
모두가 에이전트를 이야기하는 시대
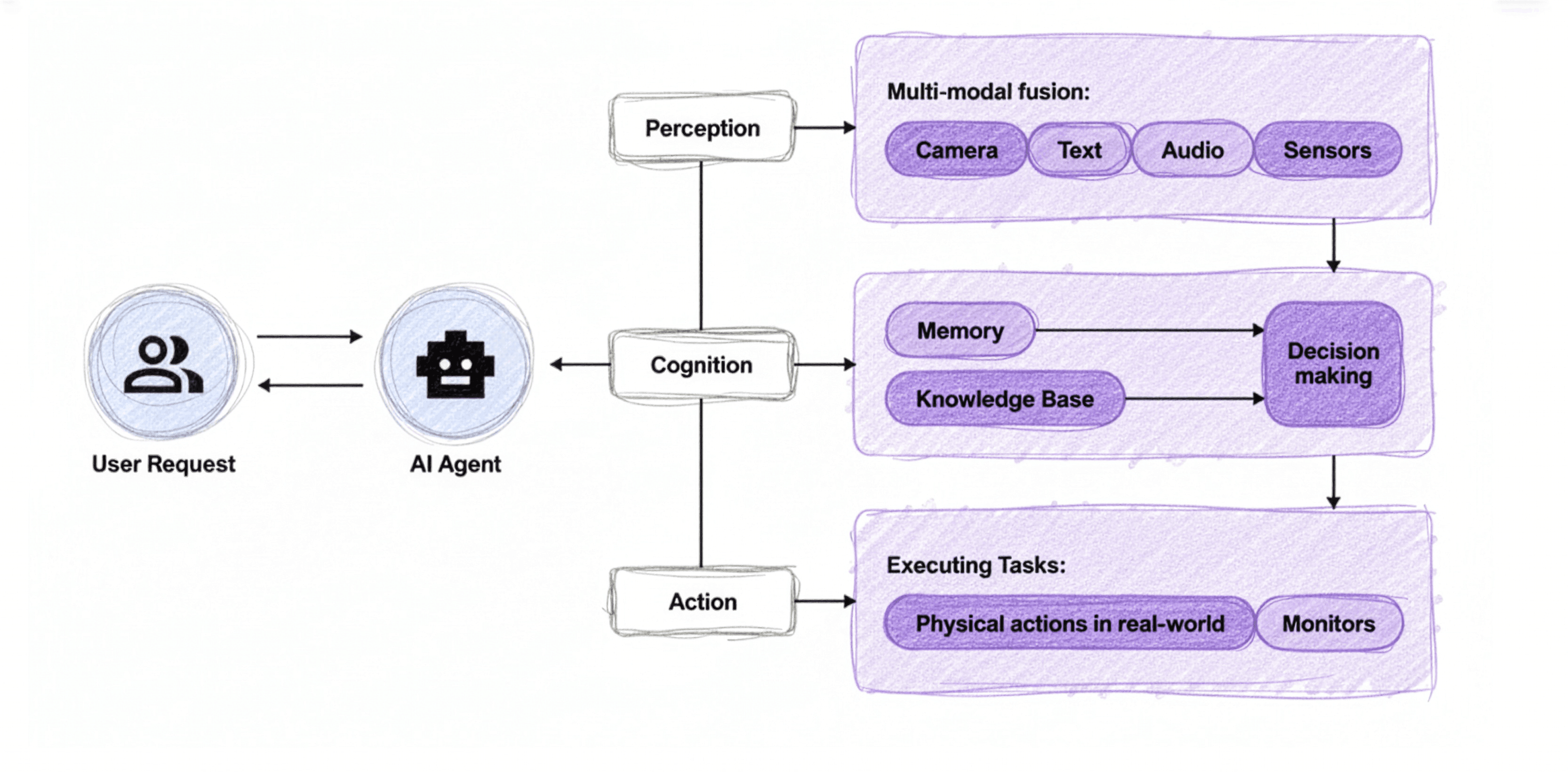
최근 AI 기술 동향을 살펴보면 '대-에이전트(Agent) 시대'라는 말이 과언이 아닐 정도로 모두가 AI 에이전트를 이야기하고, 개발하고 있습니다. AI 에이전트란 간단히 말해, 사용자의 요청(Request)을 받아 특정 목적에 맞는 도구(웹사이트, 코드, API 등)와 상호작용하여 과업을 실행하고, 그 결과를 사용자에게 반환하는 시스템을 의미합니다. 에이전트 기술의 중심에는 앤트로픽(Anthropic)이 제안한 MCP(Model Context Protocol)라는 키워드가 있습니다. MCP는 다양한 AI 애플리케이션과 데이터 소스 및 도구들 사이의 상호작용을 표준화하여, 통합된 사용자 경험을 제공하기 위해 등장한 프로토콜입니다. 최근 OpenAI가 ChatGPT 서비스에 MCP를 전면 지원한다고 발표했을 정도로, MCP는 이제 에이전트 생태계의 핵심 기술로 자리 잡고 있습니다.
하지만 여기서 한 가지 근본적인 질문이 생깁니다. 과연 모든 대규모 언어 모델(LLM)이 MCP를 제대로 이해하고 활용할 수 있을까요? 앤트로픽의 Claude처럼 MCP와 함께 개발된 모델은 당연히 잘 알겠지만, Llama나 Gemma 같은 수많은 오픈소스 LLM들은 MCP에 대한 별도의 학습 데이터 없이 공개되었습니다. 새로운 모델이 나올 때마다 값비싼 GPU를 사용해 파인튜닝하는 것은 현실적으로 큰 부담입니다.
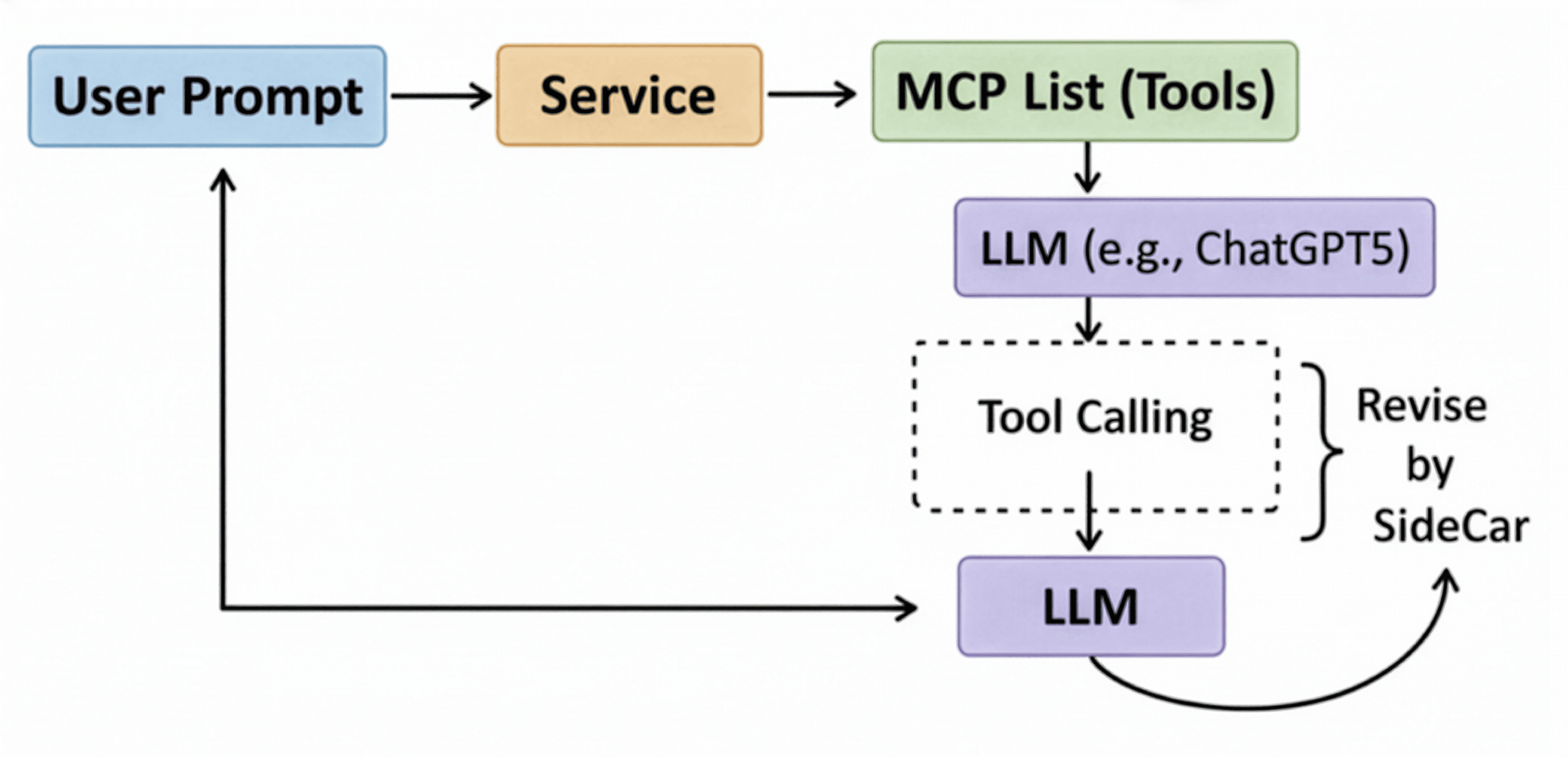
