엔지니어링
Feb 19, 2026
엔지니어링
NVIDIA DGX Spark 들여다보기: DGX Spark는 정말 블랙웰 기반일까요?

신정규
창업멤버 / 연구원 / CEO

조규진
AI 플랫폼 아키텍트
Feb 19, 2026
엔지니어링
NVIDIA DGX Spark 들여다보기: DGX Spark는 정말 블랙웰 기반일까요?
신정규
창업멤버 / 연구원 / CEO
조규진
AI 플랫폼 아키텍트
Scaling the Blackwell Architecture, © NVIDIA
지난 2025년 10월, NVIDIA는 개발자와 연구자가 데스크톱 환경에서 데이터센터급 AI 성능을 활용할 수 있도록 설계한 DGX Spark를 출시했습니다. DGX Spark는 Grace Blackwell 아키텍처 기반의 초소형 AI 슈퍼컴퓨터로, 128GB 통합 메모리와 1 PFLOP의 AI 연산 성능을 150mm x 150mm 크기의 컴팩트한 폼팩터에 담아 최대 200B 파라미터 규모의 대규모 언어 모델을 로컬에서 실행하고 파인튜닝할 수 있습니다. 래블업도 출시 직후 20대를 구매하여 사내에서 활용하고 있습니다.
GLM-5와 Sparse Attention
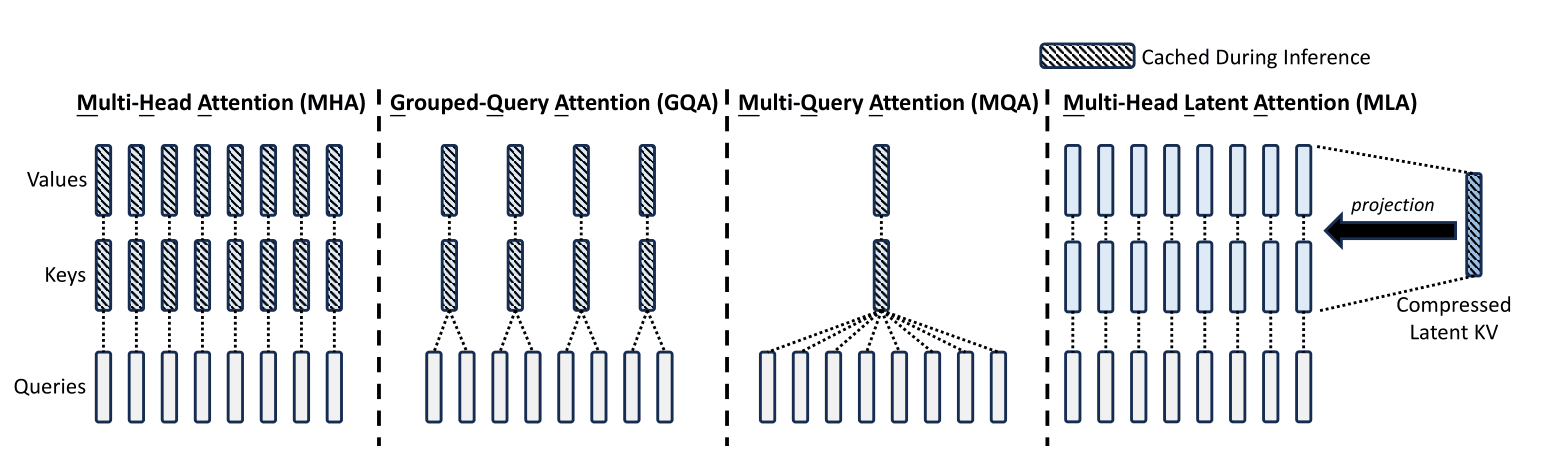
Different KV caching techniques, © [liorsinai.github.io](https://liorsinai.github.io/machine-learning/2025/02/22/mla.html)
최근 저희 엔지니어링팀에서 DGX Spark 위에 GLM-5 추론을 올려보려 했습니다. GLM-5는 MLA(Multi-head Latent Attention)와 DSA(DeepSeek Sparse Attention)라는 두 가지 기법을 함께 사용합니다. 대규모 언어 모델이 텍스트를 생성할 때는 이전에 처리한 토큰들의 정보를 메모리에 저장해두고 계속 참조하는데(이를 KV 캐시1라 합니다), 모델이 커지면 이 캐시가 차지하는 메모리도 급격히 늘어납니다. MLA는 이 캐시를 저차원 벡터로 압축해서 메모리 사용량을 줄이는 기법이고, DSA는 모든 토큰에 대해 어텐션을 계산하는 대신 중요한 토큰만 동적으로 선택하여 계산량을 줄이는 sparse attention 기법입니다. MLA는 DeepSeek-V2에서 처음 도입된 이후 DeepSeek-V3, GLM-5 등이 채택했고, GLM-5는 여기에 DSA까지 도입하여 장문 처리 성능과 배포 비용을 동시에 개선했습니다. GPU에서 이들을 효율적으로 실행하려면 전용 커널2이 필요한데, 현재 대표적인 구현체가 DeepSeek의 FlashMLA와 FlashInfer입니다.
