엔지니어링
Jun 22, 2026
엔지니어링
Backend.AI on DGX Spark: 오픈소스 버전 설치하기 튜토리얼

조규진
AI 플랫폼 아키텍트

강시온
소프트웨어 엔지니어

김유빈
소프트웨어 엔지니어

허진호
테크니컬 라이터
Jun 22, 2026
엔지니어링
Backend.AI on DGX Spark: 오픈소스 버전 설치하기 튜토리얼
조규진
AI 플랫폼 아키텍트
강시온
소프트웨어 엔지니어
김유빈
소프트웨어 엔지니어
허진호
테크니컬 라이터
Backend.AI에서 기본으로 제공하는 TUI(Terminal User Interface) Installer를 통해 Backend.AI를 1대의 DGX Spark (노드/서버)에 설치하기 위한 가이드입니다. 해당 가이드에서는 Gemma 4 12B 모델을 사용합니다. 해당 가이드는 Backend.AI 26.4.9 버전을 기준으로 하며, 향후 소프트웨어 업데이트로 인터페이스가 일부 변경될 수 있습니다.
Backend.AI에 대하여
Backend.AI는 여러 사용자가 NVIDIA GPU 같은 AI 가속기를 포함한 컴퓨팅 자원을 안전하게 공유하며 AI/ML 워크로드를 실행할 수 있게 하는 오픈소스 클러스터 플랫폼으로, 단일 서버부터 수천 노드 멀티사이트 클러스터까지 같은 코드베이스로 운영해 인프라 복잡성을 간소화합니다.
사용자와 운영자의 역할
사용자는 브라우저에서 Jupyter Lab, VS Code(Web), SSH 터미널을 열어 GPU 위에서 코드를 작성하고 실험하며, 자원 요청을 큐에 넣으면 스케줄러가 GPU가 가능 시 자동으로 컨테이너를 띄워 배치 학습을 수행합니다. 