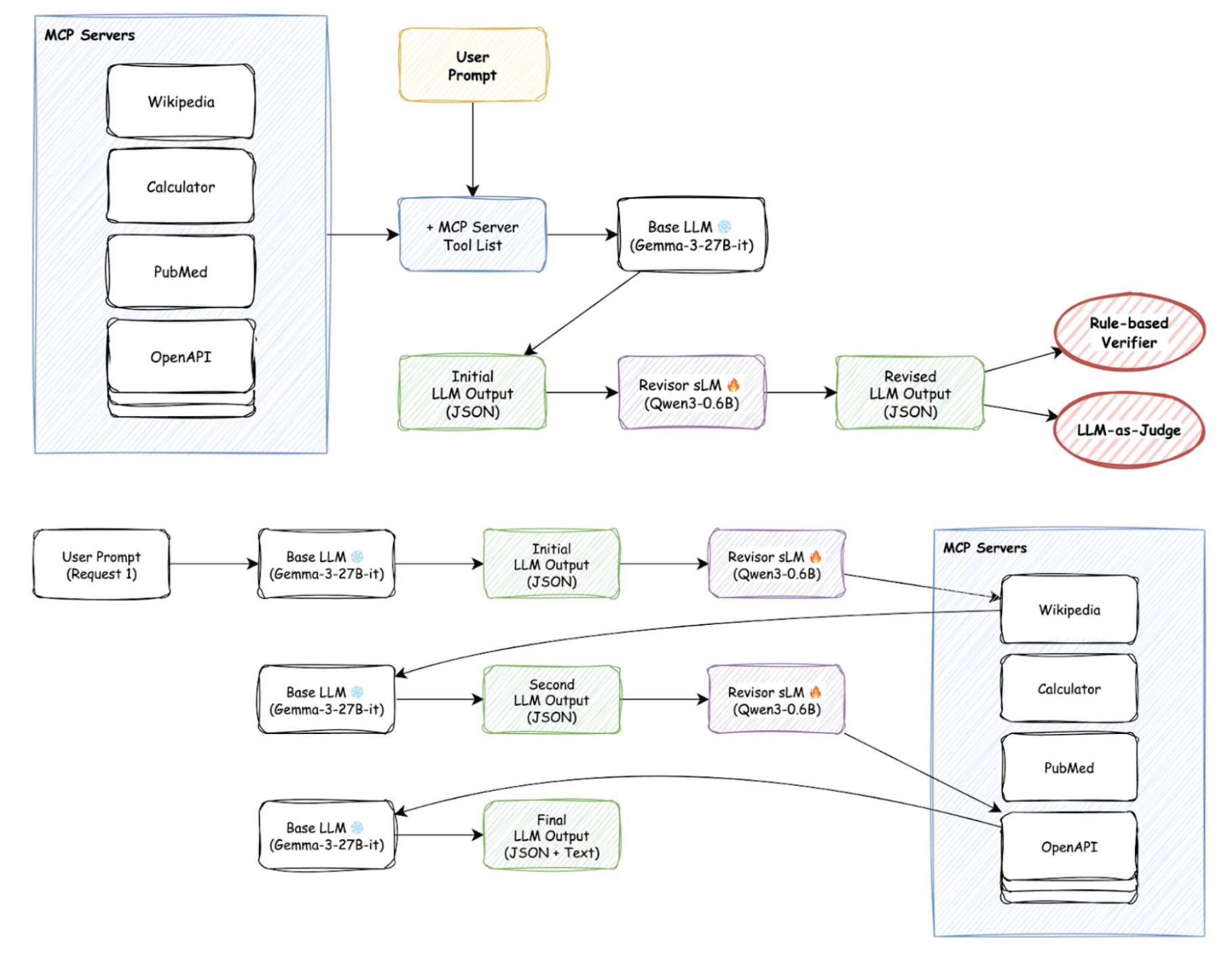
이 문제를 해결하기 위해, 저희는 소형 언어 모델(sLM)을 학습시키는 아이디어를 구체화하기로 했습니다. 이 사이드카 모델은 기존의 강력한 LLM을 직접 수정하는 대신, 그 LLM이 생성한 결과물을 MCP 포맷에 맞게 '수정(Revise)'해주는 보조 역할을 수행합니다. 이를 통해 어떤 LLM이든 큰 비용 없이 MCP 기반 에이전트 시스템에 통합할 수 있게 됩니다. 이 아티클에서는 MCP 사이드카 sLM을 학습시키기 위한 저희의 여정을 공유하고자 합니다. 아이디어 구상부터 평가 지표 설정, 데이터 생성, 그리고 수많은 시행착오 끝에 강화학습에 이르기까지의 과정을 살펴보겠습니다.
MCP와 기존 함수 호출(Function Calling)은 무엇이 다른가?
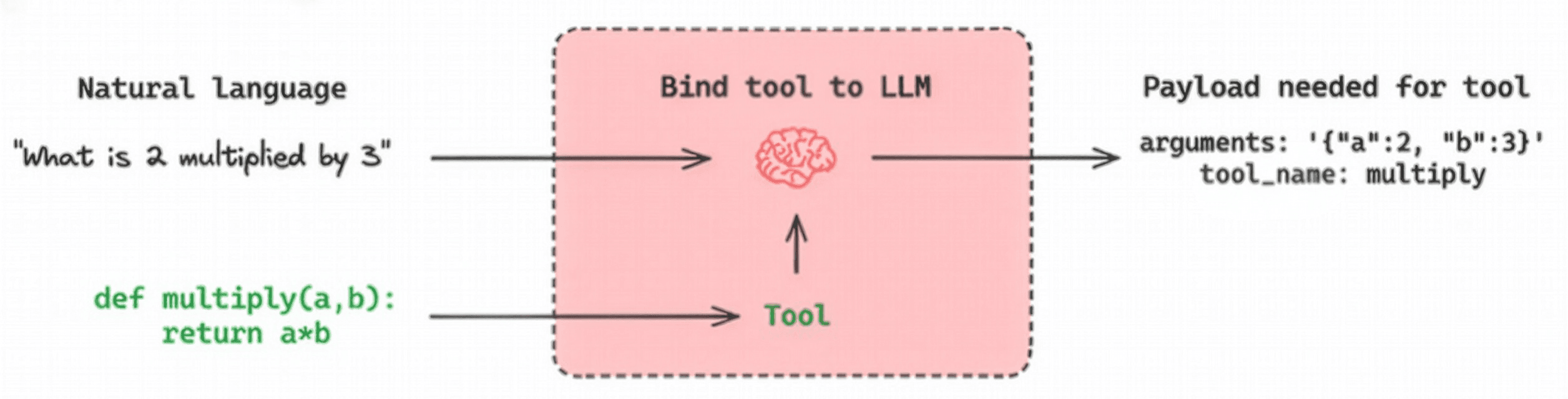
MCP를 이해하기 위해 먼저 기존의 '함수 호출(Function Calling)' 또는 '도구 호출(Tool Calling)' 기능과 비교해볼 필요가 있습니다. 함수 호출은 LLM이 자연어 요청을 이해하고, 사전에 정의된 함수들 중에서 적절한 것을 골라 필요한 인자(Argument)와 함께 JSON 형태로 반환하는 기능입니다. LLM이 직접 코드를 실행하는 것이 아니라, 실행에 필요한 정보를 정해진 형식으로 제공해주는 역할이라고 할 수 있습니다. 반면, MCP는 이보다 더 구조화되고 확장된 프로토콜입니다. 아래 그림에서 볼 수 있는 것처럼, MCP의 흐름은 몇 가지 단계를 거칩니다.