두 프로젝트 모두 Blackwell 지원을 명시하고 있어서 DGX Spark에서도 당연히 동작할 것으로 예상했습니다. 그러나 실제로는 동작하지 않았습니다. FlashMLA는 SM100(데이터센터 블랙웰)용과 SM90(Hopper)용 두 가지 백엔드를 제공하는데, DGX Spark의 GPU는 SM12x 계열(compute capability 12.1)로 SM100이나 SM90과는 다른 아키텍처여서 둘 다 호환되지 않았습니다. SM100 커널은 tcgen05라는 명령어와 TMEM이라는 전용 하드웨어 메모리를 필요로 하고, SM90 커널은 WGMMA라는 명령어를 필요로 하는데, SM12x에는 이 중 어느 것도 없기 때문입니다. FlashAttention도 마찬가지여서, 지원 아키텍처 목록에 SM12x가 포함되어 있지 않아 "FlashAttention only supports Ampere GPUs or newer"라는 에러가 출력되었고, Blackwell 전용으로 개발 중인 FlashAttention 4(FA4)도 SM100만 지원하는 상태였습니다.
DGX Spark도 Blackwell인데, Blackwell을 지원한다는 커널이 왜 동작하지 않는 걸까요? 이 질문의 답을 찾기 위해 GB10의 내부를 좀 더 깊이 들여다봤습니다.
GB10 내부 구조

NVIDIA DGX Spark: Powered by the GB10 Superchip, © NVIDIA
GB10은 NVIDIA와 MediaTek이 공동 설계한 멀티 다이 SoC입니다. TSMC 3nm 공정의 ARM CPU 다이(Cortex-X925 10개 + Cortex-A725 10개)와 Blackwell GPU 다이를 NVLink C2C로 연결했고, 128GB LPDDR5X 메모리를 CPU와 GPU가 273 GB/s 대역폭으로 함께 사용합니다. GPU 쪽에는 SM3 48개에 CUDA 코어 6,144개가 들어있고, sparse FP4 기준 1 PFLOP의 연산 성능을 냅니다. 스펙 규모로 보면 RTX 5070과 5070 Ti 사이쯤 됩니다. nvidia-smi를 치면 아키텍처란에 'Blackwell'이라고 출력되고, NVIDIA도 GB10을 "Grace Blackwell Superchip"이라 부르고 있으니 Blackwell이라고 부르지 않을 이유는 없습니다. 이렇게 보면 깔끔한 소형 블랙웰이지만, compute capability4를 확인해보면 약간 다른 이야기가 시작됩니다.
두 개의 블랙웰: SM100과 SM12x
CUDA의 compute capability 체계를 보면 블랙웰이 단일 아키텍처가 아니라는 것을 알 수 있습니다. 데이터센터용과 컨슈머/엣지용이 서로 다른 compute capability를 갖고 있습니다.
| 데이터센터 블랙웰 | 컨슈머/엣지 블랙웰 | |
|---|---|---|
| Compute Capability | 10.0 (SM100) | 12.0 (SM120) / 12.1 (SM121) |
| 대표 제품 | B100, B200, GB200 | RTX 5090 (SM120), DGX Spark (SM121) |
| SM당 공유 메모리 | 228 KB | 128 KB |
| SM당 최대 동시 워프5 | 64 | 48 |
| TMEM (텐서 메모리) | SM당 256 KB | 없음 |
| 텐서 코어 명령어 | tcgen05 (5세대 전용) | 확장 mma.sync (Ampere 스타일) |
| 워프그룹 MMA | WGMMA 지원 | 미지원 |
| 멀티캐스트/클러스터 | 2개 이상의 SM이 협력 가능 | SM 하나가 독립 실행 |
RTX 5090은 SM120, DGX Spark는 SM121로, 이 글에서는 이들을 통칭하여 SM12x로 표기합니다.
