
래블업은 업스테이지 컨소시엄의 인프라 파트너로 정부의 '독자 AI 파운데이션 모델(독파모)' 사업에 참여하고 있습니다. SK텔레콤 '해인' 클러스터의 NVIDIA B200 GPU 500+개를 활용해 업스테이지의 Solar Open(102B MoE 모델)을 사전학습시키는 프로젝트인데요, 이 규모의 클러스터를 운영하면서 가장 먼저 마주하는 현실이 있습니다. 장애는 피할 수 없다는 것입니다.
Meta의 연구[1]에 따르면 1,024개 GPU 학습의 평균 장애 발생 간격(MTTF)은 단 7.9시간이고, 저희 클러스터에서도 약 2개월간 13개 노드에서 17건의 장애가 발생했습니다. 이러한 GPU 하나 하나의 장애가 치명적인 이유가 있는데요, 분산 학습에서는 GPU 하나의 장애는 곧 전체 학습 중단을 의미합니다.
따라서 학습 중단과 복구에 따른 비효율을 줄이기 위해 저희는 선제적 장애 탐지 시스템을 구축하고 있습니다. 해당 시스템의 목적은 장애가 일어날 GPU를 미리 예측하고 대응하여 다운타임을 최소화 하는 것입니다. 이 글에서는 그 첫 단계로, 클러스터에서 어떤 데이터를 어떻게 수집하고 있는지, 그리고 실제 장애 사례에서 어떤 이상 신호가 포착되었는지를 공유합니다.
학습 환경 소개
장애를 탐지하려면 먼저 모니터링할 환경을 이해해야 합니다. 어떤 메트릭이 무엇을 측정하는지 알려면, 하드웨어 구성과 네트워크 구조를 아는 것이 필수입니다.
클러스터 구성
업스테이지의 Solar Open[2]은 102B 파라미터, 12B 활성 파라미터의 MoE 모델로, 128개의 라우팅 Expert와 1개의 공유 Expert로 구성됩니다. 이 모델을 학습하기 위해 아래와 같은 클러스터를 구성했습니다:
| 항목 | 값 | 비고 |
|---|---|---|
| 노드 수 | 63대 | 60대 학습용, 3대 스페어 |
| GPU 수 | 504개 | 노드당 8개 B200 |
| GPU 모델 | NVIDIA B200 | Blackwell 아키텍처 |
| 노드당 메모리 | 2TiB | DDR5 |
| GPU당 메모리 | 192GB | HBM3e |
| 저장소 | 2PB | NFS (VAST Data) |
노드(node): GPU 8개가 장착된 물리 서버 한 대를 의미합니다.