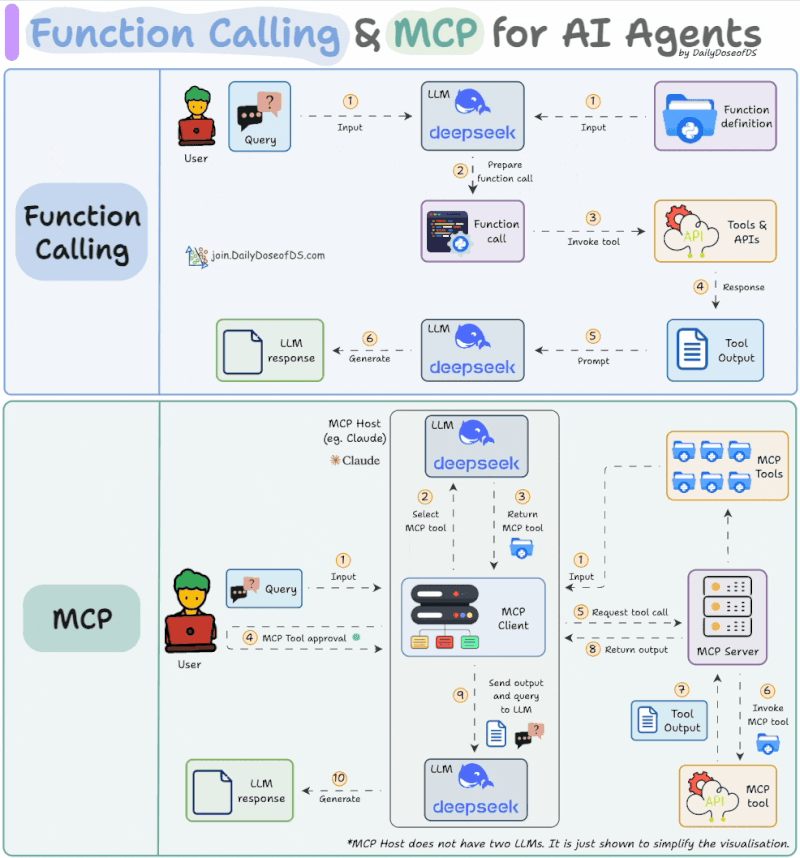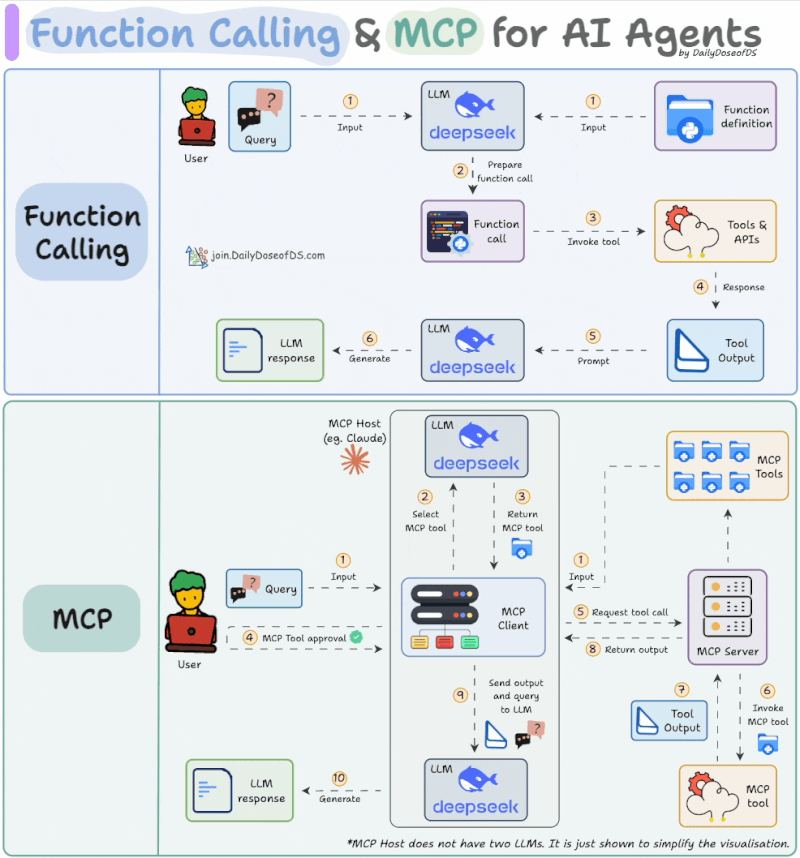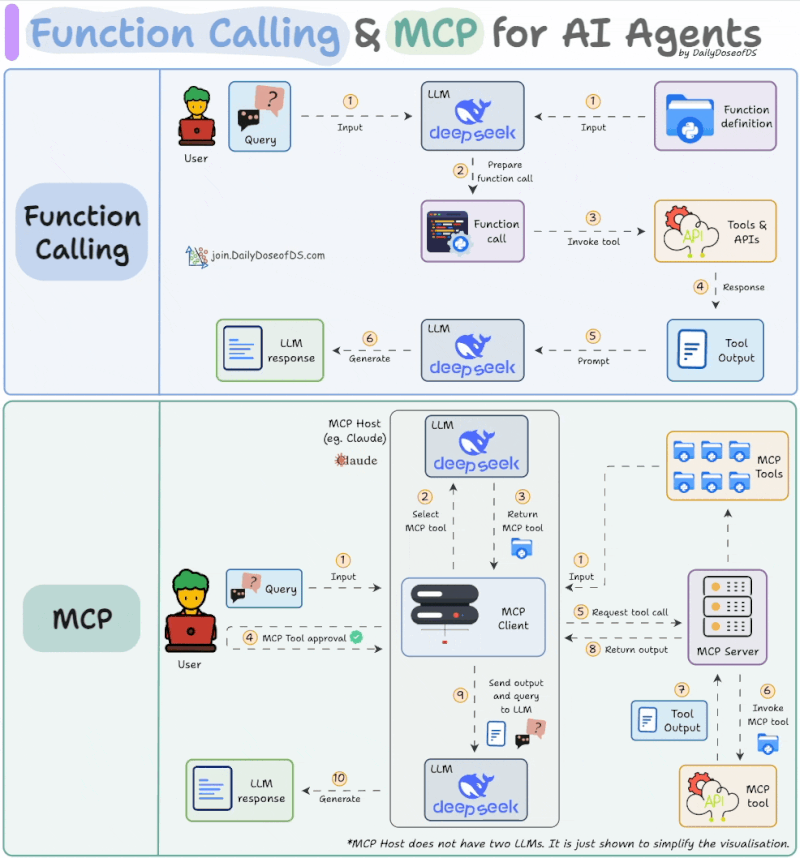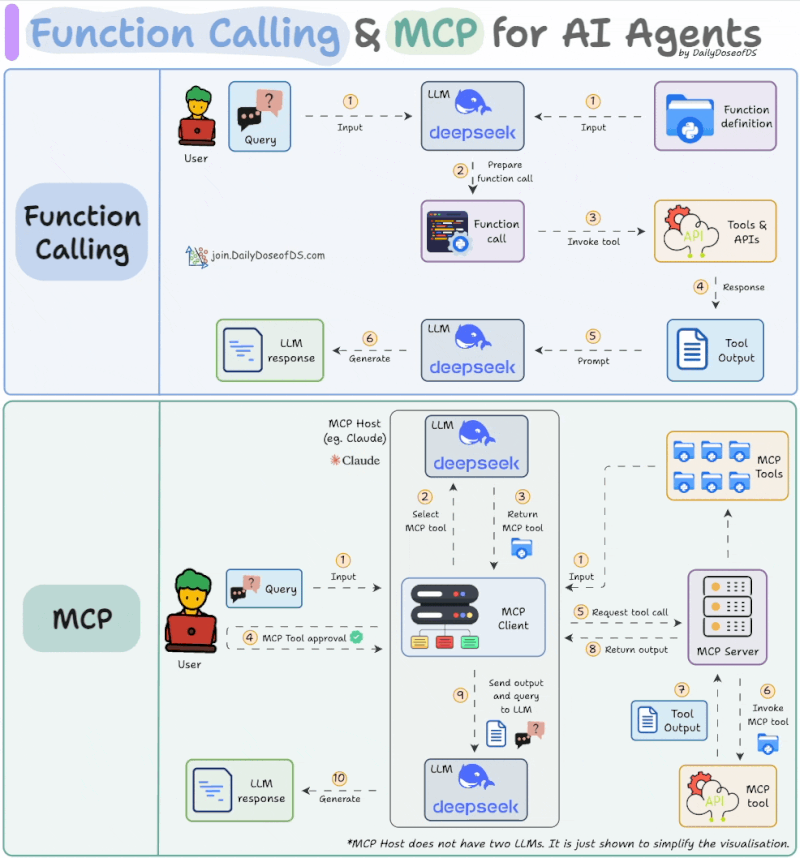 <출처>https://www.linkedin.com/feed/update/urn:li:activity:7319639412240261120/
<출처>https://www.linkedin.com/feed/update/urn:li:activity:7319639412240261120/
- 도구 탐색: 사용 가능한 MCP 도구 목록(Tool List)을 가져옵니다.