compute capability 번호가 10.x와 12.x로 나뉘어 있는데, Ampere의 8.0과 8.6처럼 같은 메이저 버전 내에서 마이너가 갈린 것과는 차원이 다릅니다. 메이저 번호 자체가 다르고, 11.x는 통째로 비어 있습니다. Pascal(6.0/6.1), Ampere(8.0/8.6), Hopper/Ada(9.0/8.9)를 돌아봐도 한 세대 안에서 이만큼 큰 갭이 생긴 적은 없었습니다. CUTLASS 빌드 플래그도 데이터센터는 sm100a(architecture-accelerated), 컨슈머는 sm120f(family-level)로 접미사 체계부터 다릅니다.
텐서 코어 명령어 차이
GPU가 딥러닝의 핵심 연산인 행렬 곱셈을 처리하는 전용 하드웨어가 텐서 코어인데, 이 텐서 코어를 동작시키는 명령어(ISA6)가 세대마다 달라져 왔습니다.
| 세대 | 명령어 | 누가 명령을 내리나 | 데이터를 어디서 읽나 | 결과를 어디에 쓰나 |
|---|---|---|---|---|
| Volta~Ampere (SM 7.x/8.x) | mma.sync | 워프 (32개 스레드) | 레지스터 | 레지스터 |
| Hopper (SM 9.0) | wgmma | 워프그룹 (128개 스레드) | 공유 메모리 | 레지스터 |
| DC Blackwell (SM 10.0) | tcgen05.mma | 단일 스레드 | 공유 메모리 | TMEM (전용 하드웨어 메모리) |
| 컨슈머 Blackwell (SM 12.x) | 확장 mma.sync | 워프 (32개 스레드) | 레지스터 | 레지스터 |
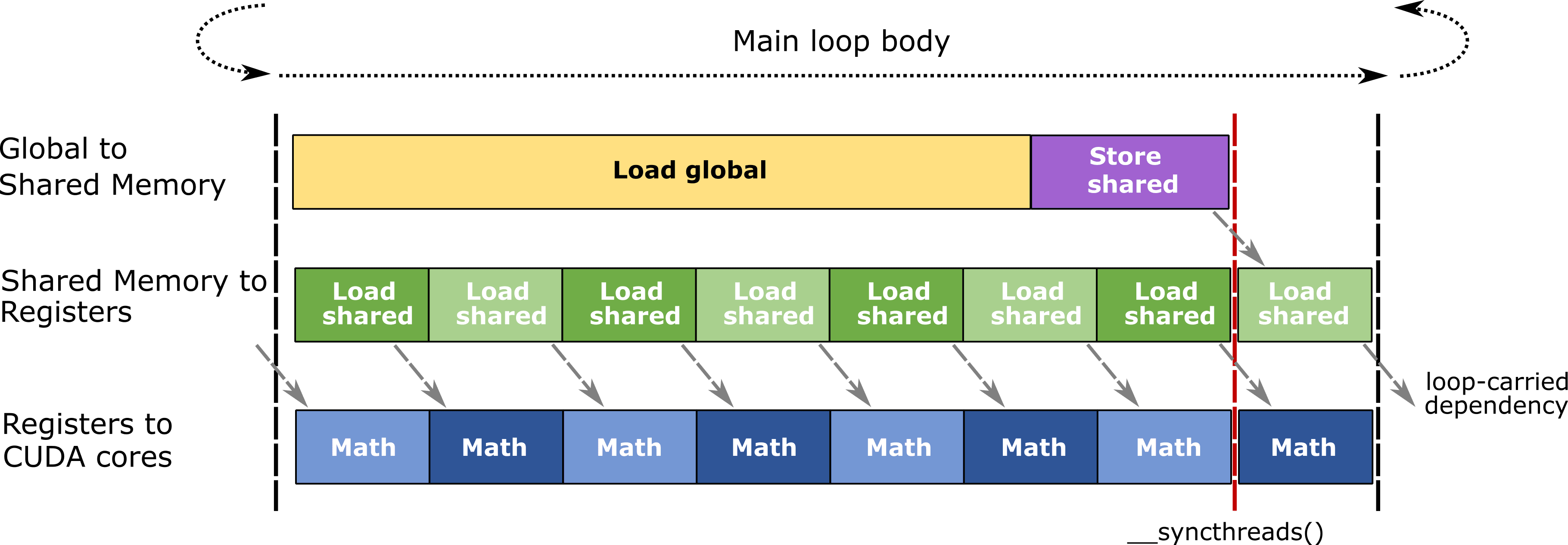
Eficient, pipelined mainloop body used in CUTLASS GEMMs, © [NVIDIA](https://github.com/NVIDIA/cutlass/blob/2.11/media/docs/efficient_gemm.md)
행렬 곱셈은 큰 행렬을 작은 타일로 쪼개서 반복 계산하는데, 각 타일의 중간 결과(어큐뮬레이터)를 어딘가에 임시 저장해야 합니다. Volta부터 Hopper까지는 이 중간 결과를 레지스터 파일7에 저장했고, CUDA 코어와 텐서 코어가 같은 레지스터 파일을 나눠 써야 했습니다. 데이터센터 Blackwell(SM100)은 여기에 TMEM이라는 전용 하드웨어 메모리(SM당 256KB)를 텐서 코어 옆에 추가하고, 이 메모리를 제어하는 전용 명령어 tcgen05를 도입했습니다. 텐서 코어가 CUDA 코어의 레지스터 파일을 점유하지 않고 자체 메모리에서 독립적으로 동작할 수 있게 된 것이 SM100의 가장 큰 변화입니다.
