엔지니어링

GPU를 구매할 때 한 가지 벤더만 고르면 간단하겠지만, 현실은 그렇게 간단하지 않은 경우가 많습니다. 예를 들어 기존에 도입한 NVIDIA H100을 아직 쓰고 있는데 올해 예산으로 AMD MI350X를 추가 도입하게 될 수도 있고, 특정 추론 워크로드의 비용 효율을 위해 다른 벤더의 가속기를 들이거나, Prefill-decode 단계의 분리 운영을 위해 사양이 다른 가속기를 섞어서 운영하게 될 수도 있는 것이죠.
실제로 데이터센터 AI 가속기 시장은 빠르게 다변화되고 있습니다. AMD는 MI300X 계열로 대형 고객사 채택을 넓혀 왔고, OpenAI와의 전략적 파트너십으로 차세대 MI450 배포까지 예고한 상태입니다.1 ROCm 7.x가 PyTorch 네이티브 지원과 성능을 끌어올리며 소프트웨어 생태계도 함께 성숙해지고 있습니다.2 Intel Gaudi가 가격 대비 성능으로 데이터센터를 파고드는 한편, 국내에서도 리벨리온 ATOM이 KT Cloud 등에 상용 배치되고 퓨리오사AI가 RNGD 양산에 들어가면서 국산 NPU가 현실적인 선택지가 됐습니다.3
시장에 다양한 가속기가 존재하는 이유는 각 가속기가 잘 하는 영역이 각각 다르기 때문입니다. NVIDIA H100/B200은 NVLink/NVSwitch 기반 대규모 분산 학습에 여전히 독보적입니다. AMD MI300X는 192GB HBM3 용량을 앞세워 대형 모델 추론에서 강점을 보이며, Intel Gaudi는 비용 효율적인 학습/추론 워크로드를 노리고 있습니다. 국산 NPU들은 추론 특화 아키텍처로 특정 모델·서비스에 최적화된 성능을 제공합니다. 그런데 이기종 가속기를 기존 클러스터에 함께 배치하려고 하면, 하드웨어 구매보다 운영이 더 까다로워지는 문제가 발생합니다. 이 글에서는 이기종 GPU 혼합 환경을 운영할 때 마주하는 문제들과, 그러한 문제들을 해결하기 위한 리소스 그룹 구성 전략에 대해 살펴보겠습니다.
벤더별 소프트웨어 스택의 격차
NVIDIA H100과 AMD MI300X는 둘 다 데이터센터용 AI 가속기이지만, 완전히 다른 소프트웨어 스택을 가지고 있습니다. NVIDIA는 CUDA 위에 cuDNN, NCCL, TensorRT 같은 라이브러리 체계를 쓰고, AMD는 ROCm 위에 MIOpen, RCCL, 그리고 HIP(Heterogeneous-compute Interface for Portability)으로 구성된 스택을 사용합니다. Intel Gaudi는 또 별도의 Intel Gaudi 소프트웨어 스위트(구 SynapseAI)라는 스택을 갖고 있고, 국산 NPU들도 각자의 SDK와 컴파일러 체계를 사용합니다. PyTorch 같은 프레임워크가 여러 백엔드를 지원하긴 하지만, 밑단의 런타임과 드라이버가 다르기 때문에 하나의 학습 작업이 서로 다른 벤더의 가속기에 동시에 걸치는 분산 학습은 현재로서는 불가능합니다.
분산 학습에서 쓰는 집합 통신 라이브러리도 마찬가지입니다. NVIDIA의 NCCL과 AMD의 RCCL은 API 이름이 거의 같게 설계되어 있지만, 그 아래의 통신 토폴로지는 서로 다르게 구성되어있습니다. NVLink/NVSwitch 기반 최적화와 AMD GPU 간 Infinity Fabric 링크 통신은 대역폭 구조가 다르기 때문에 한쪽에 맞춘 튜닝이 다른 쪽에서 그대로 성능을 내주지 않죠.