60개 노드(480 GPU)가 학습에 참여하고, 나머지 3개 노드는 장애 발생 시 교체용 스페어로 운영됩니다. 학습에는 HSDP(Hybrid Sharding Data Parallel) 방식을 사용하는데, 10개 노드(80 GPU)를 하나의 FSDP Sharding Group으로 구성하고 총 6개의 Replica를 운영합니다. 그룹 내에서는 FSDP로 파라미터를 분산하여 메모리 효율을 높이고, 그룹 간에는 gradient만 동기화하여 통신량을 최소화하는 구조입니다.
노드 내부 구조
각 노드의 내부는 이렇게 생겼습니다:
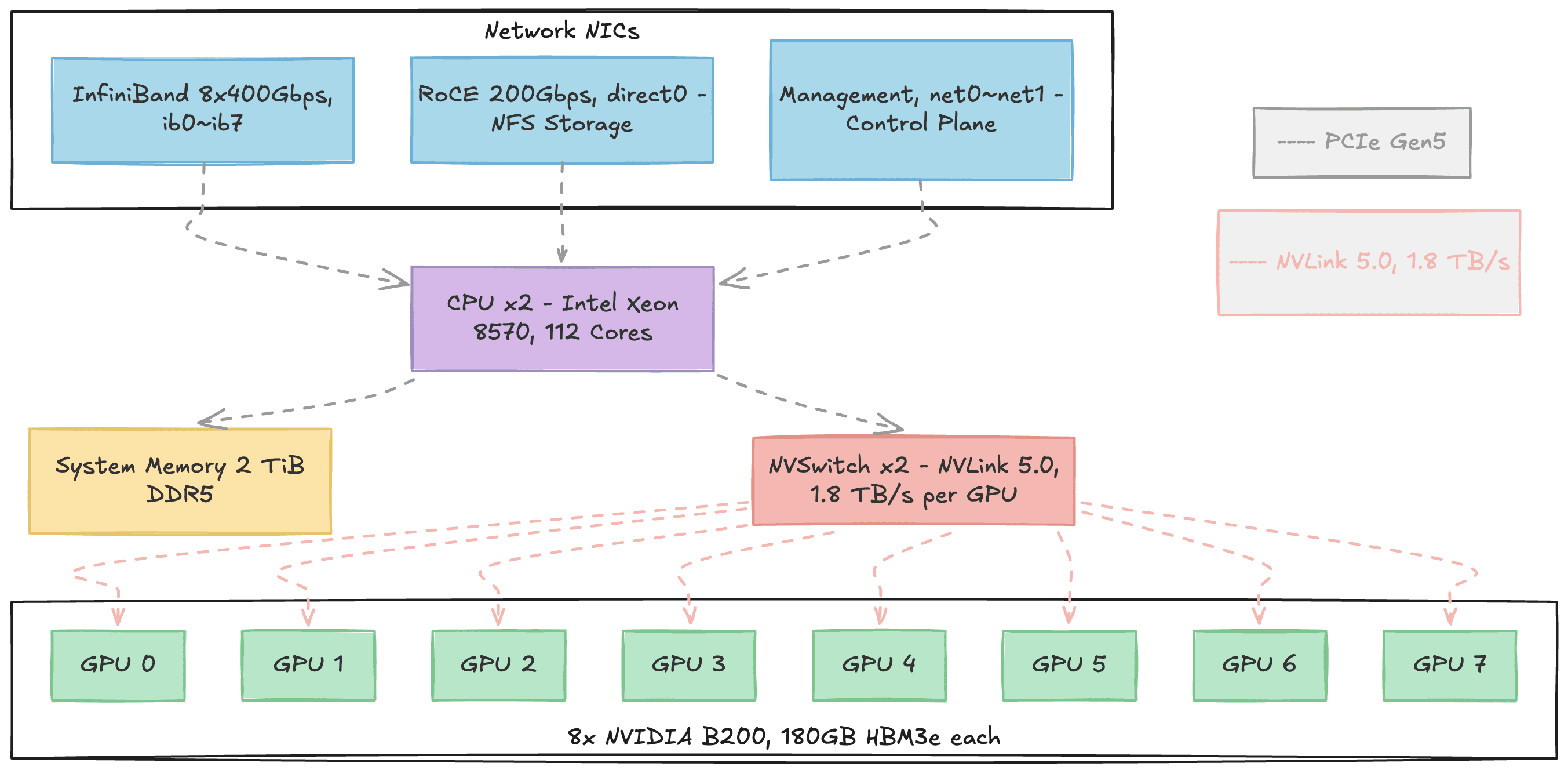
그림 1. DGX B200 노드 한 대의 내부 구조. 상단의 네트워크 NIC 3종(InfiniBand, RoCE, Management)이 PCIe를 통해 CPU에 연결되고, 하단의 8개 B200 GPU는 NVSwitch를 통해 all-to-all로 연결된다. 회색 점선은 PCIe Gen5, 분홍 점선은 NVLink 5.0 경로를 나타낸다.
각 노드는 NVIDIA DGX B200으로, 8개의 B200 GPU가 핵심입니다. 각 GPU에는 192GB의 HBM3e 메모리가 탑재되어있어 모델 파라미터, gradient, activation이 여기에 상주합니다. 실제 AI 연산은 전부 이 GPU들이 수행합니다.
CPU는 Intel Xeon 8570 2소켓(총 112코어) 구성이지만, 학습에서의 역할은 보조적입니다. 학습 데이터를 스토리지에서 읽어와 전처리하고, GPU에 작업을 분배하며, 다음 배치를 미리 준비하는 일을 합니다. 2TiB의 DDR5 시스템 메모리는 이 과정에서 NFS 페이지 캐시와 데이터 버퍼로 활용됩니다.
노드 안에서 8개 GPU는 NVSwitch 2개를 통해 서로 연결됩니다. NVLink 5.0 프로토콜로 all-to-all 연결을 제공하며, 어떤 GPU든 다른 GPU와 1.8TB/s(양방향)의 전대역폭으로 직접 통신할 수 있습니다. 외부 통신을 위해서는 InfiniBand NIC 8포트(각 400Gbps)가 노드 간 GPU 데이터 전송을 담당하고, RoCE NIC(200Gbps)이 VAST Data NFS 스토리지에 연결되어 학습 데이터를 공급합니다.
각 구성 요소의 역할을 알아두면, 나중에 메트릭이 어떤 장애와 관련 있는지 파악하는 데 도움이 됩니다. 예를 들어, GPU 온도나 전력 메트릭은 GPU 자체의 상태를, NVLink 대역폭 메트릭은 노드 내 GPU 간 통신의 상태를, NFS 관련 메트릭은 스토리지 병목의 징후를 반영합니다.
네트워크 구조: NVLink vs InfiniBand
분산 학습에서 핵심이 되는 두 가지 네트워크가 있습니다.