- 도구 선택: LLM이 사용자의 요청을 해결하기 위해 특정 MCP 서버의 특정 도구를 선택합니다.
- 사용자 승인: LLM이 선택한 도구를 사용하기 전에 사용자에게 명시적인 동의를 구합니다.
- 도구 실행 및 결과 반환: 승인이 완료되면 MCP 서버의 도구를 호출하고, 그 결과를 받아 최종 응답을 생성합니다.
가장 큰 차이점은 '사용자 승인' 단계의 존재와, 도구 목록을 가져오는 표준화된 프로토콜이 있다는 점입니다. 물론, Claude Code 등에서 Shift+Tab을 눌러 '자동 승인(Auto Accept)' 모드를 켜면 사용자의 개입 없이 모든 과정을 자동으로 처리하게 되어 사실상 함수 호출과 경험적인 차이가 줄어들기도 합니다.
성공의 척도: MCP-Bench를 이용한 성능 평가
본격적인 모델 개발에 앞서, 우리는 '무엇으로 성공을 측정할 것인가?'를 명확히 해야 했습니다. 모델의 성능을 객관적으로 평가할 기준이 없다면 개발 방향이 흔들릴 수 있기 때문입니다. 저희는 이 시기에 공개된 MCP-Bench라는 평가 도구를 사용하기로 했습니다.
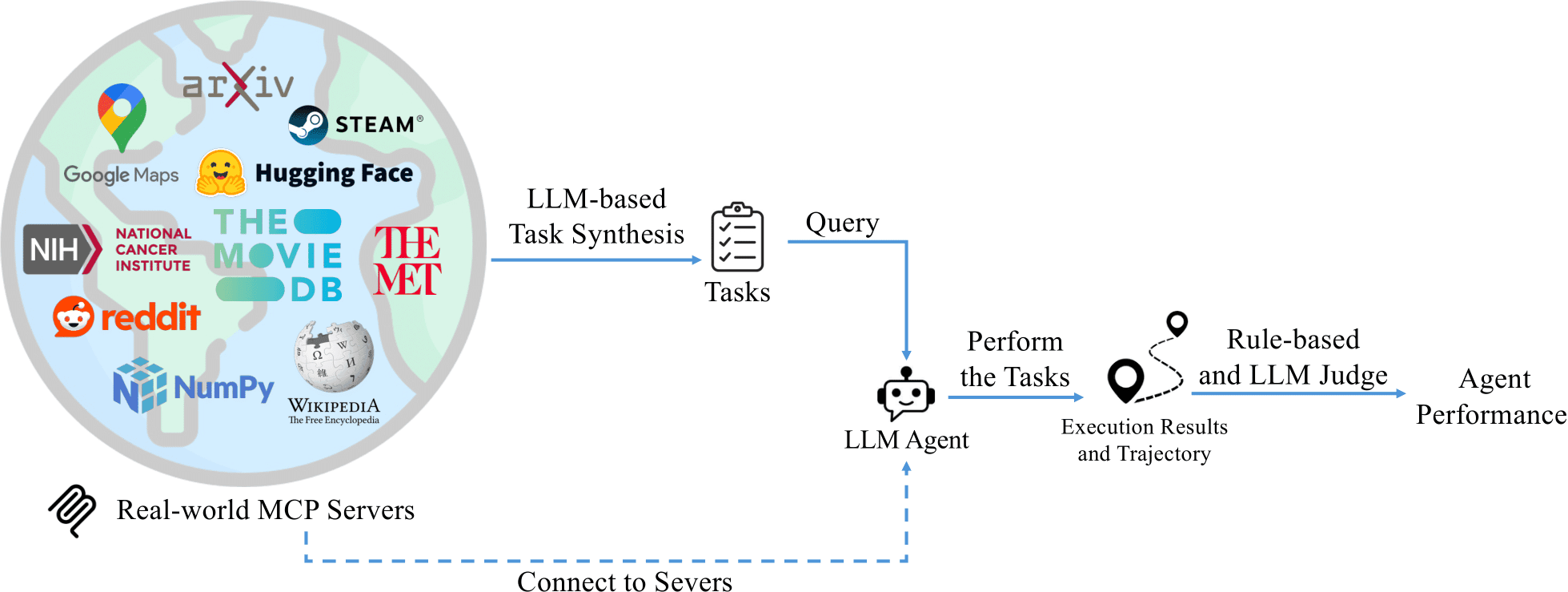 이미지 출처 : https://github.com/Accenture/mcp-bench
이미지 출처 : https://github.com/Accenture/mcp-bench
MCP-Bench는 Google Maps, Wikipedia, Steam 등 실제 운영 중인 28개의 MCP 서버를 기반으로 LLM 에이전트의 성능을 종합적으로 평가하는 벤치마크입니다. 평가는 크게 두 가지 축으로 이루어집니다.
-
규칙 기반(Rule-based) 평가: 모델이 얼마나 기술적인 명세를 잘 지키는지를 평가합니다.
⦁ 스키마 이해(Schema Understanding): 유효한 도구 이름을 사용했는지, MCP 스키마 규약을 준수했는지, 실제 서버 호출이 성공했는지를 확인합니다.
-
LLM을 평가자로 사용(LLM-as-Judge): 모델이 얼마나 문맥을 잘 이해하고 효율적으로 과업을 수행하는지를 평가합니다.
⦁ 문맥 이해(Contextual Understanding): 주어진 과업을 성공적으로 완수했는지, 불필요한 호출 없이 적절한 도구를 사용했는지, 여러 도구를 효율적으로 계획하여 사용했는지 등을 더 강력한 LLM(예: GPT-4)이 평가합니다.
MCP-Bench의 리더보드의 결과는 다음과 같습니다.