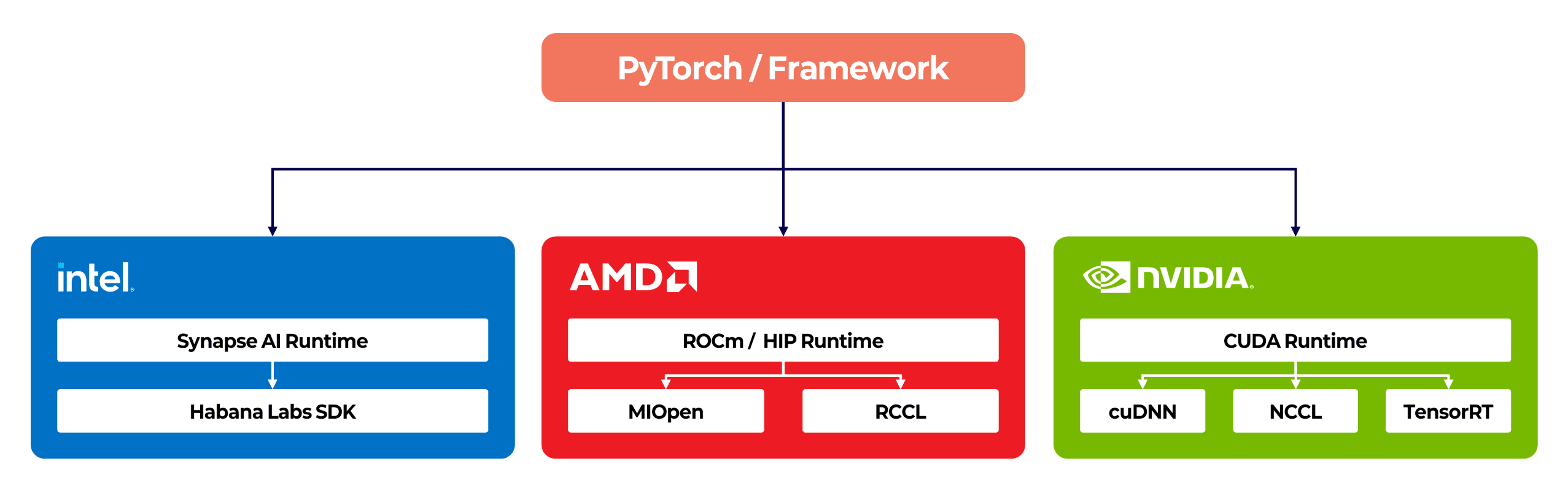
그러나, 벤더가 다른 가속기를 같은 클러스터에 함께 두는 구성이 전혀 무의미한 것은 아닙니다. 분산 학습 하나에 두 벤더 GPU를 동시에 묶는 건 안 되지만, 워크로드 단위로 적합한 가속기에 배치하는 건 충분히 가능하고 실용적입니다. 대규모 LLM 학습은 NVIDIA H100 NVLink 클러스터에서 돌리고, 추론 서빙이나 파인튜닝 같은 작업은 HBM 용량이 192GB로 넉넉한 AMD MI300X에 올리거나, 특정 모델의 추론을 국산 NPU에서 처리하는 식의 역할 분담이 대표적인 예시가 될 수 있습니다.
성능이 다른 GPU를 하나의 자원 풀에 묶으면 생기는 일
이기종 GPU 혼합 운영에서 가장 자주 발생하는 실수는 성능이 크게 다른 가속기들을 하나의 자원 풀에 넣는 식의 시나리오를 생각하는 것입니다. 멀티노드 분산 학습에서는 성능이 다른 GPU가 섞이면, 가장 느린 GPU가 전체 학습 속도를 결정합니다. 분산 학습의 각 스텝에서 모든 GPU가 그래디언트를 동기화해야 하는데, 빠른 GPU가 연산을 끝내고 느린 GPU를 기다리는 시간이 매 스텝마다 누적되기 때문입니다. 클러스터 전체 활용률은 가장 느린 가속기의 속도로 수렴하고, 비싼 가속기일수록 대기 시간 동안 잃는 기회비용이 커집니다.

다른 제조사에서 만든 GPU 뿐만 아니라 같은 제조사의 GPU일지라도 세대 차이가 벌어지면 비슷한 현상이 발생합니다. H100(80GB, NVLink 900GB/s)과 V100(32GB, NVLink 300GB/s)을 하나의 그룹에 두면, H100이 V100의 속도에 맞춰 대기하게 됩니다. 비싼 H100의 연산 능력이 낭비되는 셈이죠.