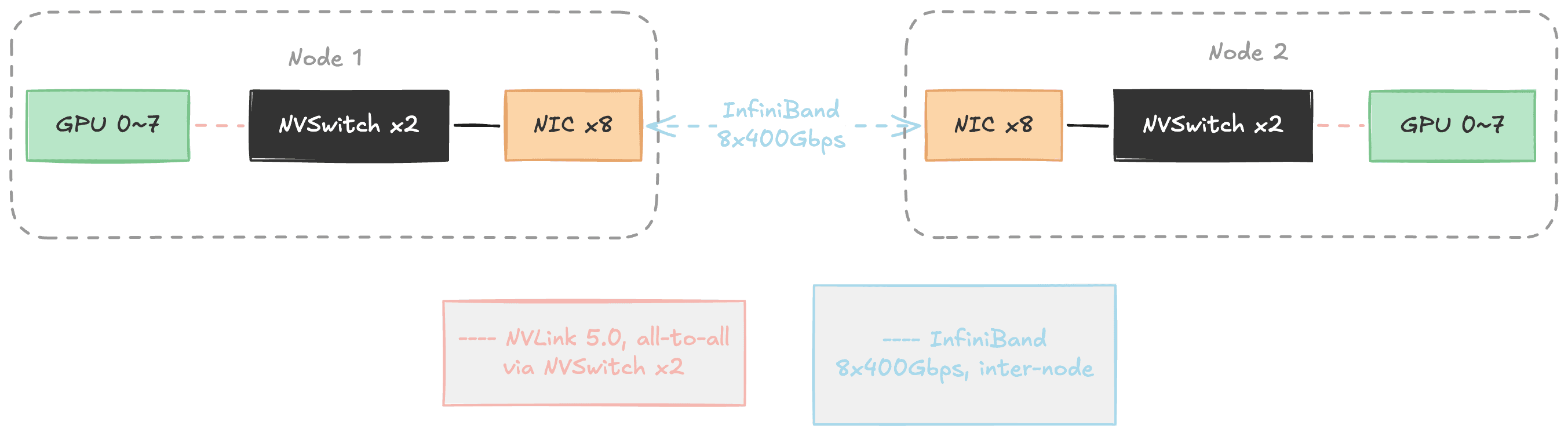
그림 2. 분산 학습의 두 가지 네트워크. 노드 내부에서는 NVSwitch가 8개 GPU를 NVLink로 연결하고(분홍), 노드 간에는 InfiniBand가 NIC를 통해 통신한다(파랑). 단일 GPU의 NVLink 대역폭(1.8TB/s)이 노드 전체 InfiniBand 대역폭(~400GB/s)의 약 4.5배다.
NVLink는 NVSwitch 2개를 통해 노드 내 8개 GPU를 all-to-all로 연결합니다. GPU 하나의 NVLink 대역폭은 1.8TB/s(양방향)입니다. 반면 InfiniBand는 노드 간 통신을 담당하며, 8개 포트를 합산해도 약 400GB/s로 NVLink 한 포트의 약 1/4 수준입니다.
| 구분 | NVLink | InfiniBand |
|---|---|---|
| 범위 | 노드 내부 (8 GPU) | 노드 간 |
| 연결 대상 | GPU ↔ GPU (같은 노드) | NIC ↔ NIC (다른 노드) |
| 속도 | GPU당 1.8 TB/s (양방향) | 8포트 합산 ~400 GB/s |
| 용도 | FSDP 통신 (노드 내) | FSDP 통신 (노드 간) + DDP gradient 동기화 |
이 속도 차이가 분산 학습의 구조를 결정합니다. HSDP(Hybrid Sharded Data Parallel)는 두 네트워크를 계층적으로 활용합니다. 10개 노드로 구성된 FSDP 그룹 안에서 같은 노드의 GPU끼리는 빠른 NVLink로 통신하고, 노드를 넘는 통신은 InfiniBand를 사용합니다. 6개 복제본 간 gradient 동기화(DDP all-reduce)도 InfiniBand 경로입니다. 따라서 InfiniBand에 문제가 생기면 노드 간 통신 전체가 영향받고, NVLink에 문제가 생기면 해당 노드 내 GPU 간 통신이 마비됩니다. 이것이 네트워크 관련 메트릭을 모니터링하는 이유입니다.
장애의 현실
대규모 클러스터에서의 장애 확률
GPU가 많아질수록 장애 확률은 급격히 높아집니다. 아래 Meta의 연구[1] 데이터를 보면 데이터를 통해 확인할 수 있습니다.
| GPU 수 | 평균 장애 발생 간격 (MTTF) |
|---|---|
| 8 | 47.7일 |
| 64 | 5.9일 |
| 256 | 35.6시간 |
| 1,024 | 7.9시간 |
반대로 말하면, 저희의 480개 GPU 환경에서도 수 시간에 한 번꼴로 장애가 발생할 수 있다는 이야기입니다.
