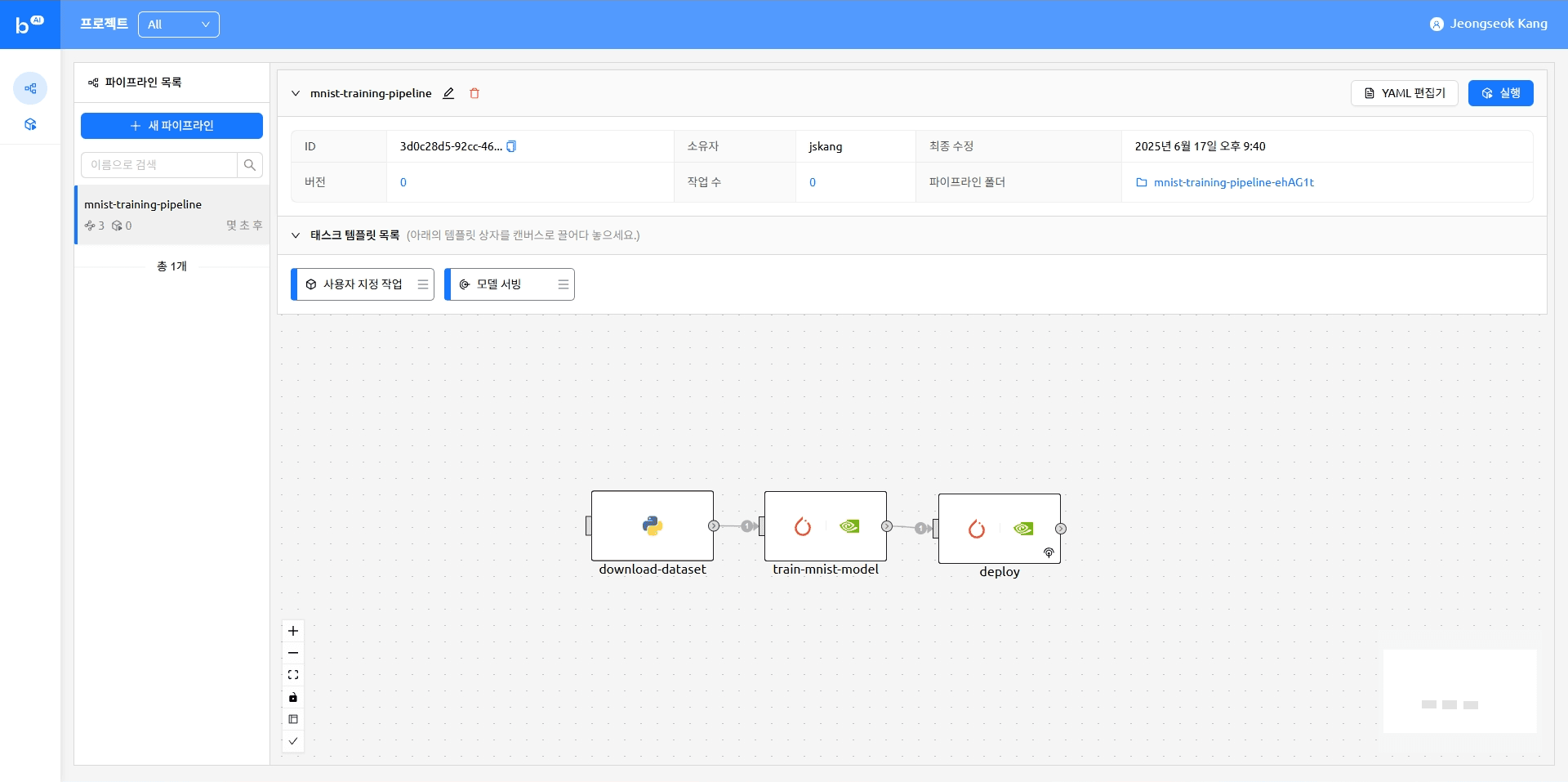
작업이 추가된 파이프라인은 아래와 같은 형태가 됩니다.