학습한 모델을 HTTP 엔드포인트로 노출하고 자동 스케일링을 적용해 모델 서빙(인퍼런스)을 지원하고, 프로젝트나 그룹 단위로 분리된 VFolder(가상 폴더)에 데이터셋, 모델, 결과물을 보관하여 데이터를 공유합니다.
운영자는 도메인, 프로젝트, 사용자, 키페어, 자원 정책 등을 정의해 누가 어떤 자원을 얼마나 사용할 수 있는지 관리하고, 프라이빗 컨테이너 레지스트리를 연동해 허용되는 컨테이너 이미지를 통제하며, GPU/CPU 자원의 분배, 격리, 스케줄링 정책을 결정합니다. 사용량 로그, 감사 로그, 접근 로그를 추적해 모니터링합니다.
Backend.AI 마이크로서비스 아키텍처
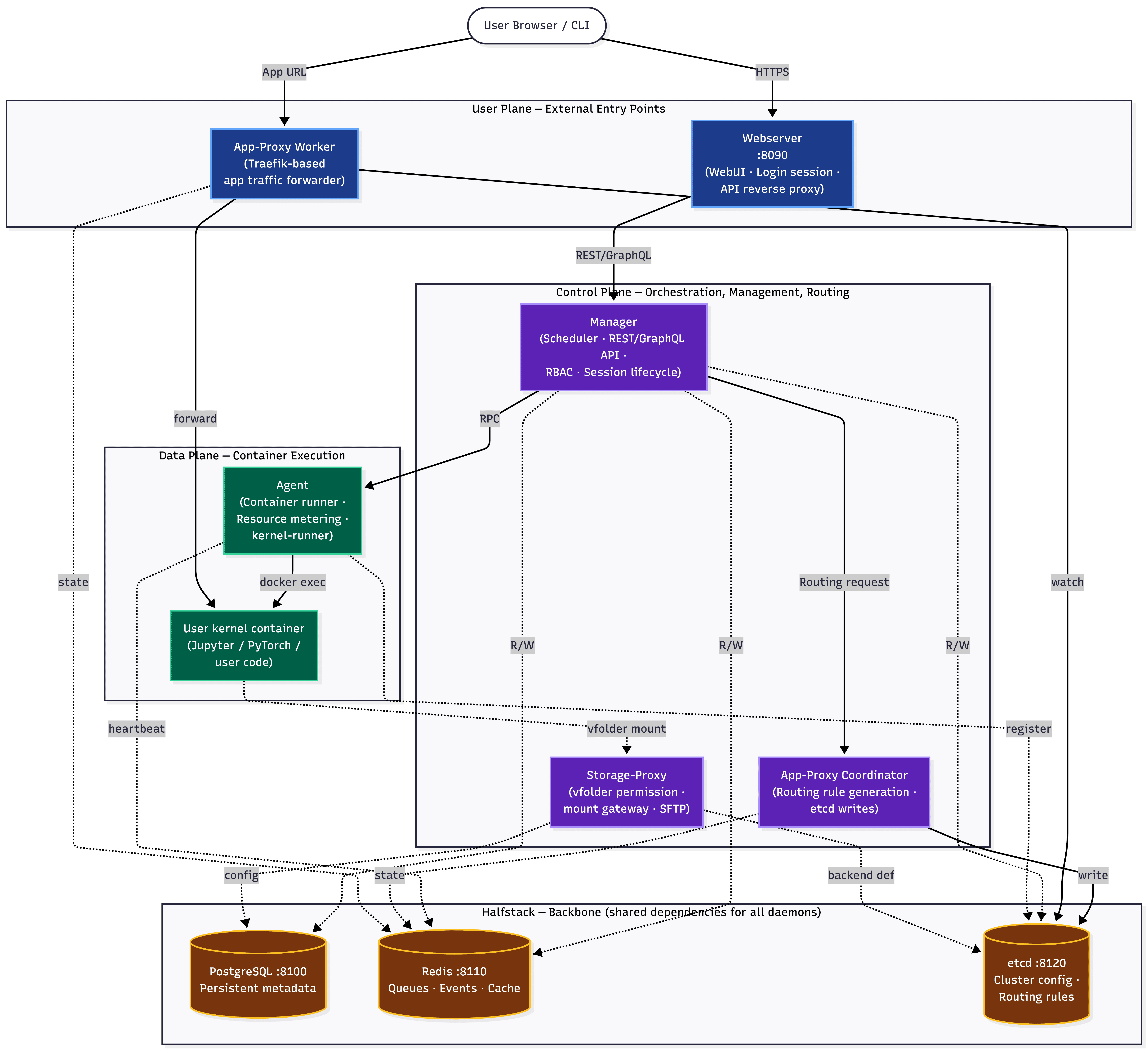
사용자 요청은 진입점에서 받아 Control Plane으로 전달됩니다. Control Plane은 요청을 처리하고 Data Plane의 컨테이너 실행을 조율합니다. 모든 데몬은 Halfstack을 공용 저장소로 사용하며, 상태와 설정을 여기에서 공유합니다.
User Plane: 사용자와 시스템의 접점
- Webserver(:8090): 관리 및 제어 트래픽의 진입점입니다. WebUI의 정적 리소스를 제공하고 로그인 세션을 관리합니다. 또한 API 리버스 프록시로 동작하며, 클라이언트 요청을 Manager의 REST 또는 GraphQL API로 전달합니다.
- App Proxy Worker: 사용자 컨테이너에서 실행되는 애플리케이션 트래픽을 처리합니다. 예를 들어 Jupyter와 같은 애플리케이션에 대한 요청을 받아, 해당 사용자 커널 컨테이너로 전달합니다.