장애 유형
그렇다면 대규모 GPU 클러스터에서는 어떤 장애가 많이 발생할까요? ByteDance의 Minder 연구[3]에서 자사 학습 클러스터(수만 대 GPU)의 실제 장애를 분석한 결과가 있습니다.
| 분류 | 장애 유형 | 비율 |
|---|---|---|
| 하드웨어 (55.8%) | ECC Error (메모리 오류) | 38.9% |
| PCIe Downgrading | 6.6% | |
| NIC Dropout | 5.7% | |
| GPU Card Drop | 2.0% | |
| NVLink Error | 1.7% | |
| 소프트웨어 (28.0%) | CUDA Execution Error | 14.6% |
| GPU Execution Error | 7.7% | |
| HDFS Error | 5.7% | |
| 네트워크 (6.0%) | Machine Unreachable | 6.0% |
| 기타 | Others | 10.3% |
하드웨어 장애가 절반 이상(55.8%)이고, 그중 ECC Error가 38.9%로 압도적입니다.
우리 클러스터의 실제 장애 기록
약 2개월간의 학습 기간 동안 저희 클러스터에서 실제로 발생한 하드웨어 장애(사용자 에러 제외)입니다. 표에서 XID는 NVIDIA GPU가 하드웨어나 드라이버 문제 발생 시 기록하는 에러 코드입니다.
| 분류 | 장애 유형 | 비율 |
|---|---|---|
| GPU 하드웨어 (58.8%) | NVLink Error (XID 145/149) | 23.5% |
| GPU Fallen Off Bus (XID 79) | 11.8% | |
| ECC Error (XID 94) | 11.8% | |
| GSP RPC Timeout (XID 119) | 5.9% | |
| NVLink Failure (non-XID) | 5.9% | |
| 인프라 (17.6%) | Node Unrecognized | 11.8% |
| Performance Degradation | 5.9% | |
| 기타 (23.5%) | Others | 23.5% |
Minder[3]에서는 ECC Error(38.9%)가 압도적 1위였지만, 저희 클러스터에서는 NVLink Error(23.5%)가 가장 빈번했습니다. ECC Error는 11.8%로, Minder 대비 상대적으로 적었습니다. GPU 하드웨어 장애가 과반을 차지한다는 점은 동일하지만, 세부 분포는 클러스터 환경에 따라 다를 수 있음을 보여줍니다.
반응적 대응에서 선제적 대응으로
이런 장애에 전통적인 반응적(reactive) 방식으로 대응하면, 장애가 발생한 뒤에야 감지하고 복구하는 동안 전체 학습이 중단됩니다. 저희가 목표로 하는 선제적(proactive) 접근은 장애가 터지기 전에 이상 징후를 탐지해서, 이상 노드를 스페어로 미리 교체하고 학습을 멈추지 않고 이어가는 것입니다.
원리는 단순합니다.
분산 학습에서 모든 노드는 동일한 작업을 수행하므로, 정상적인 노드들은 유사한 메트릭 패턴을 보인다.
GPU 사용률이 비정상적으로 낮거나, NVLink 대역폭이 혼자만 급격히 떨어진다면 그 노드에 문제가 있을 가능성이 높습니다. 그렇다면 실제로 어떤 데이터를 어떻게 수집하고 있을까요?
모니터링 체계: 왜 4종류의 Exporter를 쓰는가
클러스터 상태를 수치로 보기 위해 Prometheus 기반 모니터링을 사용합니다. Prometheus는 각 노드에 설치된 exporter에게 30초마다 현재 상태를 물어보는데, 'GPU 온도가 몇 도인가?', '네트워크로 몇 바이트 보냈는가?' 같은 질문에 exporter가 숫자로 답하는 방식입니다.
그런데 왜 exporter를 4종류나 쓸까요? 각각 담당하는 영역이 다르기 때문입니다:
| Exporter | 만든 곳 | 역할 | 주요 메트릭 |
|---|---|---|---|
| DCGM-exporter | NVIDIA | GPU 심층 모니터링 | 온도, 사용률, NVLink, XID 에러, ECC |
| node_exporter | Prometheus | Linux 시스템 메트릭 | CPU, 메모리, 디스크, 네트워크, NFS |
| all-smi | 래블업 | 다중 하드웨어 통합 모니터링 | GPU 상태, CPU 사용률/온도, 시스템 메모리 |
| Backend.AI | 래블업 | 스케줄러/컨테이너 메트릭 | API 요청, 태스크 처리, RPC |
DCGM-exporter와 node_exporter는 각각 GPU와 시스템 메트릭을 담당하는 표준 도구입니다. 그렇다면 all-smi와 Backend.AI exporter는 왜 필요할까요?
all-smi는 NVIDIA GPU뿐 아니라 Apple Silicon, Tenstorrent, Rebellions, Furiosa NPU까지 지원하는 다중 하드웨어 통합 모니터링 도구입니다. 저희 클러스터에서 중요한 것은 DCGM-exporter와 GPU 핵심 메트릭을 이중으로 수집한다는 점인데요, 한쪽 exporter가 죽어도 다른 쪽으로 감시를 이어갈 수 있으며, 미세한 차이(예: DCGM은 SM Clock, all-smi는 Graphics Clock)를 교차 검증할 수 있습니다.