리소스 그룹으로 나누는 이기종 구성 전략
이기종 클러스터를 운영하는 가장 보편적인 접근은 성능 특성이 다른 가속기를 별도의 리소스 그룹으로 분리하고, 각 그룹에 적합한 워크로드를 배치하는 방법입니다. Kubernetes의 node label과 taint/toleration, Slurm의 partition, Ray의 placement group이 모두 같은 패턴을 다른 계층에서 구현한 것입니다. Backend.AI의 리소스 그룹도 같은 계열의 접근이지만, AI 워크로드에 맞게 다양한 가속기 벤더와 추론·학습 혼합 시나리오를 한 플랫폼에서 다루는 데 초점이 맞춰져 있습니다. 클러스터를 논리적 리소스 그룹으로 분할하고 각 그룹에 독립적인 스케줄러 정책을 적용하면, 물리적으로는 같은 데이터센터 같은 랙에 NVIDIA 노드와 AMD 노드, Intel Gaudi 노드가 나란히 들어가 있더라도 소프트웨어 상에서는 완전히 분리된 자원 풀로 관리됩니다.
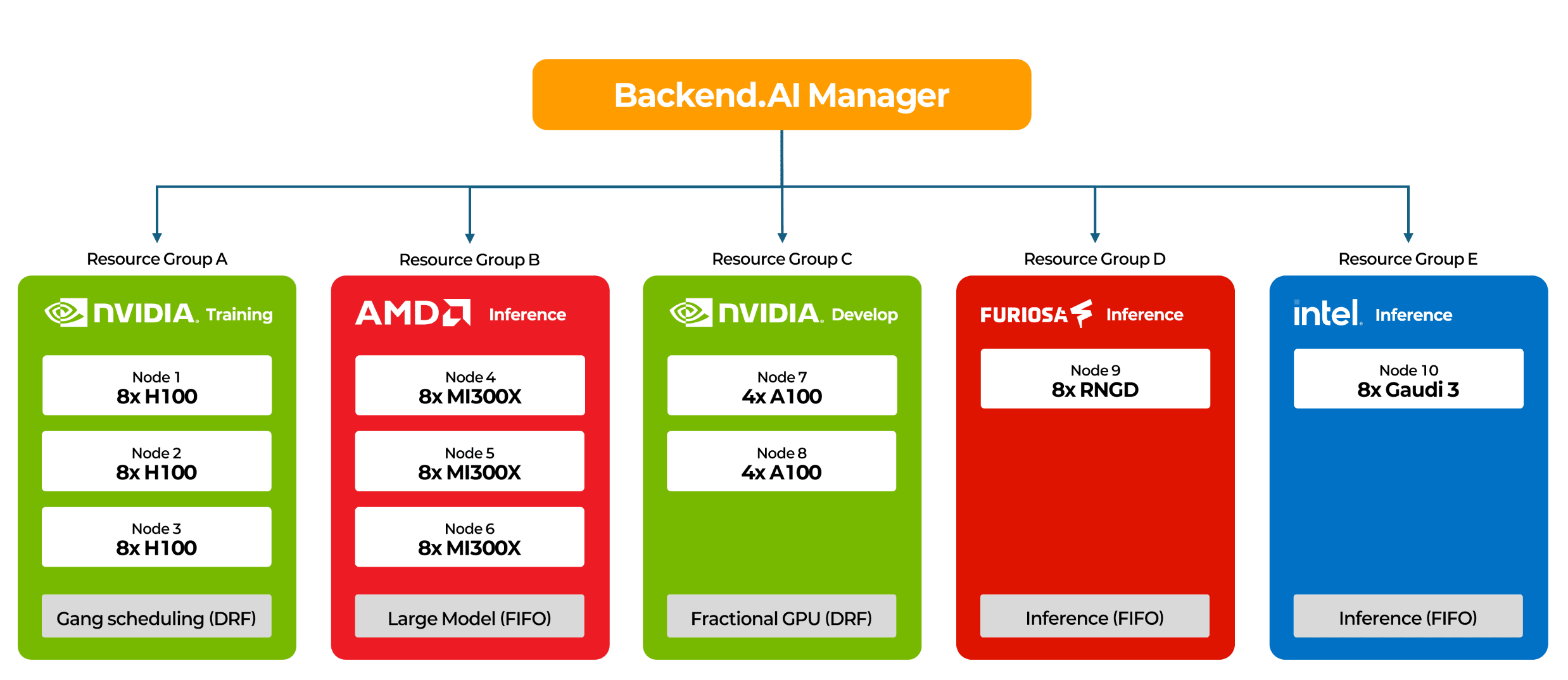
이러한 구조에서는 워크로드가 의도치 않은 가속기에 배치될 일이 없어집니다. CUDA 기반 학습 작업은 NVIDIA 리소스 그룹에만 제출되고, ROCm 기반 추론 서빙은 AMD 리소스 그룹에서만 돌아가며, NPU 추론 워크로드는 NPU 전용 그룹에서 처리되니 런타임 불일치로 작업이 실패하는 상황 자체가 구조적으로 차단되는 것입니다. 각 그룹에는 해당 가속기의 강점에 맞는 스케줄링 정책도 따로 적용됩니다. 대규모 학습용 H100 그룹에는 DRF(Dominant Resource Fairness)와 Gang Scheduling을 걸어 멀티노드 작업이 부분 할당으로 교착 상태에 빠지지 않도록 하고, 추론용 MI300X 그룹에는 FIFO를 걸고 192GB HBM3 용량을 살려 70B급 대형 모델을 단일 카드에 단독 배치할 수도 있습니다. 개발·실험용 NVIDIA 그룹에는 Backend.AI의 Container-level GPU Virtualization을 활성화해 한 장의 GPU를 여러 작업이 나눠 쓰게 하면, 같은 하드웨어에서 더 많은 동시 작업을 수용할 수도 있죠.