Control Plane: 오케스트레이션과 제어
- Manager: 시스템의 중심 제어 데몬입니다. 컴퓨트 세션 스케줄링과 API 엔드포인트를 제공하며, RBAC 기반 권한 제어를 수행합니다. 또한 세션의 생성부터 종료까지 전체 라이프사이클을 관리합니다. Webserver로부터 전달된 요청을 처리하고, PostgreSQL, Redis, etcd에 읽기 및 쓰기 작업을 수행해 메타데이터와 상태를 유지합니다. 세션 생성이 필요하면 RPC로 Agent에 작업을 지시합니다. 애플리케이션을 외부에 노출해야 하는 경우에는 App Proxy Coordinator에 라우팅 생성을 요청합니다.
- Storage-Proxy: 가상폴더(VFolder)에 대한 게이트웨이 역할을 합니다. 폴더와 파일의 생성 및 삭제, 파일 업로드와 다운로드 등 스토리지 관련 요청을 처리합니다. Manager와 WebUI 모두 이 컴포넌트를 통해 스토리지에 접근합니다.
- App Proxy Coordinator: 애플리케이션 라우팅 규칙을 생성하는 데몬입니다. Manager로부터 요청을 받아 backend 정의와 라우팅 규칙을 생성합니다. 생성된 규칙은 App Proxy Worker로 전달됩니다. 이 구조를 통해 라우팅 규칙의 생성과 실제 트래픽 처리가 분리됩니다.
Data Plane: 실행 계층
- Agent: 각 컴퓨트 노드에서 실행되며 컨테이너 실행을 담당합니다. 컨테이너 실행, 리소스 사용량 측정, kernel-runner 기능을 수행합니다. Manager의 RPC 요청을 받아 docker exec로 사용자 커널 컨테이너를 실행하거나 제어합니다. 자신의 상태와 가용성은 heartbeat로 Redis에 보고하고, 노드 등록 정보는 etcd에 기록합니다.
- User kernel container: 사용자 코드가 실제로 실행되는 환경입니다. Jupyter나 PyTorch와 같은 런타임이 이 컨테이너 안에서 동작합니다. Agent가 컨테이너를 생성하고 관리합니다. 필요한 스토리지는 Manager의 지시에 따라 마운트됩니다. 외부 애플리케이션 트래픽은 App Proxy Worker를 통해 이 컨테이너로 전달됩니다.
Halfstack: 모든 데몬이 의존하는 공용 인프라 계층
- PostgreSQL(:8100): 영속적인 메타데이터를 저장합니다. 사용자, 세션, 가상폴더(VFolder)와 같은 정형 데이터가 이곳에 보관됩니다.
- Redis(:8110): 비동기 메시지 처리와 캐시를 담당합니다. 데몬 간 이벤트 전달과 Agent heartbeat 같은 휘발성 상태 정보를 저장합니다.
- etcd(:8120): 클러스터 구성 정보를 저장하는 분산 키-값 저장소입니다. 노드 등록 정보와 일부 라우팅 관련 데이터가 여기에 기록됩니다.
컴퓨트 세션 생성 과정
사용자가 HTTPS로 Webserver에 접속하면 요청이 Manager로 전달됩니다. Manager는 스케줄링을 수행한 뒤 RPC로 Agent에 세션 생성을 요청합니다. Agent는 docker exec를 통해 사용자 커널 컨테이너를 실행합니다. 스토리지가 필요한 경우 Agent가 컨테이너에 마운트합니다. 애플리케이션 트래픽은 별도의 경로로 처리됩니다. Manager가 App Proxy Coordinator에 라우팅 생성을 요청하면, Coordinator가 규칙을 생성해 App Proxy Worker에 전달합니다. 이후 App Proxy Worker가 해당 규칙에 따라 사용자 요청을 커널 컨테이너로 전달합니다.
각 컴포넌트는 직접 연결되지 않고, PostgreSQL, Redis, etcd를 통해 상태를 공유합니다. 그 결과, 각 계층과 구성 요소를 독립적으로 확장할 수 있습니다.