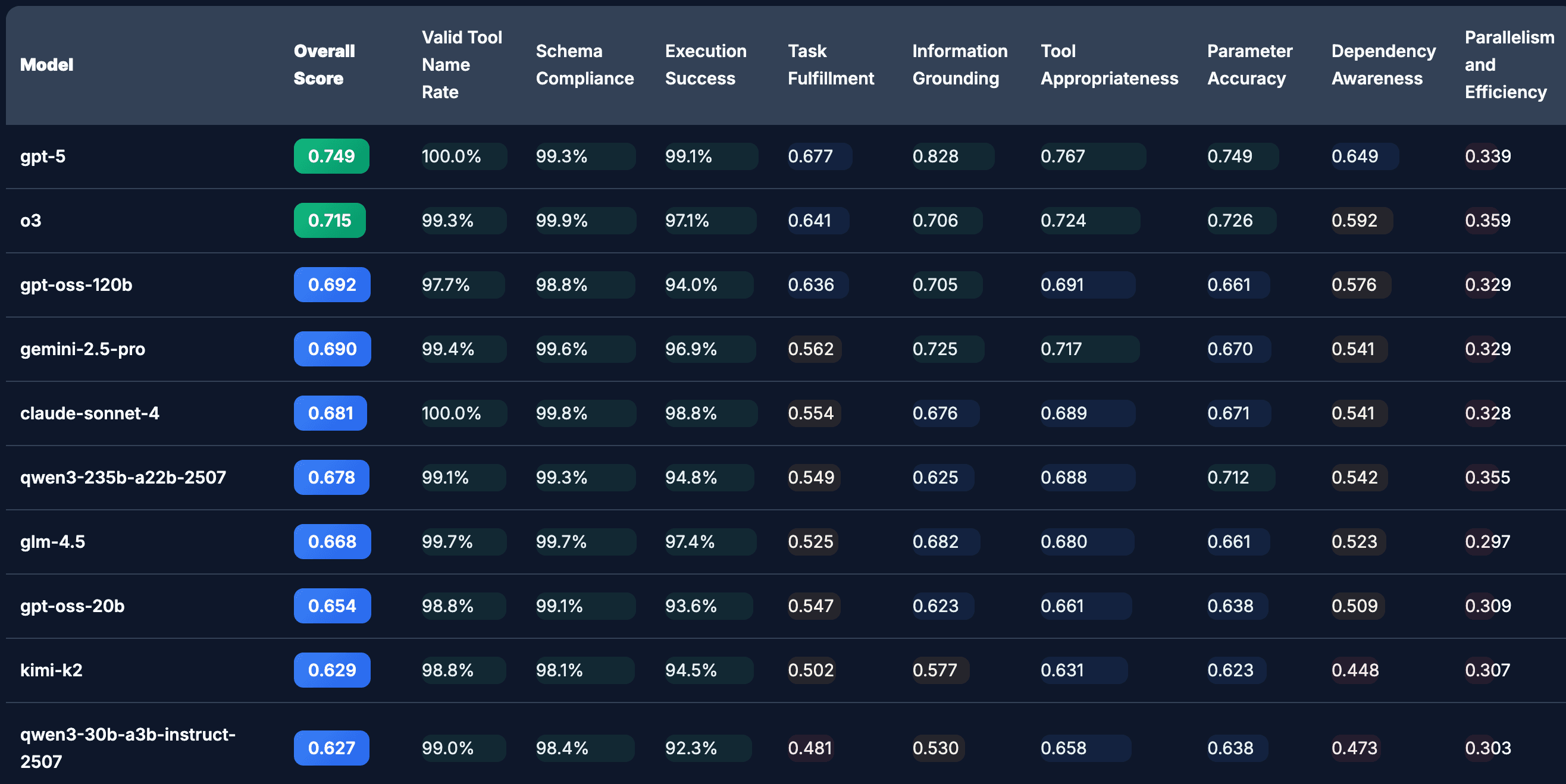 <출처> https://huggingface.co/spaces/mcpbench/mcp-bench
<출처> https://huggingface.co/spaces/mcpbench/mcp-bench
예상대로 GPT-5가 최상위권을 차지하고 있으며, 저희가 개선하고자 하는 Gemma-3-27B나 Llama-3.1-8B 같은 오픈소스 모델들은 하위권에 머물러 있었습니다. 우리의 목표는 사이드카 모델을 통해 이 하위권 모델들의 점수를 상위권으로 끌어올리는 것이었습니다.
학습 파이프라인 구축기: 험난했던 여정
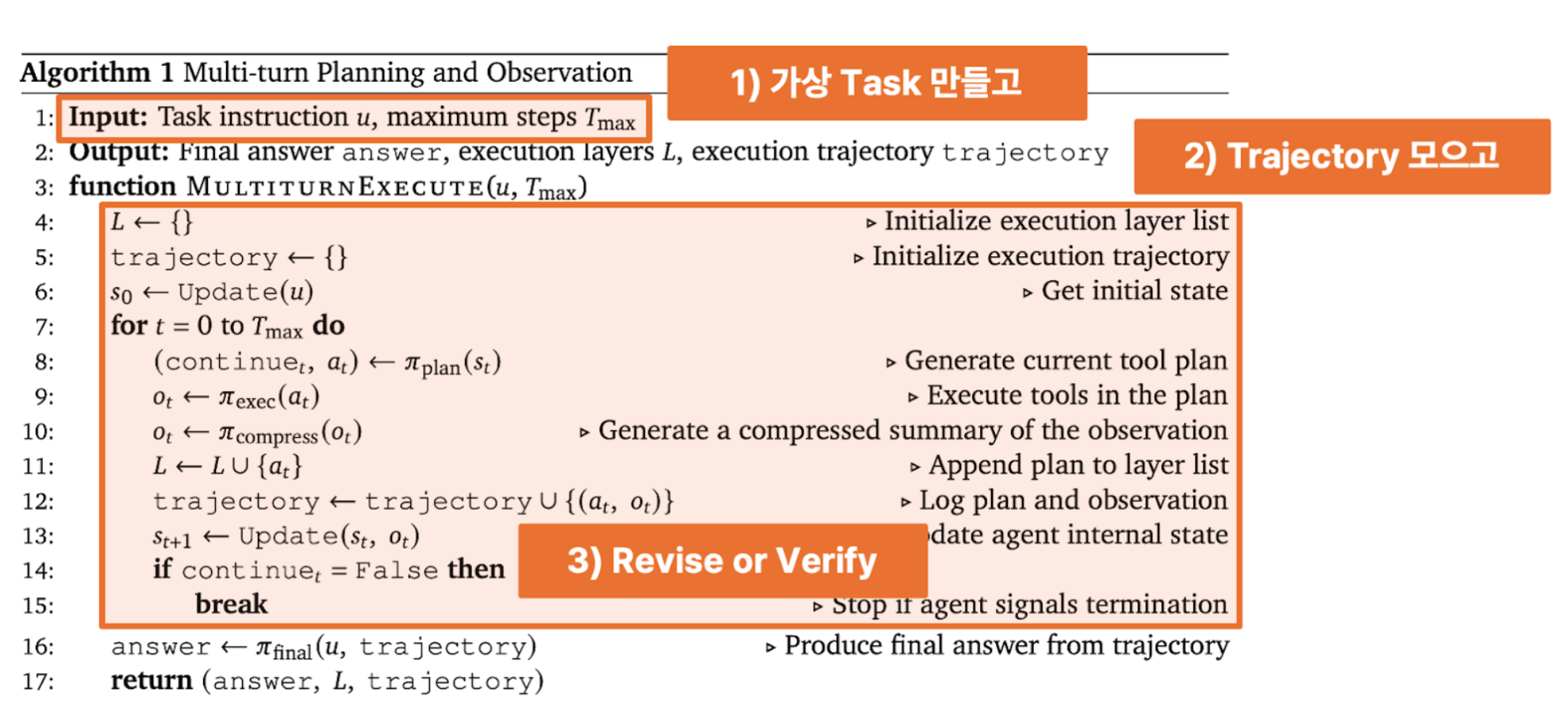 <출처> https://www.arxiv.org/pdf/2508.20453
<출처> https://www.arxiv.org/pdf/2508.20453
1단계: 학습 데이터 생성
MCP-Bench는 평가용 데이터셋만 제공하므로, 학습에 사용할 별도의 데이터셋을 구축해야 했습니다. 평가 데이터를 학습에 사용하면 '테스트셋 오염(Test set contamination)' 문제가 발생하여 올바른 성능 측정이 불가능하기 때문입니다. 저희는 GPT-5와 같은 강력한 모델을 사용하여 학습 데이터를 합성(Synthetic Generation)하는 방식을 택했습니다. 과정은 다음과 같습니다.