SM12x에는 이 TMEM 하드웨어 자체가 없고, 따라서 이를 제어하는 tcgen05 명령어도 지원하지 않습니다. Hopper의 WGMMA 명령어도 마찬가지여서, SM12x 타겟으로 WGMMA 코드를 컴파일하면 ptxas error: Instruction 'wgmma.fence' not supported on .target 'sm_120' 에러가 납니다. SM12x가 사용하는 텐서 코어 명령어는 Ampere 세대부터 있었던 mma.sync의 확장 버전으로, FP4나 FP6 같은 새로운 숫자 포맷은 지원하지만 동작 방식 자체는 가장 오래된 형태입니다. 표의 마지막 열을 보면, SM100은 중간 결과를 전용 메모리(TMEM)에 쓰는 반면 SM12x는 Ampere와 동일하게 레지스터에서 읽고 레지스터에 씁니다. 데이터센터 Blackwell이 텐서 코어를 독립적인 연산 유닛으로 만든 반면, 컨슈머 Blackwell은 새로운 데이터 타입을 가장 오래된 프로그래밍 모델 위에 올린 셈입니다.
SM90 커널은 WGMMA를, SM100 커널은 tcgen05를, SM12x 커널은 확장 mma.sync를 사용하기 때문에 세 아키텍처 사이에 커널 호환성이 없고, 개발자는 세 벌의 코드를 따로 유지해야 합니다.
기존 커널을 SM12x에 맞춰 다시 작성하는 것도 간단한 일이 아닙니다. 한 번에 처리하던 64x64 크기의 행렬 타일을 16x8 크기로 쪼개서 여러 번 반복해야 하고(64x64 하나에 32회의 mma.sync 호출이 필요), 메모리 로드 방식, 스레드 간 동기화, 스레드 구조 자체를 모두 바꿔야 합니다.
과거로부터 패턴 찾기
NVIDIA가 같은 세대 이름 아래 서로 다른 마이크로아키텍처를 출시한 것은 블랙웰이 처음이 아닙니다. Ampere(2020) 세대의 데이터센터용 GA100(A100)은 TSMC 7nm으로 제조되었고 SM당 FP32 64코어에 HBM2 메모리를 탑재했습니다. 같은 해 9월에 출시된 컨슈머용 GA102(RTX 3090)는 삼성 8nm 공정에 SM당 FP32 128코어, GDDR6X 메모리를 사용했습니다. GA102는 이전 세대인 Turing의 INT32 전용 데이터패스를 FP32도 처리할 수 있도록 변경하여 SM당 셰이더 수를 두 배로 늘렸고, GA100은 그런 변경 없이 FP64 연산과 HBM 메모리에 집중했습니다. 제조 공정도, SM 설계도, 메모리 인터페이스도 다른 별개의 칩이었지만 둘 다 "Ampere"라는 이름을 사용했습니다.