실제로 DCGM-exporter와 all-smi가 이중 수집하는 5개 영역은 다음과 같습니다:
| 영역 | DCGM-exporter | all-smi |
|---|---|---|
| GPU 사용률 | DCGM_FI_DEV_GPU_UTIL | all_smi_gpu_utilization |
| GPU 온도 | DCGM_FI_DEV_GPU_TEMP | all_smi_gpu_temperature_celsius |
| 클럭 속도 | DCGM_FI_DEV_SM_CLOCK | all_smi_gpu_frequency_mhz |
| 전력 소비 | DCGM_FI_DEV_POWER_USAGE | all_smi_gpu_power_consumption_watts |
| GPU 메모리 | DCGM_FI_DEV_FB_USED | all_smi_gpu_memory_used_bytes |
Backend.AI exporter는 스케줄러 레벨의 메트릭을 수집합니다. GPU 하드웨어 상태만으로는 보이지 않는 신호(예: 에이전트의 비동기 태스크 폭증)를 잡아내기 위해서입니다. 이 글 후반부에서 이 exporter 덕분에 장애 전조를 포착한 사례를 소개하겠습니다.
수집된 데이터는 VictoriaMetrics(Prometheus 호환 시계열 데이터베이스)에 저장됩니다.
305개의 활성 메트릭
4개의 exporter가 63개 노드에서 보고하는 메트릭의 총 수는 751개입니다. 이 중 장애 예측과 무관한 것들(ZFS 로컬 파일시스템 259개, Go/Python 런타임 세부, 분석 기간 내내 값이 변하지 않는 상수 등)을 걸러내면 최종적으로 305개의 활성 메트릭이 남습니다.
이 305개가 노드의 어떤 부분을 감시하는지 아래의 표를 통해 확인할 수 있습니다.
| 모니터링 대상 | 메트릭 수 | Exporter | 핵심 역할 |
|---|---|---|---|
| Network (TCP/IP) | 61 | node_exporter | 인터페이스별 트래픽, TCP 재전송/타임아웃 |
| NFS (VAST Data) | 54 | node_exporter | RPC 지연, I/O, transport 상태 |
| Memory | 45 | node_exporter + all-smi | 캐시, mmap, OOM, 사용률 |
| Exporter/Runtime | 40 | go, process, python, scrape | 모니터링 시스템 자체의 건강 |
| Scheduler | 26 | Backend.AI | 태스크 큐, RPC, 컨테이너 관리 |
| GPU (B200) | 18 | DCGM + all-smi | 온도, 사용률, XID, NVLink, ECC |
| Disk I/O | 18 | node_exporter | 디스크별 읽기/쓰기 지연 |
| OS/Kernel | 16 | node_exporter | PSI 자원 압박, 시간 동기화, 인터럽트 |
| InfiniBand | 15 | node_exporter | 포트별 트래픽, 에러, 링크 상태 |
| CPU | 12 | node_exporter + all-smi | 부하, 코어별 사용률, 스케줄링 |
GPU 메트릭이 18개(6%)로 적어 보이지만, DCGM이 GPU 내부 상태를 정밀하게 제공하기 때문에 적은 수로도 충분합니다. 오히려 네트워크·NFS·메모리가 전체의 52%를 차지하는데요, GPU 자체보다 GPU를 둘러싼 인프라의 상태가 더 복잡하고 다양하기 때문입니다. 장애의 전조가 어디서 나타날지 모르기 때문에, 넓게 수집하는 것이 중요합니다.
같은 숫자라도 읽는 법이 다르다
여기서 한 가지 짚고 넘어갈 점이 있습니다. 305개 메트릭이 모두 같은 방식으로 분석되는 것은 아닙니다.
Prometheus 메트릭에는 크게 counter(누적 카운터)와 gauge(현재 값)가 있습니다. counter는 자동차 주행거리계처럼 계속 올라가기만 하는 숫자라서, 값 자체보다 얼마나 증가했는지(변화량)를 봐야 합니다. 네트워크 수신 바이트(node_network_receive_bytes_total)가 대표적입니다. gauge는 속도계처럼 오르내리는 숫자라서, 지금 값 그 자체가 중요합니다. GPU 온도(DCGM_FI_DEV_GPU_TEMP)가 75라면 '지금 75도'라는 의미입니다.
그런데 실제로 분석을 하다 보니 공식 타입만으로는 부족했습니다. 같은 counter라도 네트워크 트래픽(증가 자체는 정상)과 InfiniBand 링크 다운 횟수(node_infiniband_link_downed_total, 한 번이라도 올라가면 이상)는 의미가 완전히 다릅니다. 그래서 분석용 카테고리를 따로 정의했는데, 가장 중요한 건 error_counter(28개)와 state(11개)입니다. error_counter는 값이 올라가는 것 자체가 장애 신호이고, state는 특정 값(예: XID 에러 코드가 0이 아닌 경우)이 장애 신호입니다. 이 39개가 장애의 직접적인 신호이고, 나머지 266개는 간접적인 징후를 포착하는 역할을 합니다.