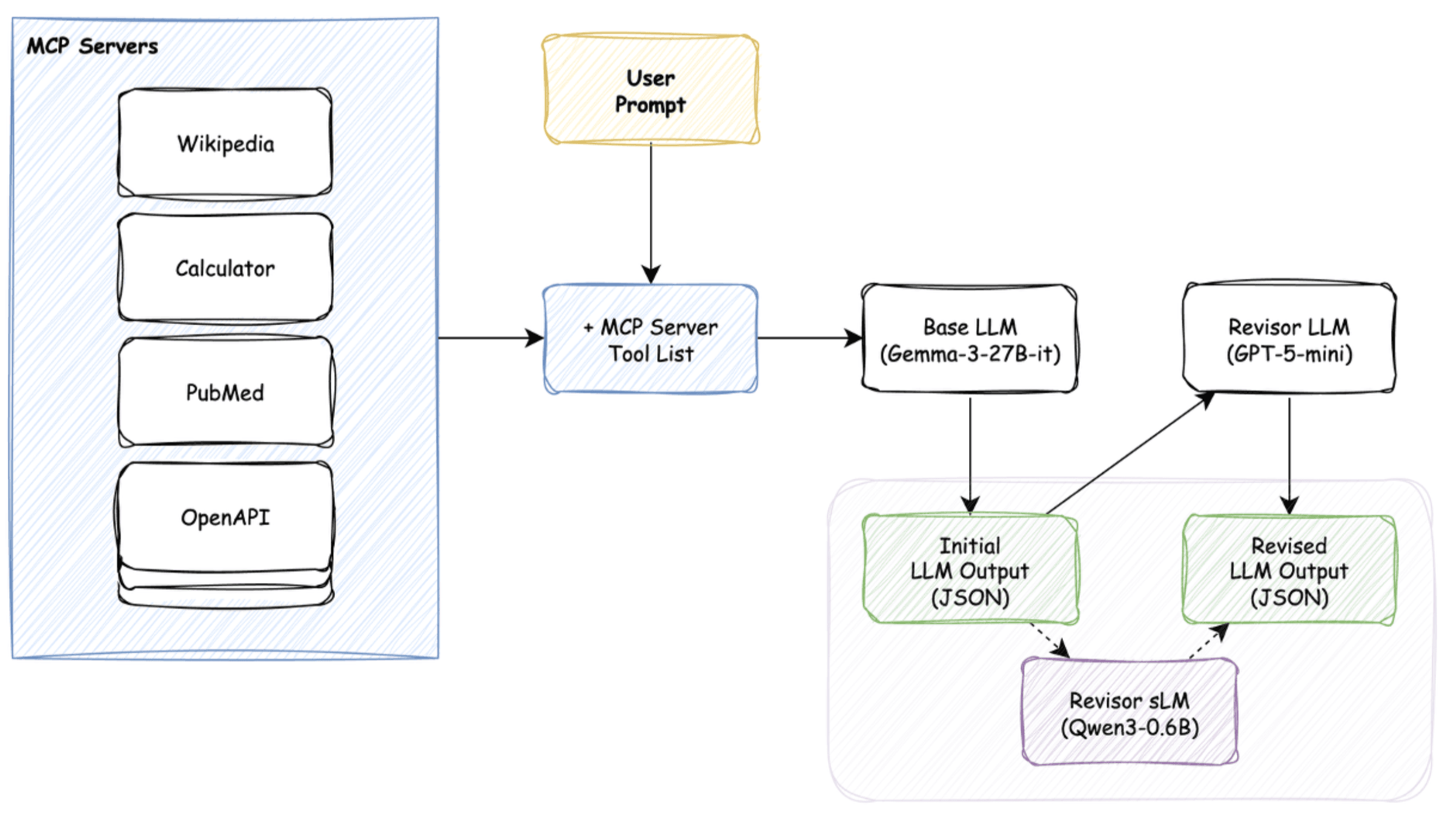
- 입력(Input): MCP 서버와 그 안의 도구 명세(Tool a, Tool B, ...)를 제공합니다.
- 생성(Generation): GPT-5 모델이 이 도구들을 활용할 수 있는 복잡하고 모호한(Fuzzy) 사용자 시나리오(User Prompt)를 생성합니다.
- 정답(Golden Label): 동시에, 해당 시나리오를 해결하기 위한 최적의 도구 호출(함수, 파라미터 등)을 정답 데이터로 함께 생성합니다.
이렇게 생성된 (사용자 시나리오, 정답 도구 호출) 쌍은 우리 사이드카 모델 학습의 기반이 됩니다.
2단계: 첫 번째 시도 - 지도 미세조정(SFT)과 실패
가장 간단하고 직관적인 방법은 지도 미세조정(Supervised Fine-Tuning, SFT)이었습니다.
- 베이스 LLM(예: Gemma-3-27B)에게 합성된 사용자 시나리오를 입력하여 불완전한 JSON 결과물(Initial LLM Output)을 얻습니다.
- 더 강력한 Revisor LLM(예: GPT-5-mini)에게 이 불완전한 결과물을 입력하여 완벽하게 수정된 JSON 결과물(Revised LLM Output)을 얻습니다.
- Initial LLM Output을 입력으로,
Revised LLM Output을 정답으로 하여 사이드카 sLM을 SFT 방식으로 학습시킵니다.
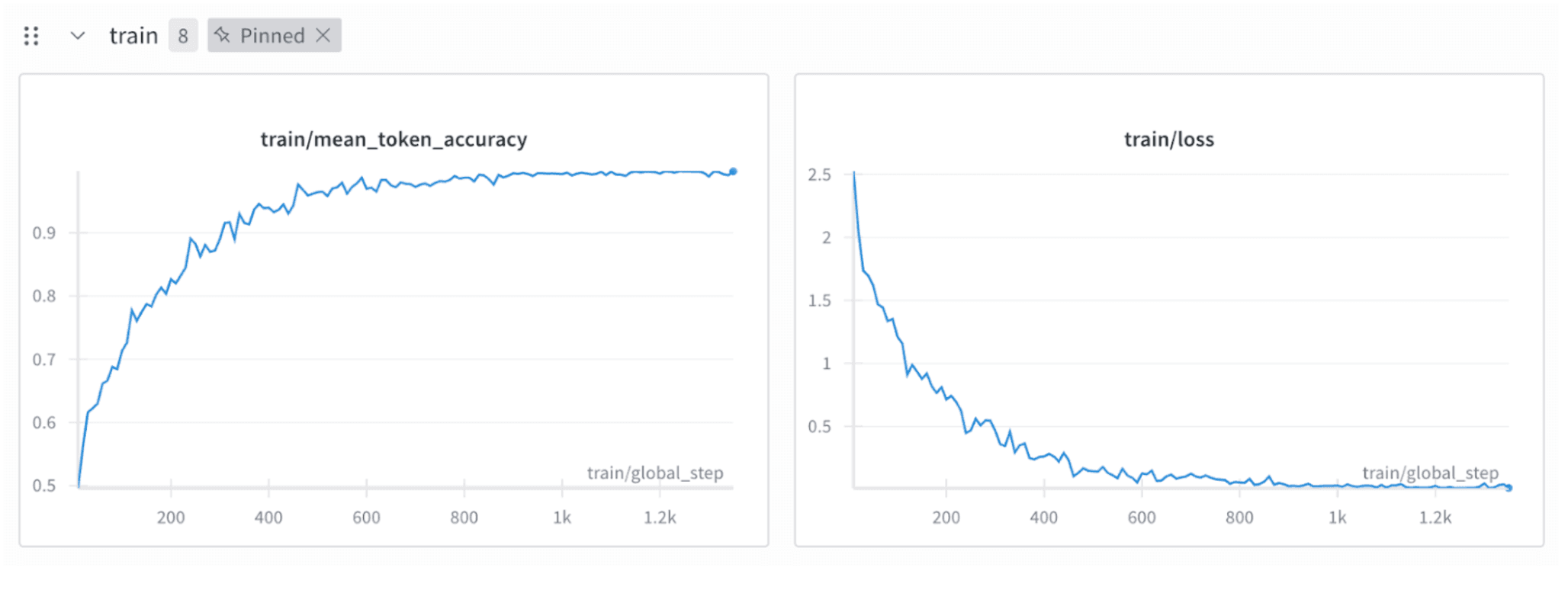
이론적으로 완벽해 보였지만, 결과는 실패였습니다. 학습 손실(Loss) 그래프는 비정상적으로 예쁘게 떨어졌고, 정확도(Accuracy)는 빠르게 수렴했습니다. 머신러닝에서 그래프가 이렇게 예쁘다는 것은 보통 무언가 잘못되었다는 신호입니다.
원인은 베이스 LLM이 생성한 초기 결과물과 수정된 결과물 간의 차이가 너무 작다는 데 있었습니다. 최신 오픈소스 LLM들은 불완전하더라도 어느 정도 JSON의 구색은 갖추려 노력하기 때문에, 두 텍스트의 토큰 대부분(90% 이상)이 일치했습니다. 모델 입장에서는 미세한 오류를 수정하는 복잡한 방법을 배우기보다, 그냥 입력값을 그대로 복사하는 것이 손실을 줄이는 가장 쉬운 방법이었던 것입니다. 모델은 '수정'이 아닌 '복사'를 학습해버렸습니다.
3단계: 두 번째 시도 - 강화학습(RL)으로의 전환
SFT가 실패로 돌아가자, 저희는 더 복잡하지만 강력한 강화학습(Reinforcement Learning, RL)으로 눈을 돌렸습니다. 아이디어는 간단합니다. 사이드카 모델이 결과물을 생성할 때마다, MCP-Bench의 평가 지표를 **보상(Reward)**으로 주어 더 좋은 결과물을 생성하도록 유도하는 것입니다. 전체적인 RL 학습 흐름은 다음과 같습니다.