Hopper/Ada Lovelace(2022)에서는 아예 아키텍처 이름 자체를 분리했습니다. 데이터센터용 Hopper(H100, SM90)는 2022년 3월에, 컨슈머용 Ada Lovelace(RTX 4090, SM89)는 같은 해 9월에 별도의 아키텍처로 발표되었고, compute capability도 Hopper가 9.0, Ada Lovelace가 8.9로 달랐습니다.
Pascal(2016)에서도 GP100(Tesla P100)에는 NVLink와 HBM2가 들어갔지만 GP102(GTX 1080 Ti)에는 들어가지 않았습니다.
설계 판단의 배경
데이터센터 칩과 컨슈머 칩은 한정된 트랜지스터를 배분하는 방향이 다릅니다. 데이터센터 칩은 FP64 연산, HBM 메모리 대역폭, NVLink/NVSwitch, MIG 파티셔닝에 다이 면적을 할당하고, 컨슈머 칩은 RT 코어, 디스플레이 출력, 전력 효율에 할당합니다. DGX Spark의 GB10은 SoC 전체가 140W인 반면, B200 GPU 하나가 1,000W입니다.
SM100의 TMEM이나 tcgen05, 2-SM 협력 MMA는 수천 개의 GPU가 대규모 행렬 연산을 처리하는 데이터센터 환경에 맞춰 설계된 기능입니다. GLM-5나 DeepSeek-V3 같은 MoE8 모델은 입력 토큰마다 모델의 일부분(전문가 서브넷)만 골라서 활성화하는 구조여서, 큰 행렬 곱셈 하나를 오래 돌리는 것이 아니라 작은 행렬 곱셈 여러 개를 빠르게 전환하며 실행합니다. TMEM은 이 전환 과정에서 쌓이는 중간 결과 저장 부담을 전용 메모리로 흡수하고, tcgen05의 비동기 실행은 현재 전문가의 연산이 진행되는 동안 다음 전문가의 가중치를 미리 읽어올 수 있게 합니다. 반면 DGX Spark처럼 LPDDR5X 273 GB/s 대역폭의 데스크탑 환경에서는 텐서 코어의 처리 속도보다 메모리에서 데이터를 읽어오는 속도가 병목이므로 이런 기능에 다이 면적을 투자해도 실질적인 성능 향상을 기대하기 어렵습니다. SM12x가 검증된 mma.sync 방식을 유지하면서 FP4/FP6, 5세대 텐서 코어/RT 코어 같은 새로운 기능을 가져간 것은 이런 설계 판단의 결과입니다. 실제로 Hot Chips 2025에서 NVIDIA는 GB10이 TSMC 3nm A0(첫 번째 실리콘)에서 바로 동작했다고 밝혔습니다. 이는 새 마이크로아키텍처를 처음부터 설계한 것이 아니라 검증된 IP 블록 위주로 구성했기 때문입니다.
소프트웨어 생태계 현황
FlashMLA의 sparse decoding 커널은 내부적으로 FP8 KV 캐시와 함께 WGMMA 또는 tcgen05 기반의 행렬 곱셈을 사용하는데, SM12x에서는 둘 다 쓸 수 없으므로 SM12x 전용 백엔드를 처음부터 새로 작성해야 합니다. FlashInfer도 동일한 상황입니다. FlashAttention은 지원 아키텍처 목록에 Ampere, Ada Lovelace, Hopper만 포함되어 있어서 SM12x를 "Ampere보다 신형"으로 인식하지 못합니다. Blackwell 전용 FlashAttention 4(FA4)도 SM100만 지원합니다. vLLM과 SGLang 생태계에서도 SM12x 관련 이슈가 계속 보고되고 있는데, SM100용으로 작성된 FP8 block-scaled GEMM 커널이 RTX 5090(SM120)에서 동작하지 않는 것이 대표적입니다. SGLang이 공개한 DeepSeek-V3 서빙 설정에도 H200(SM90)과 B200(SM100) 구성만 있고 SM12x 구성은 없습니다.
Triton은 SM12x를 SM80(Ampere)으로 취급하여 블랙웰 관련 최적화를 모두 비활성화하고 있고, vLLM에서는 --enforce-eager 플래그가 필요합니다. SM12x에서 어텐션 커널을 아예 실행할 수 없는 것은 아닌데, Ampere 시절의 명령어(mma.sync, cp.async)로 FlashAttention을 CUDA C++로 직접 다시 구현하거나 cuDNN의 sdpa 백엔드를 쓰는 방법이 보고되고 있습니다. 다만 이 방법들은 일반적인 dense attention만 가능하고, MLA 전용 커널이나 sparse attention, FP8 KV 캐시를 사용할 수 없어서 GLM-5나 DeepSeek-V3 같은 모델의 성능을 제대로 끌어내기는 어렵습니다.