version: 25.9.0
name: mnist-training-pipeline
description: ''
ownership:
domain_name: default
scope: user
environment:
envs:
HF_TOKEN: ****
tasks:
- name: train-mnist-model
description: ''
type: default
cluster_mode: single-node
cluster_size: 1
module_uri: ''
environment:
project: default
scaling-group: default
image: cr.backend.ai/stable/python-pytorch:2.1.0-py310-cuda12.1-ubuntu22.04
envs:
MNIST_DATASET_PATH: datasets/mnist
CHECKPOINT_PATH: /models/mnist_cnn.ckpt
resources:
cpu: 4
mem: 4g
cuda.device: '1'
resource_opts:
shmem: 0g
dependencies:
- download-dataset
mounts:
- mnist:/models
skip: false
command: python /pipeline/vfroot/mnist/train.py --lr 1.0 --epochs 14 --save-model
- name: download-dataset
description: ''
type: default
cluster_mode: single-node
cluster_size: 1
module_uri: ''
environment:
project: default
scaling-group: default
image: cr.backend.ai/stable/python:3.9-ubuntu20.04
envs:
MNIST_DATASET_PATH: datasets/mnist
resources:
cpu: 1
mem: 4g
resource_opts:
shmem: 0g
dependencies: []
mounts: []
skip: false
command: 'pip install torchvision
python /pipeline/vfroot/mnist/download.py'
- name: deploy
description: ''
type: serving
cluster_mode: single-node
cluster_size: 1
module_uri: ''
environment:
project: default
scaling-group: default
image: cr.backend.ai/stable/python-pytorch:2.1.0-py310-cuda12.1-ubuntu22.04
envs: {}
resources:
cpu: 2
mem: 4g
cuda.device: '1'