여기서 '305개 메트릭'이 곧 305개의 숫자를 의미하는 것은 아닙니다. 하나의 메트릭은 노드, GPU, 마운트 포인트 같은 라벨 조합마다 별도의 시계열을 만들어냅니다. 예를 들어 GPU 온도 메트릭 하나가 63노드 × 8GPU = 504개의 시계열이 되고, NFS 오퍼레이션 메트릭은 63노드 × 2마운트 × 22오퍼레이션 = 2,772개까지 불어납니다. 이처럼 라벨 조합에 따라 시계열이 급격히 늘어나는 것을 카디널리티(cardinality)라고 하는데, 카디널리티가 높은 메트릭은 쿼리 과정에서 메모리 부족이 나기도 했습니다.
같은 역할끼리 비교하기
305개 메트릭에서 이상을 탐지하려면 '이 노드의 값이 비정상인가?'를 판단해야 합니다. 분산 학습에서 모든 노드는 동일한 작업을 수행하므로, 같은 메트릭이면 노드 간에 유사해야 하고 한 노드만 튀면 이상 징후입니다.
그런데 하나의 메트릭 안에서도 라벨에 따라 완전히 다른 대상이 섞여 있습니다. 예를 들어 node_network_receive_bytes_total 하나에는 그림 1의 세 가지 NIC(ib0~ib7, direct0, net0)뿐 아니라 컨테이너가 만든 가상 인터페이스까지 포함해 146개 디바이스가 섞여 있습니다. 스토리지 연결인 direct0은 하루 1.5TB, 관리용 net0은 하루 5GB로 300배 차이가 나는데, 이걸 같은 기준으로 비교할 수는 없습니다. 그래서 메트릭마다 어떤 라벨 단위로 비교해야 하는지를 정의했습니다.
| 비교 단위 | 메트릭 수 | 비교 풀 크기 | 예시 |
|---|---|---|---|
| node | 178 | ~60 노드 | 시스템 메모리, TCP, load |
| nfs_export | 45 | ~60 × 2 마운트 | NFS I/O, RPC, 오퍼레이션 지연 |
| gpu | 18 | ~60 × 8 = ~480 GPU | GPU 온도, 사용률, NVLink |
| disk | 16 | ~60 × 2 디스크 | 디스크 I/O |
| ib_device | 15 | ~60 × 8 = ~480 포트 | InfiniBand 트래픽, 에러 |
| network_device | 13 | 인터페이스 유형별 × ~60 노드 | direct0끼리, net0끼리 비교 |
| cpu_core 등 | 20 | 코어별, 센서별 | CPU 사용률, 파일시스템 |
이렇게 하면 'gpu065의 GPU 3번 온도가 다른 479개 GPU보다 높은가?', 'gpu071의 ib0 포트 대역폭이 다른 노드의 ib0보다 낮은가?'를 정확하게 판단할 수 있습니다.
장애 원인이 있는 곳과 징후가 드러나는 곳은 다르다
어떤 장애에 어떤 메트릭이 유효한지는 아직 완전히 밝혀지지 않았습니다. 하지만 Minder의 연구[3]를 통해 단서를 잡아볼 수 있습니다.
| 장애 유형 | CPU | GPU | Memory | Throughput | PFC | Disk |
|---|---|---|---|---|---|---|
| ECC Error | 80.0% | 65.7% | 57.1% | 45.7% | 8.6% | 11.4% |
| NVLink Error | 83.3% | 50.0% | 66.7% | 50.0% | 16.7% | 0.0% |
| GPU Card Drop | 75.0% | 70.0% | 55.0% | 50.0% | 5.0% | 20.0% |
ECC Error는 GPU 메모리 결함인데, 정작 CPU 메트릭(80%)이 GPU 메트릭(65.7%)보다 감지율이 높다는 점이 눈에 띕니다. NVLink Error도 마찬가지로 CPU(83.3%)가 GPU(50.0%)를 앞섭니다. 장애 원인이 있는 곳과 징후가 먼저 드러나는 곳이 다를 수 있다는 뜻입니다. 또한 어떤 단일 메트릭도 특정 장애를 100% 감지하지 못합니다. 여러 메트릭 중 하나 이상에서 이상이 나타나지만, 어느 메트릭에서 나타날지는 케이스마다 다릅니다.
왜 그럴까요? 노드 내부에서 GPU, 메모리, 디스크, 네트워크는 긴밀하게 연결되어 있어서 연쇄 반응이 일어나기 때문입니다. 그래서 특정 장애에 특정 메트릭을 매핑하기보다, 구성 요소별로 가능한 한 넓게 수집하는 것이 저희의 접근입니다.
구체적으로 어떤 메트릭을 보는지, 저희 클러스터에서 자주 발생한 순서대로 정리해 보겠습니다.