관리자 입장에서는 이렇게 나뉜 가속기 그룹 위에서 여러 팀의 사용량을 추적하는 기능이 필수적입니다. 따라서, Backend.AI는 그룹 단위 자원 어카운팅 기능을 함께 제공하죠. 외부 결제 서비스와 연동하면 어떤 팀이 NVIDIA GPU를 얼마나 썼는지, AMD나 Intel Gaudi를 얼마나 썼는지 그룹별로 집계할 수 있고, 그룹별로 다른 할당 정책(quota)을 걸 수도 있습니다.
Sokovan의 HAL과 2단계 스케줄링
그룹·정책 구조를 실제로 구현하는 엔진이 Backend.AI의 Sokovan 오케스트레이터입니다. Sokovan은 NVIDIA, AMD, Intel, Tenstorrent, 리벨리온, 퓨리오사AI 등 12개 개발사의 각기 다른 가속기를 하드웨어 추상화 계층(Hardware Abstraction Layer, HAL)으로 통합 관리합니다. 각 물리 가속기는 cuda.device, cuda.shares, rocm.device, atom.device처럼 <장치>.<할당 단위> 형식의 자원 슬롯(Resource Slot)으로 추상화되고, 사용자는 특정 하드웨어를 지정하거나 '고성능 GPU 아무거나'로 요청할 수 있습니다.
Sokovan의 2단계 스케줄링은 먼저 글로벌 스케줄러가 전체 클러스터에서 작업의 요구사항(가속기 타입, 수량, 메모리 등)을 만족하는 후보 노드를 필터링하고, 리소스 가용성과 정책 기반 우선순위를 고려해 적절한 노드를 선택하는 방식으로 동작합니다. 이후 로컬 스케줄러는 선택된 노드 안에서 구체적인 GPU 슬롯을 배정하고, Fractional GPU가 활성화된 그룹이라면 메모리 할당량에 따라 GPU를 분할해서 여러 작업에 나눠줍니다. 각 그룹은 독립적인 스케줄러 설정(FIFO, DRF, 커스텀), 에이전트 선택 알고리즘(bin-packing, balanced), 큐잉 정책을 가질 수 있습니다. Sokovan이 어떻게 동작하는지 더욱 자세한 내용은 다음 글을 참고하세요.
모니터링 도구가 다변화되는 문제는 래블업이 오픈소스로 내놓은 all-smi를 통해 풀어나갈 수 있습니다. all-smi는 NVIDIA GPU, AMD GPU, Intel Gaudi 등 서로 다른 가속기의 활용률, 메모리 사용량, 온도, 전력 소비를 하나의 인터페이스에서 통합 제공하는 유틸리티입니다. Prometheus 호환 메트릭 엔드포인트를 통해 기존 모니터링 파이프라인에 연결할 수 있죠. all-smi에 대한 자세한 내용은 다음 페이지를 참고하세요.
이기종 구성을 시작할 때 고려할 점
이기종 가속기 구성을 위해서는 컨테이너 이미지를 가속기별로 분리해야 합니다. CUDA 런타임이 포함된 이미지와 ROCm 런타임이 포함된 이미지, 각 NPU SDK가 포함된 이미지를 따로 빌드하고 관리하는 식입니다. Backend.AI는 NGC 카탈로그 이미지뿐 아니라 사용자 정의 이미지도 지원하므로, 사용자가 각 가속기에 맞는 이미지를 등록해두고 각각의 리소스 그룹과 연결할 수 있습니다.