resource_opts:
shmem: 0g
dependencies:
- train-mnist-model
mounts: []
skip: false
service:
name: mnist
model: mnist
model_mount_destination: /models
runtime_variant: custom
replicas: 1
open_to_public: true파이프라인 실행
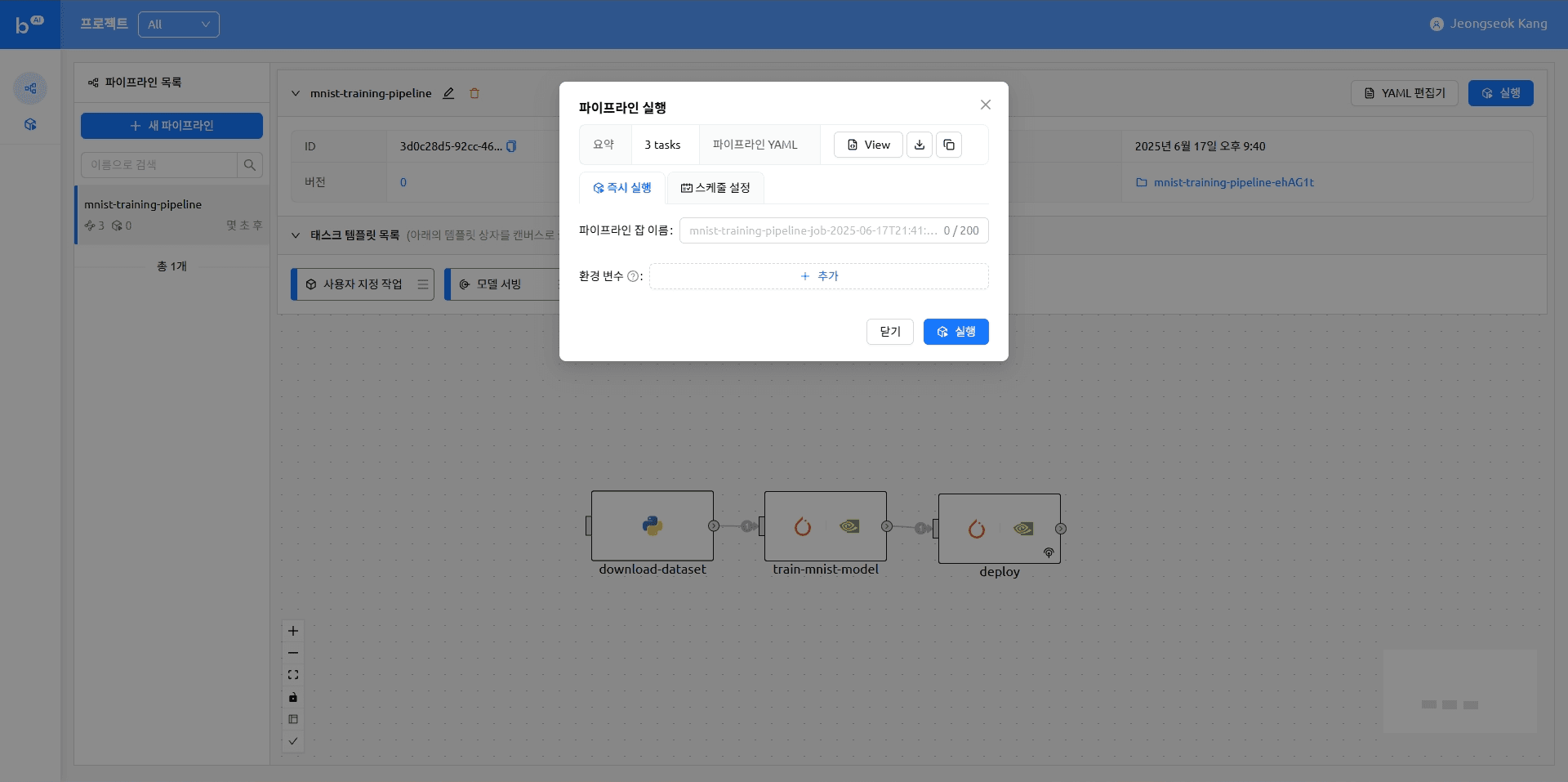
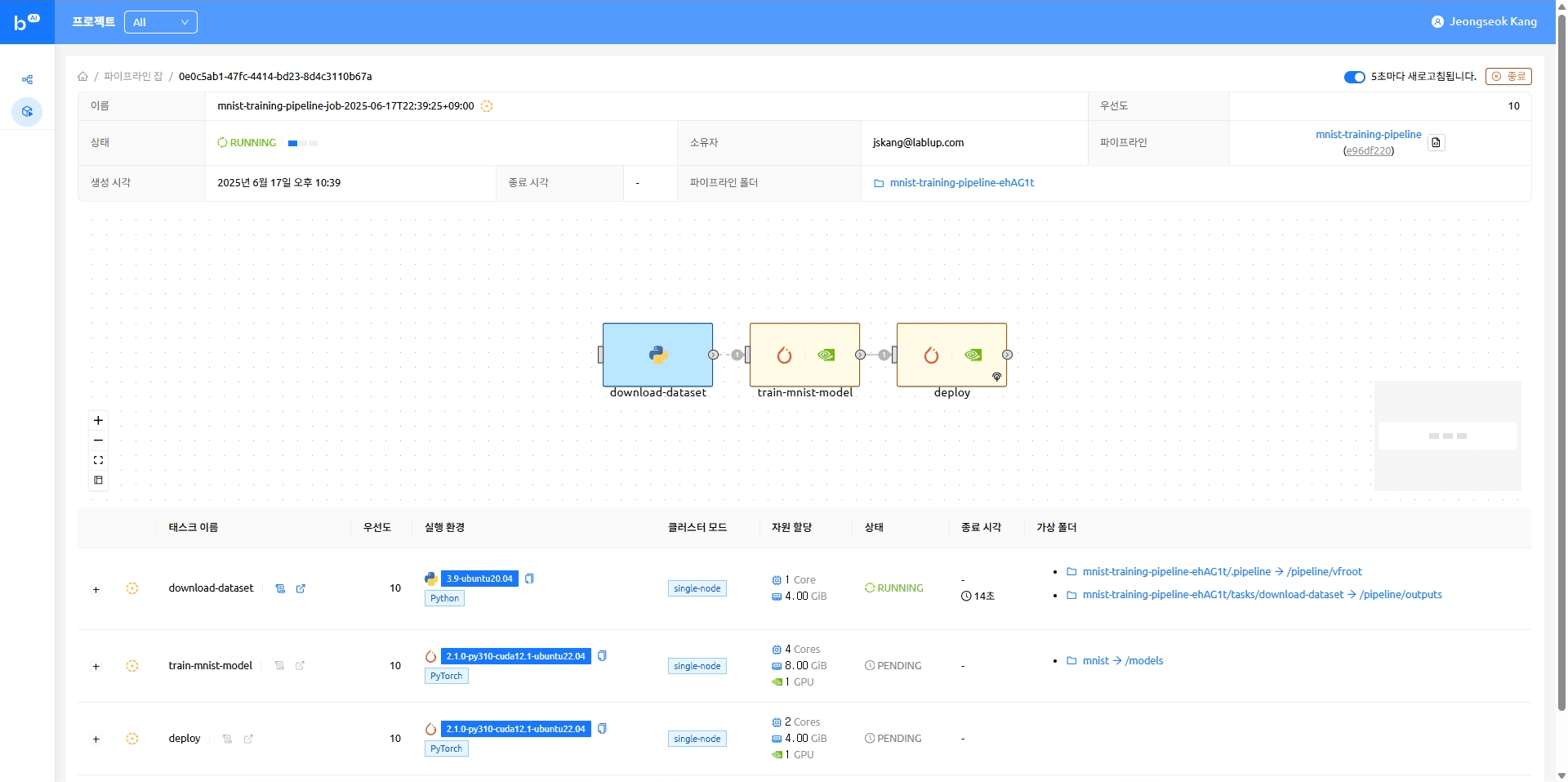
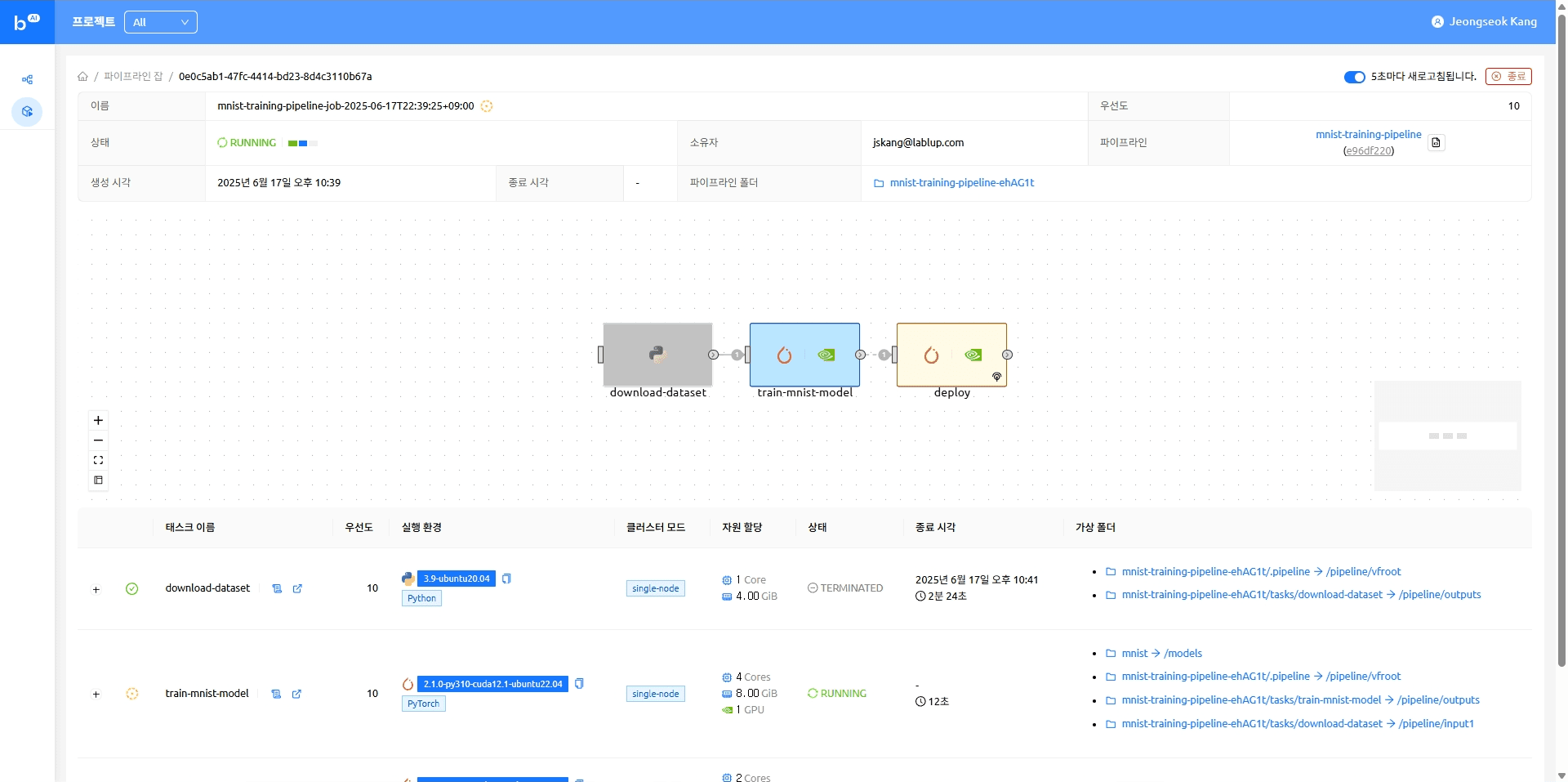
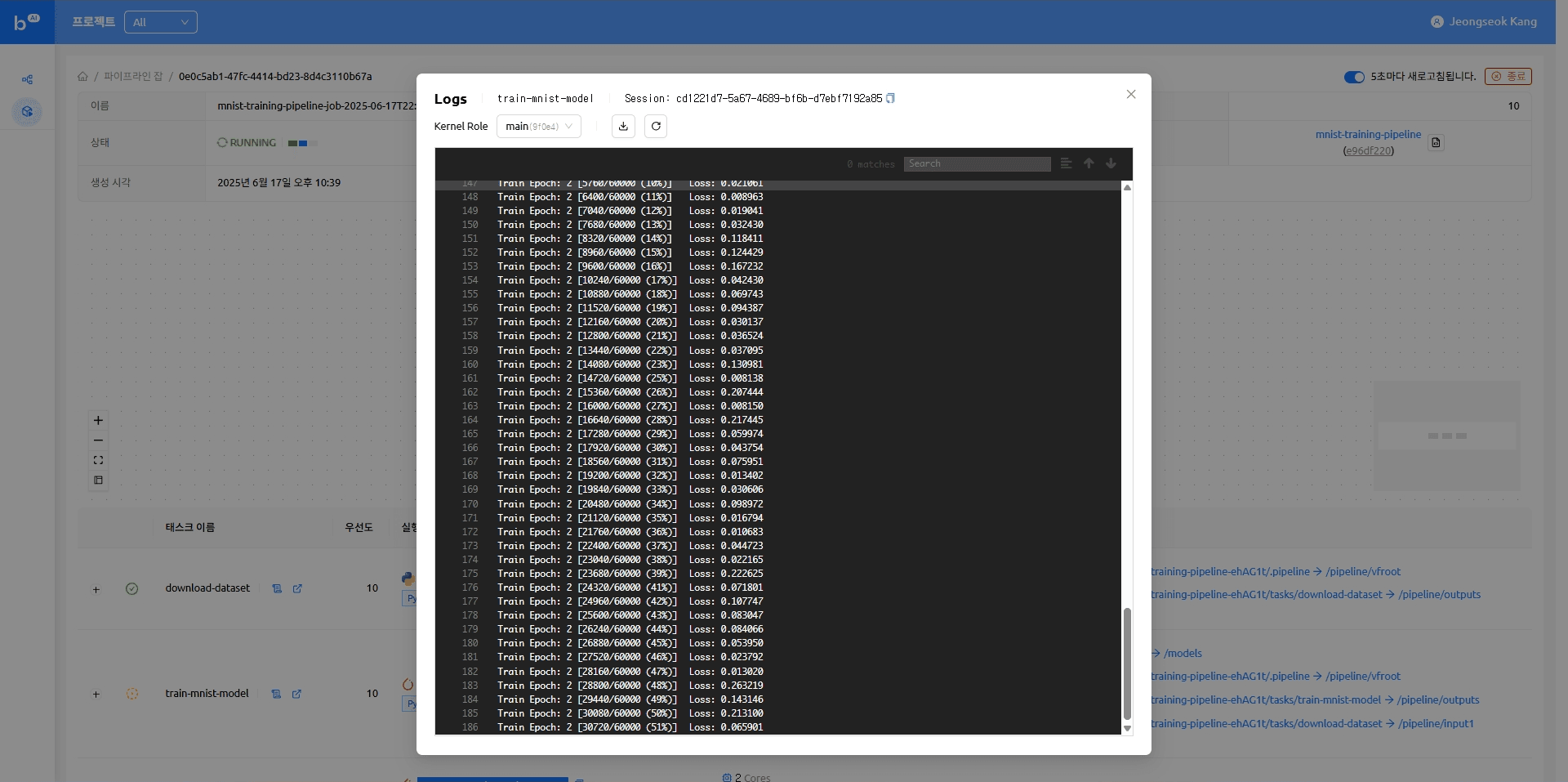
모델 서빙 태스크가 완료되면 모델에 접근 가능한 엔드포인트가 나타납니다. 해당 엔드포인트를 클릭하면 모델 추론을 실행해 볼 수 있는 Gradio 데모 페이지로 이동합니다.