NVLink 장애: 노드 내 GPU 간 통신 두절. 저희 클러스터에서 가장 빈번했던 유형입니다(23.5%). 같은 노드 8개 GPU의 NVLink 대역폭(DCGM_FI_DEV_NVLINK_BANDWIDTH_TOTAL)을 비교해서 탐지합니다. 8개 GPU 대역폭이 모두 떨어지면 NVSwitch 자체 문제, 한 GPU만 떨어지면 해당 GPU의 NVLink 문제로 구분할 수 있습니다.
ECC Error: GPU 메모리 결함. Minder 연구에서는 38.9%로 가장 빈번했지만, 저희 클러스터에서는 11.8%였습니다. GPU의 HBM(고대역폭 메모리)은 수십억 개의 메모리 셀로 이루어져 있어서, 높은 온도에 장시간 노출되면 점진적으로 열화됩니다. ECC(Error Correcting Code)가 처음엔 오류를 자동 교정하지만, 교정 가능한 오류가 쌓이면 결국 교정 불가능한 오류로 이어집니다. HBM 온도(DCGM_FI_DEV_MEMORY_TEMP)와 행 재매핑 횟수(DCGM_FI_DEV_CORRECTABLE_REMAPPED_ROWS)를 주시하는 이유입니다. 다만 앞서 Minder[3] 데이터에서 봤듯이, ECC 에러가 GPU 메트릭보다 CPU 메트릭에서 먼저 감지되는 경우가 많아서 원인 분석이 필요합니다.
NIC 장애: 노드 간 통신 두절. InfiniBand 링크 다운 횟수(node_infiniband_link_downed_total)가 핵심 지표입니다. 앞서 설명한 error_counter의 대표적인 예로, 한 번이라도 올라가면 이상 신호입니다. 링크 하나가 다운되면 gradient 동기화(학습 과정에서 각 노드가 계산한 결과를 맞춰보는 단계)가 불가능해져서 전체 학습이 멈춥니다.
파일시스템 문제: 학습 데이터 공급 중단. 학습 데이터는 NFS(VAST Data) → 시스템 메모리(캐시) → GPU 메모리 순서로 흘러가는데, NFS에 문제가 생기면 GPU가 데이터를 기다리며 놀게 됩니다. NFS 요청은 큐 대기 → 전송·처리 → 응답의 3단계를 거치는데, 어느 단계에서 지연이 생기느냐에 따라 원인이 다릅니다. 큐 대기 시간이 늘면 클라이언트 과부하, 전송 시간이 늘면 네트워크 문제, 응답 시간이 늘면 스토리지 자체 부하를 의심할 수 있습니다.
그리고 이런 개별 장애만큼 까다로운 게 연쇄 반응입니다. GPU 연산이 느려지면 데이터 전처리가 밀리고, I/O가 쌓이면서, 시스템 부하가 올라갑니다. 반대 방향도 마찬가지로, NFS 지연이 생기면 GPU가 데이터를 기다리며 유휴 상태에 빠집니다. 이런 연쇄 반응을 잡기 위해 TCP 재전송(node_netstat_Tcp_RetransSegs), 디스크 I/O 포화도, 시스템 부하(node_load1), 시간 동기화 오차 같은 간접 지표도 함께 수집하고 있습니다.
실제 장애에서 발견한 전조
장애 직전 급증하는 Backend.AI 비동기 태스크
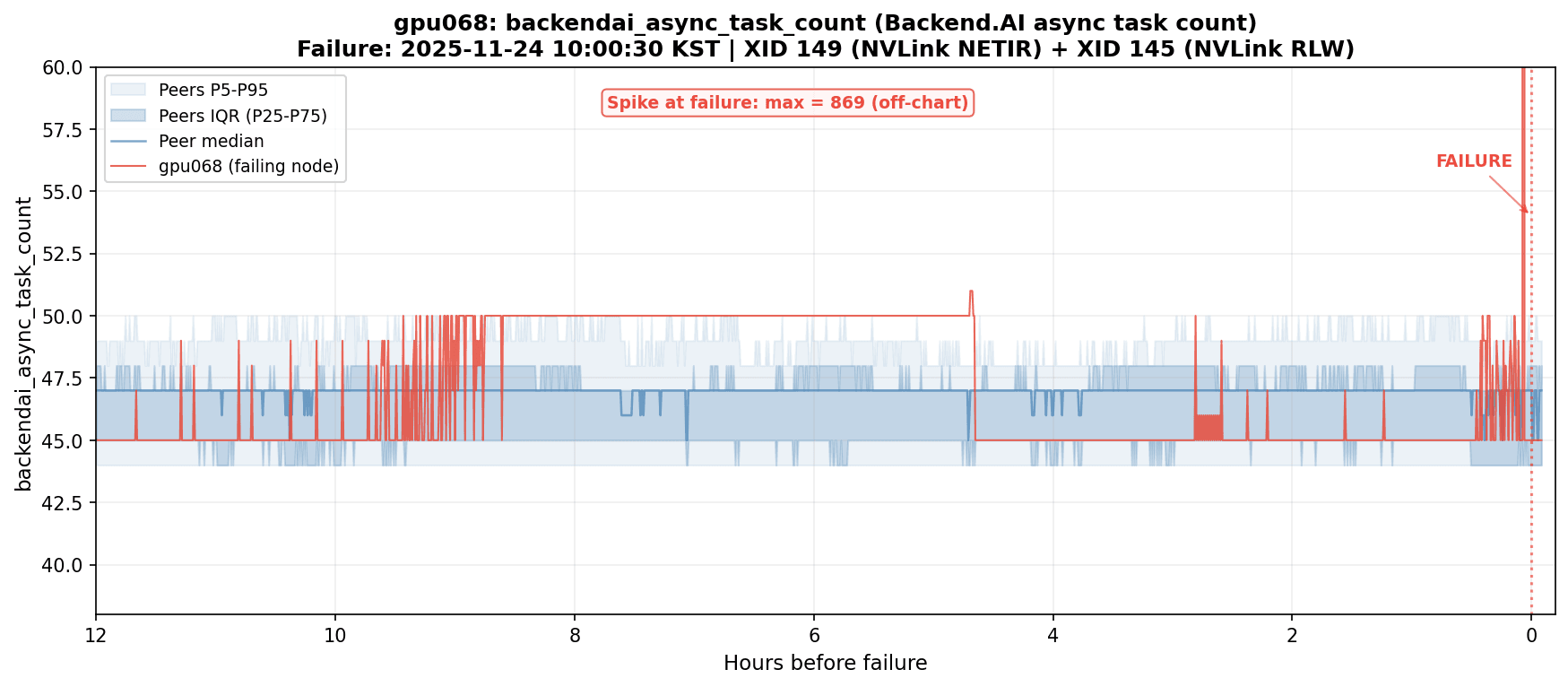