DGX Spark는 128GB 메모리를 CPU와 GPU가 칸막이 없이 함께 사용하는 구조인데, GPU를 별도 카드로 장착하는 일반적인 데스크탑에서는 불가능한 방식입니다. HBM만큼의 대역폭은 나오지 않지만, 200B 파라미터 모델 전체를 데스크탑에서 메모리에 올릴 수 있다는 것 자체가 드문 환경이고, SM12x에 맞는 커널이 갖춰지면 DGX Spark의 실질적인 활용도는 크게 달라질 수 있습니다.
마치며
GB10은 블랙웰입니다. 5세대 텐서 코어를 갖추고 있고, FP4/FP6 연산을 지원하며, RT 코어도 탑재되어 있습니다. 다만, 데이터센터에서 사용되는 블랙웰과 동일한 명령어 체계를 가지고 있지는 않습니다. SM12x의 텐서 코어 프로그래밍 모델은 데이터센터 Blackwell의 tcgen05보다 Ampere의 mma.sync에 가깝고, 커널 개발자에게는 Hopper, 데이터센터 Blackwell, 컨슈머 Blackwell 세 갈래의 코드를 유지해야 하는 부담이 생깁니다.
이런 아키텍처 분기는 Pascal, Ampere, Hopper/Ada Lovelace에서도 매 세대 반복되어 온 패턴이며, 블랙웰에서 이 차이가 더 두드러지는 것은 TMEM이나 tcgen05 같은 데이터센터 전용 기능의 규모가 이전 세대보다 커졌기 때문입니다. 약 $4,000 데스크탑 기기에 $30,000 이상의 데이터센터 GPU가 가진 전체 명령어 체계가 들어갈 수는 없겠지만, '블랙웰'이라는 같은 이름 아래 명령어 수준의 분기가 존재한다는 점은 CUDA 커널을 작성하거나 이에 의존하는 개발자라면 알아두면 좋을 엔지니어링 디테일입니다.
DGX Spark에 특화된 Unified Memory를 지원하는 Backend.AI GO를 다운로드하여 사용해보세요.
Footnotes
-
KV 캐시: 언어 모델이 텍스트를 생성할 때, 이전 토큰들의 Key와 Value 벡터를 저장해두는 메모리 영역. 모델이 크고 입력이 길수록 이 캐시의 크기도 비례해서 커집니다. ↩
-
커널(kernel): GPU에서 실행되는 프로그램 단위. 여기서는 어텐션 연산을 GPU 하드웨어에 맞게 최적화하여 작성한 코드를 말합니다. ↩
-
SM(Streaming Multiprocessor): GPU의 기본 연산 블록. CUDA 코어와 텐서 코어가 SM 안에 묶여 있고, GPU 전체 성능은 SM의 개수와 각 SM의 구성에 따라 결정됩니다. ↩
-
Compute Capability: NVIDIA가 GPU의 하드웨어 기능 수준을 나타내기 위해 부여하는 버전 번호. 같은 세대라도 지원하는 명령어와 기능이 다르면 다른 번호가 붙습니다. ↩
-
워프(warp): GPU에서 32개의 스레드가 한 묶음으로 움직이며 같은 명령을 동시에 실행하는 단위. GPU 프로그래밍의 기본 실행 단위입니다. ↩
-
ISA(Instruction Set Architecture): 하드웨어가 이해하는 명령어 체계. x86이나 ARM처럼 GPU에도 고유한 명령어 세트가 있고, 같은 '블랙웰'이라도 ISA가 다르면 같은 코드가 실행되지 않습니다. ↩
-
레지스터 파일(register file): 프로세서 코어 바로 옆에 붙어있는 가장 빠른 저장 공간. 용량이 제한적이라 여러 연산이 동시에 사용하면 경합이 발생합니다. ↩
-
MoE(Mixture of Experts): 모델 전체를 항상 사용하지 않고, 입력에 따라 '전문가'라 불리는 서브네트워크 일부만 골라서 활성화하는 구조. 전체 파라미터 수 대비 실제 연산량을 줄일 수 있습니다. ↩