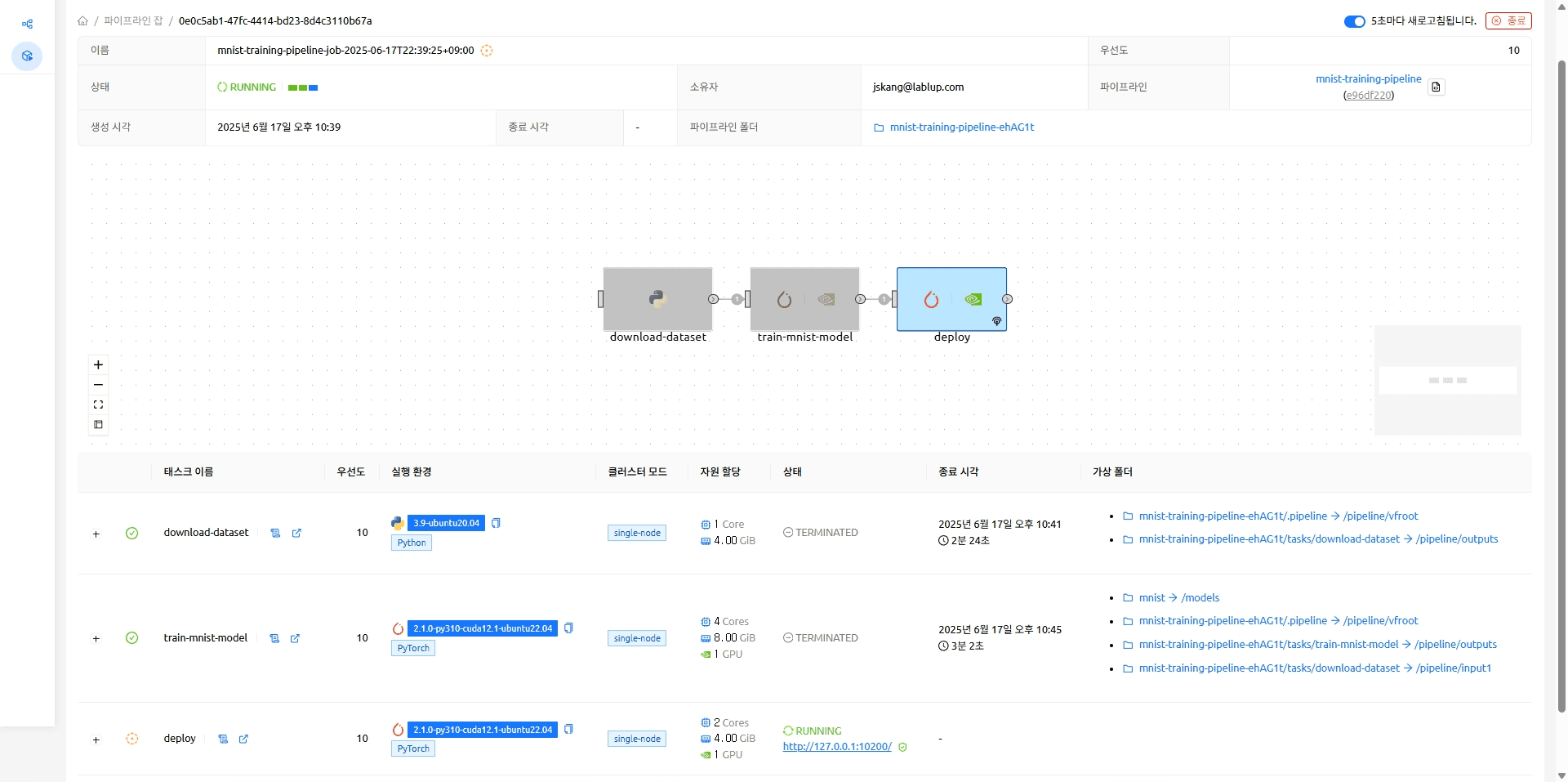 MNIST 모델이 실행 중인 엔드포인트 (http://127.0.0.1:10200)
MNIST 모델이 실행 중인 엔드포인트 (http://127.0.0.1:10200)
모델 서빙
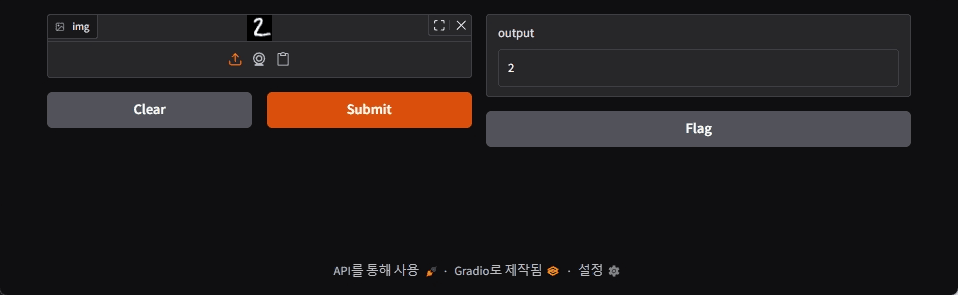
임의의 MNIST 데이터를 업로드하여 추론을 실행했을 때 모델이 잘 학습되었음을 확인할 수 있습니다.
마치며
이번에는 Backend.AI FastTrack 2를 활용하여 간단한 모델 학습 및 서빙 파이프라인을 작성하는 방법을 소개해 드렸습니다. 래블업은 항상 머신러닝 연구자 여러분의 목소리에 귀 기울이고 있습니다. 추가로 다뤄주었으면 하는 주제가 있으시다면 언제든지 contact@lablup.com으로 의견 보내주세요.
감사합니다!
부록
MNIST 데이터셋
아래의 Python 스크립트를 이용하여 MNIST/raw/t10k-images-idx3-ubyte 형태의 MNIST 데이터셋 파일을 이미지 파일로 변환할 수 있습니다.
import json
from pathlib import Path
import numpy as np
import matplotlib.pyplot as plt
root_path = Path(__file__).parent.parent
with open(root_path / "datasets/mnist/train/dataset_info.json", "r") as f:
dataset_info = json.load(f)
image_size = 28
test_num_examples = dataset_info["splits"]["test"]["num_examples"]
with open(root_path / "datasets/mnist/MNIST/raw/t10k-images-idx3-ubyte", "rb") as f:
f.read(16) # Skip the header
buf = f.read(image_size * image_size * test_num_examples)
data = np.frombuffer(buf, dtype=np.uint8).astype(np.float32)
data = data.reshape(test_num_examples, image_size, image_size)
for i in range(10):
plt.imsave(root_path / f"datasets/{i}.png", data[i], cmap="gray")Footnotes
-
Sculley, David, et al. "Machine learning: The high interest credit card of technical debt." SE4ML: software engineering for machine learning (NIPS 2014 Workshop). Vol. 8. 2014. ↩
-
Sculley, David, et al. "Hidden technical debt in machine learning systems." Advances in neural information processing systems 28 (2015). ↩
-
Jimmy Lin and Dmitriy Ryaboy. 2013. Scaling big data mining infrastructure: the twitter experience. SIGKDD Explor. Newsl. 14, 2 (December 2012), 6–19. https://doi.org/10.1145/2481244.2481247 ↩
-
D. Kreuzberger, N. Kühl and S. Hirschl, "Machine Learning Operations (MLOps): Overview, Definition, and Architecture," in IEEE Access, vol. 11, pp. 31866-31879, 2023, doi: 10.1109/ACCESS.2023.3262138. ↩
-
Lecun, Y., et al. "Gradient-based learning applied to document recognition." Proceedings of the IEEE 86.11 (1998): 2278-2324. ↩