그림 3. gpu068 NVLink 장애 직전 backendai_async_task_count 급증. 정상 범위(44~50)에서 869까지 약 18배 폭증했다.
gpu068에서 NVLink 장애(XID 149 + XID 145)가 발생하기 직전, backendai_async_task_count(Backend.AI 에이전트가 처리 중인 비동기 태스크 수)가 급격히 치솟았습니다. 정상 상태에서 이 값은 60개 노드 모두 44~50 수준으로 안정적인데, 장애 시점에 gpu068만 869까지 폭증했습니다. 정상의 약 18배입니다.
NVLink에 이상이 생기면서 에이전트가 에러 처리, 재시도, 상태 보고 등으로 갑자기 바빠진 것으로 보입니다. GPU 하드웨어 장애가 스케줄러 레벨에서도 보이는 신호를 만든 것입니다.
이 사례가 중요한 이유는, GPU 장애의 신호가 GPU 메트릭이 아닌 곳에서 나타났기 때문입니다. backendai_async_task_count는 DCGM이 아닌 Backend.AI 스케줄러 영역의 메트릭인데, 305개 메트릭을 GPU부터 네트워크, 스토리지, 스케줄러까지 폭넓게 수집해둔 덕분에 이런 신호를 잡을 수 있었습니다. 앞서 4종류의 exporter를 쓰는 이유, 그리고 Minder[3]가 보여준 교차 감지율의 의미가 여기서 구체적으로 확인되었습니다.
정리
500+개 GPU 학습 클러스터를 운영하면서, 저희는 선제적 이상 신호 탐지를 위한 모니터링 체계를 구축해 왔습니다.
이 글에서 다룬 내용을 요약해서 정리해 보겠습니다.
- 클러스터 구조: 63대 노드, 504개 B200 GPU, NVLink + InfiniBand 이중 네트워크, HSDP 분산 학습
- 장애의 현실: 약 2개월간 13개 노드에서 17건의 하드웨어 장애 발생. 분산 학습에서는 한 GPU의 장애가 전체 학습을 멈춤
- 모니터링 체계: 4종류의 exporter로 305개 메트릭을 30초마다 수집. 4개 exporter를 통한 다층적 모니터링 체계 구축
- 전조 탐지 사례: GPU 장애 직전, GPU 메트릭이 아닌 Backend.AI 스케줄러 메트릭에서 이상 신호 포착
장애 원인이 있는 곳과 징후가 먼저 드러나는 곳이 다를 수 있다는 것, 그래서 GPU만 보는 게 아니라 인프라 전체를 넓게 감시해야 한다는 것이 저희가 현장에서 얻은 가장 큰 교훈입니다. 현재 이 데이터를 기반으로 이상 탐지 모델을 설계하고 검증하는 작업을 진행하고 있습니다.
참고 문헌
[1] Reliability Lessons Learned from Scaling Large-scale ML Research Clusters (Meta, HPCA 2025)
[2] Solar Open Technical Report (Upstage, 2026)
[3] Minder: Faulty Machine Detection for Large-scale Distributed Model Training (ByteDance, NSDI 2024)