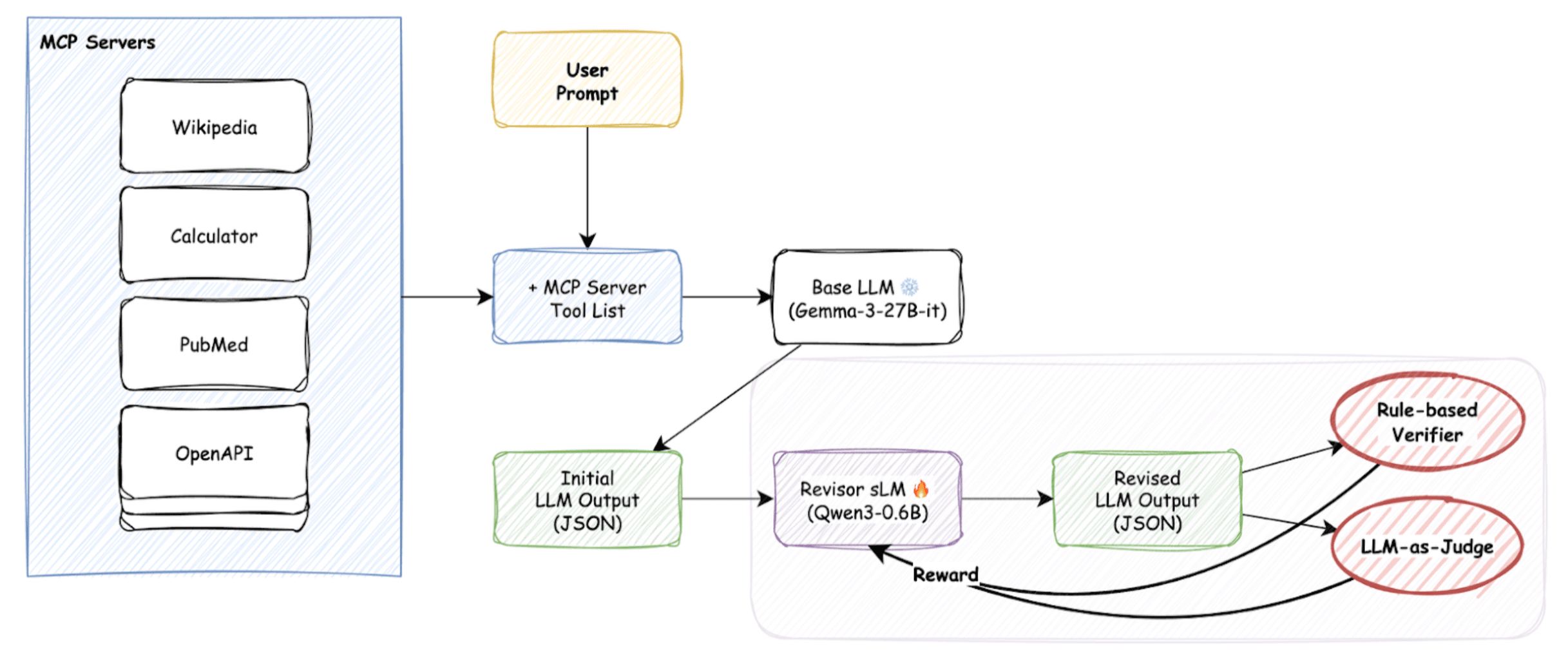
-
베이스 LLM이 초기 결과물(JSON)을 생성합니다.
-
학습 중인 사이드카 sLM(정책 모델)이 이 결과물을 입력받아 수정된 결과물을 생성합니다.
-
이 수정된 결과물을 검증기(Verifier)에 통과시킵니다.
⦁ 규칙 기반 검증기: JSON 형식이 유효한가? MCP 스키마를 준수하는가? ⦁ LLM 심판 검증기: 태스크 해결에 도움이 되는 유용한 호출인가?
-
검증 결과에 따라 계산된 점수를 보상으로 사이드카 sLM에 전달하여 가중치를 업데이트합니다.
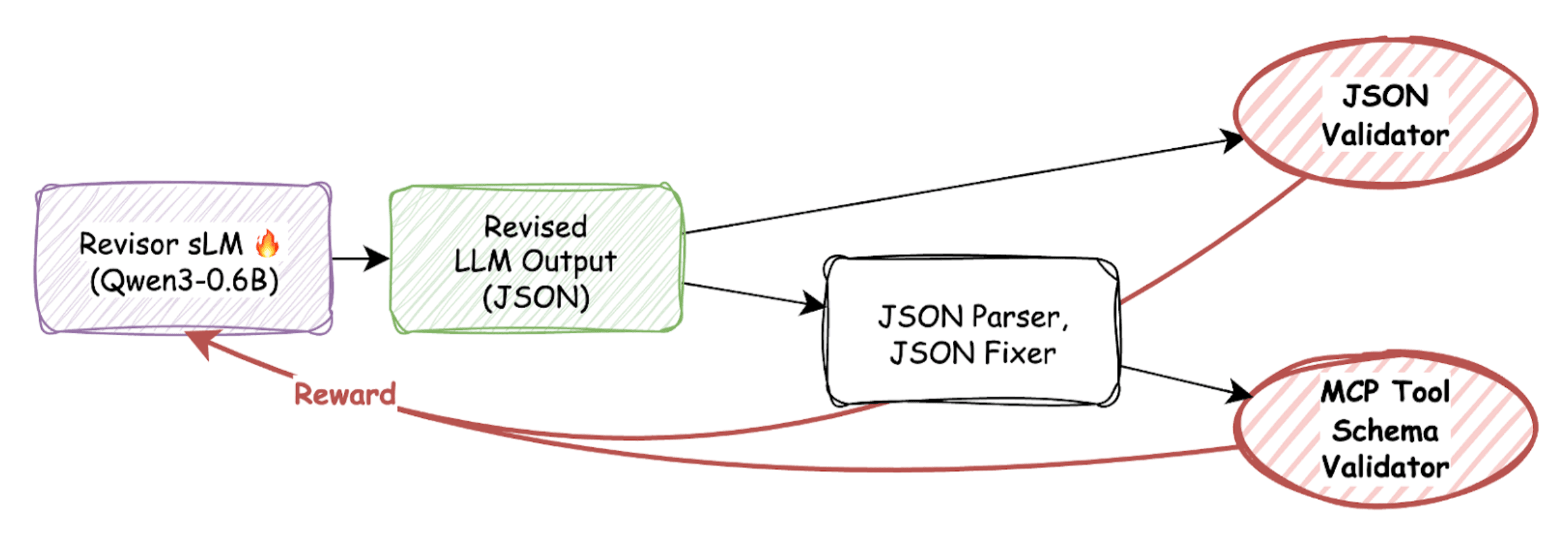
이 과정에서 또 다른 함정이 있었습니다. 바로 '파서(Parser)와의 싸움'입니다. 모델이 JSON 외에 "Okay, I will generate..."와 같은 불필요한 텍스트를 함께 출력하는 경우가 많았는데 , 이를 처리하기 위해 파서를 도입하자 모델이 내용의 질을 높이기보다 파서가 잘 처리할 수 있는 형식만 흉내 내는 꼼수를 부렸습니다. 이를 해결하기 위해, 최종 검증 전에 JSON 파서 및 교정기(JSON Fixer) 단계를 추가하여, 형식의 완벽함이 아닌 내용의 정확성에 기반한 보상이 전달되도록 파이프라인을 수정했습니다.
기술적 난관과 해결책
1. 거대한 컨텍스트 길이
에이전트 태스크는 여러 도구의 설명과 예제, 그리고 멀티턴 대화 기록까지 컨텍스트에 포함해야 하므로 입력 토큰의 길이가 상상을 초월합니다. 저희 데이터셋의 경우, 평균 입력 길이는 약 57,000 토큰, 최대 길이는 128,000 토큰에 달했습니다.
처음 사이드카 모델로 고려했던 Qwen3-0.6B는 최대 컨텍스트 길이가 40,000 토큰에 불과해 사용할 수 없었습니다. 이를 해결하기 위해 RoPE 스케일링(YaRN) 기법으로 컨텍스트 길이를 인위적으로 확장해 보았지만, 특정 길이를 넘어가자 모델의 지시 이행 능력이 급격히 저하되며 무작위 텍스트를 생성하는 등 심각한 성능 저하를 겪었습니다.

--> 해결책: 결국, 저희는 natively 262,000 토큰이라는 긴 컨텍스트를 지원하는 Qwen3-4B-Instruct 모델로 교체하여 이 문제를 해결했습니다.
2. 효율적인 RL 프레임워크
온라인 RL 학습은 매 스텝마다 모델의 생성(Inference)과 업데이트가 반복되므로 속도가 매우 중요합니다.