네트워크 토폴로지도 함께 고려해야 합니다. 같은 리소스 그룹 안에서 멀티노드 학습을 돌릴 가능성이 있다면, 그룹의 노드들을 물리적으로도 가까운 네트워크에 배치하는 편이 좋습니다. NVIDIA 노드 간에는 InfiniBand, AMD 노드 간에는 RoCE(RDMA over Converged Ethernet)를 주로 쓰는데, 이 인터커넥트가 그룹 단위로 일관되어야 분산 학습 성능이 안정적으로 나오기 때문입니다.
추론이나 개발 환경에서는 GPU 전체가 필요 없는 경우가 많아 Fractional GPU를 사용하는 것이 유효합니다. Backend.AI의 Container-level GPU Virtualization은 컨테이너 단에서 GPU 메모리와 SM(Streaming Multiprocessor)을 분할해 한 장의 GPU를 여러 작업이 나눠 쓰게 합니다. MIG 같은 하드웨어 분할 방식과 달리 추가 하드웨어 기능에 의존하지 않아 분할 크기와 조합을 유연하게 조정할 수 있습니다. 현재 Backend.AI의 분할가상화 기능은 NVIDIA GPU에서만 동작하지만, 곧 인텔과 AMD GPU에서도 만나볼 수 있도록 기술개발, 검증을 진행 중에 있습니다.
마지막으로 가속기 로드맵을 감안해 유연하게 설계해 둘 필요가 있습니다. 예를 들어, 지금은 NVIDIA와 AMD 두 종류만 운영하더라도 내년에 다양한 제반사정에 의해 Intel Gaudi나 국산 NPU가 추가될 수도 있습니다. 처음부터 가속기 타입에 종속되지 않는 리소스 그룹 기반 아키텍처로 설계해두면, 새 가속기가 들어오더라도 그룹을 하나 더 만들어 연결하는 것만으로 확장에 안정적으로 대응할 수 있습니다.
마치며: 이기종 구성의 설계 기준
AI 가속기 시장이 AMD Instinct, Intel Gaudi, 그리고 퓨리오사 RNGD나 리벨리온 ATOM 같은 국산 NPU들까지 다변화되면서, 워크로드 특성에 맞춰 여러 가속기를 조합하는 멀티 GPU 운영이 실질적인 전략으로 자리잡고 있습니다. 결국 핵심은 소프트웨어 스택이 다른 가속기들을 어떻게 논리적으로 구분하고 각각의 강점에 맞는 워크로드를 배치하느냐에 있습니다. 리소스 그룹을 가속기 타입과 용도에 맞게 분리하고, 그룹별로 적합한 스케줄링 정책을 적용하면, 이기종 환경에서도 각 가속기의 성능을 온전히 활용할 수 있습니다.
Backend.AI는 이러한 이기종 구성을 소프트웨어 단에서 처리할 수 있도록 설계된 플랫폼입니다. 전 세계 누적 120여 개 사이트에서 엔비디아를 비롯한 다수 개발사의 다양한 AI 가속기가 Backend.AI 위에서 이기종 구성으로 운영되어 왔고, 클라우드 운영사의 GPU 구독 서비스(GPU-as-a-Service), 금융권의 폐쇄망 LLM, 공공 연구기관의 대규모 AI 인프라 등 서로 다른 맥락에서의 운영 경험을 쌓아 왔습니다.
이기종 GPU 운영을 더 효율적으로 하고 싶다면, 래블업 기술 상담을 통해 전문가와 상담해 보세요. Backend.AI가 현재 보유한 가속기 구성과 워크로드 특성을 고려한 최선의 해답을 제공해 드립니다.
Footnotes
-
AMD, AMD and OpenAI Announce Strategic Partnership (2025). ↩
-
AMD, ROCm 7.0: Supercharging AI and HPC Infrastructure (2025). ROCm 6 대비 학습 성능 3배, 추론 성능 3.5배 향상 벤치마크 (동일 하드웨어 기준 소프트웨어 개선치). ↩
-
FuriosaAI, RNGD enters mass production (2026). Rebellions ATOM의 KT Cloud 상용 배치는 Rebellions 공식 뉴스룸 참조. ↩