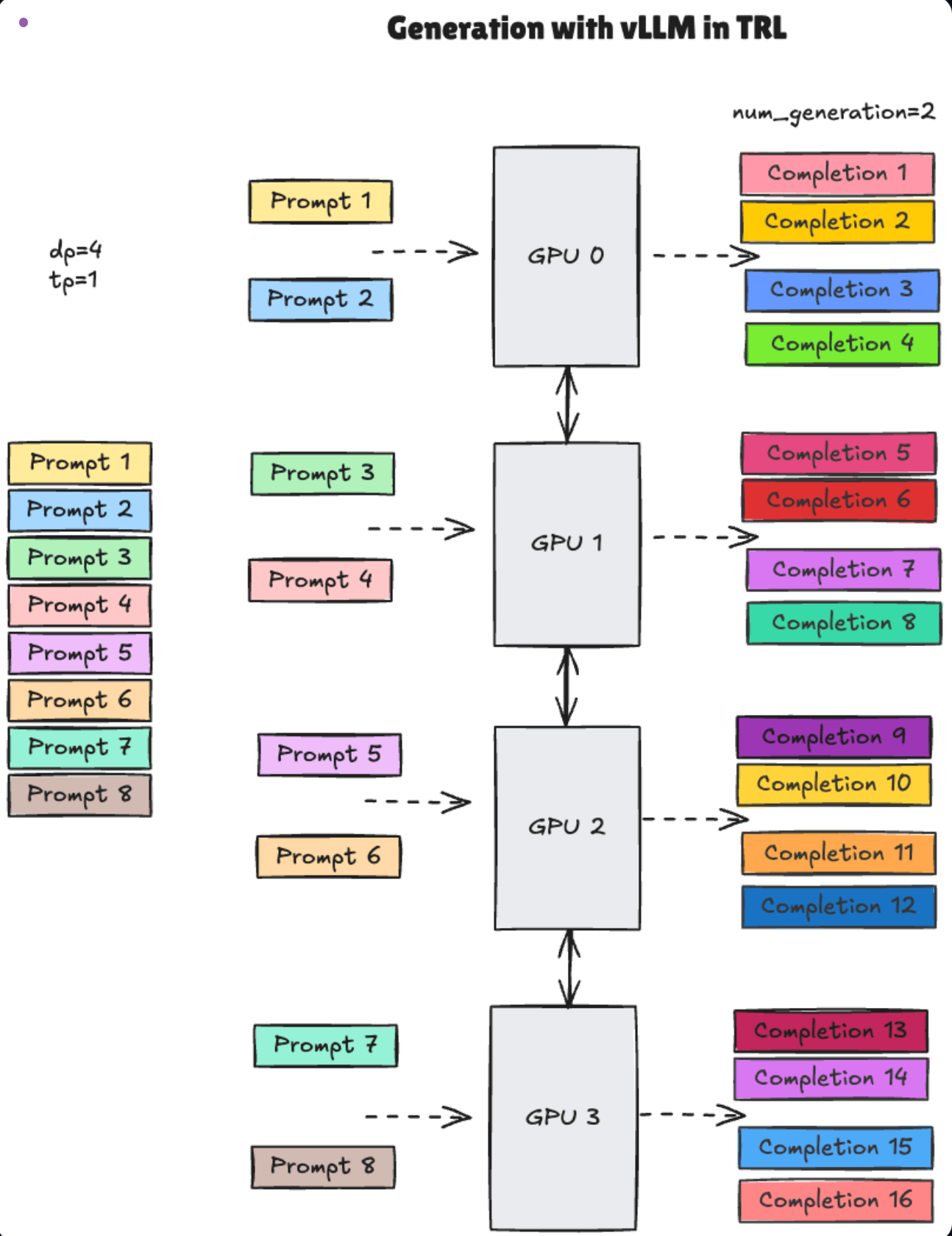
--> 해결책: 저희는 Hugging Face의 TRL(Transformer Reinforcement Learning) 라이브러리와 GRPO(Group Relative Policy Optimization) 알고리즘을 기반으로 학습 환경을 구축했습니다. 특히, TRL이 지원하는 vLLM 추론 엔진 통합 기능을 활용하여 생성 속도를 크게 향상시켰습니다. TRL 학습 루프가 vLLM 서버에 HTTP 요청으로 업데이트된 가중치를 동기화하고, vLLM은 이를 받아 빠르게 다음 생성을 수행하는 방식으로 파이프라인을 구성했습니다.
결과 및 향후 과제
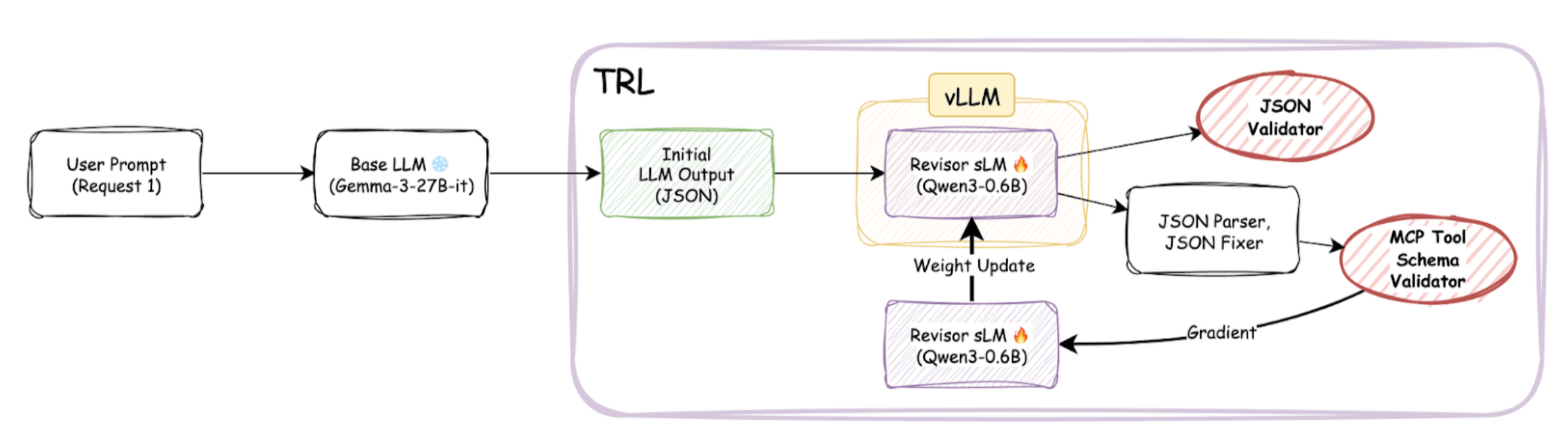
RL 기반으로 학습한 결과, Llama-3.1-8B 모델을 기준으로 사이드카 모델 적용 후 JSON 형식, 도구 이름, 스키마, 파라미터 유효성 등 규칙 기반 평가 항목에서 유의미한 성능 향상을 확인할 수 있었습니다.
하지만 이 프로젝트는 아직 '시도기'이며, 완성까지는 여러 과제가 남아있습니다.
⦁ LLM 평가 보상 통합: 현재는 규칙 기반 보상만으로 학습을 진행했지만, 앞으로는 LLM 심판이 평가하는 '유용성' 점수까지 보상 함수에 통합하여 모델의 질적 성능을 높일 계획입니다.
⦁ 고효율 프레임워크 도입: TRL보다 더 빠르고 에이전트 학습에 특화된 기능을 제공하는 ByteDance의 VERL과 같은 최신 RL 프레임워크 도입을 검토하고 있습니다.
⦁ 멀티턴 처리 개선: 현재는 대화의 최종 결과물만 평가하지만, 대화의 중간 과정까지 고려하여 보상을 제공하는 방식으로 멀티턴 처리 능력을 고도화할 필요가 있습니다.
앞으로 나아갈 길
지금까지 LLM의 MCP 호환성 문제를 해결하기 위해 '사이드카 리바이저'라는 작은 모델을 학습시키려 했던 저희의 길고 험난했던 여정을 공유해 드렸습니다. 간단한 SFT 시도의 실패부터 복잡한 RL 파이프라인 구축, 그리고 그 과정에서 마주한 수많은 기술적 난관까지, 이번 시도는 에이전틱 AI를 개발하는 것이 결코 쉽지 않은 과제임을 다시 한번 느끼게 해주었습니다.
하지만 이 사이드카 모델이라는 접근법은 특정 LLM에 종속되지 않고, 다양한 오픈소스 모델들을 최소한의 비용으로 강력한 에이전트 시스템에 통합할 수 있는 실용적이고 잠재력 있는 방향이라고 믿습니다. 저희의 실험이 대-에이전트 시대를 준비하는 다른 개발자분들께 작은 도움이 되기를 바랍니다.
긴 글 읽어주셔서 감사합니다.