데몬별 역할
| 데몬 | 기동 명령 |
|---|---|
| Webserver | ./backendai-webserver web start-server |
| WebUI(정적 자산) 제공, 사용자 로그인 세션 관리, 브라우저↔Manager API 사이 리버스 프록시. 외부 사용자가 가장 먼저 닿는 진입점 (:8090) | |
| Manager | ./backendai-manager mgr start-server |
| Control-plane. REST/GraphQL API, 세션 스케줄링 (Sokovan), agent/storage 등록 관리, 권한·RBAC, 컨테이너 레지스트리 연동, 도메인·프로젝트·사용자 메타데이터 관리. 모든 운영 결정의 중심 | |
| Agent | ./backendai-agent ag start-server |
| 노드의 컨테이너 실행자. Manager 가 내려준 세션을 받아 Docker 컨테이너(=kernel)를 띄우고, CPU/메모리/GPU 자원 측정, kernel-runner 통한 service 기동(jupyter/ttyd 등). GPU 노드 = agent | |
| Storage-Proxy | ./backendai-storage-proxy storage start-server |
| vfolder(사용자 데이터 볼륨)의 mount/권한/quota 게이트웨이. 컨테이너에 vfolder 를 attach 할 때 통과하는 layer. SFTP 업로드 endpoint 도 제공 | |
| App-Proxy Coordinator | ./backend.ai app-proxy coordinator start-server |
| 사용자가 컨테이너의 앱(예: Jupyter)을 띄우면 어떤 URL → 어떤 컨테이너의 어떤 포트 매핑을 결정하고 etcd 에 Traefik 라우팅 룰로 기록. Manager 와 Worker 사이의 control-plane | |
| App-Proxy Worker | ./backend.ai app-proxy worker start-server |
| Traefik 기반 진입점. Coordinator 가 등록한 룰을 읽어 사용자의 HTTP/WebSocket/TCP traffic 을 적절한 컨테이너:포트로 forward. 사용자가 Jupyter 등 앱에 접속할 때 실제 트래픽을 받는 데몬 | |
의존성 스택 (HalfStack)
| 컴포넌트 | 기본 포트 | 역할 |
|---|---|---|
| PostgreSQL | 8100 | 사용자/세션/vfolder/도메인 등 영속 메타데이터 |
| Redis | 8110 | 세션 스케줄링 큐, 이벤트 dispatch, agent heartbeat |
| etcd | 8120 | 클러스터 설정, 동적 발견 (agent 등록, App-Proxy 라우팅 룰) |
| MinIO (--enable-storage 시) | — | 오브젝트 스토리지 백엔드 |
| Observability stack (--enable-observability 시) | — | Prometheus·Grafana·Loki·Tempo·Pyroscope + OTel collector |
1. 사전 준비
실행 위치: 설치 대상 DGX Spark (노드/서버)
1.1 도구/런타임
선결조건: Docker 및 Docker Compose가 설치되어 있어야 합니다.
docker ps >/dev/null && echo "docker OK"
1.2 포트 개방
Backend.AI의 기반 의존 요소인 PostgreSQL (8110), Redis (8120), etcd (8120) 에서 사용할 TCP 포트가 비어 있어야 합니다.
Backend.AI의 주요 구성 요소인 Manager (8091), Webserver (8090), App Proxy (10200-10500), Agent (6009), Storage Proxy (6021-6022) 에서 사용할 TCP 포트가 비어 있어야 합니다.
1.3 의존성 및 vLLM 이미지 다운로드
sudo apt update && sudo apt install git-lfs
curl --proto '=https' --tlsv1.2 -fsSL https://static.pantsbuild.org/setup/get-pants.sh | bash
curl -LsSf https://astral.sh/uv/install.sh | sh
이후 SSH 연결을 다시 시작합니다. Python 3.13.7을 설치합니다.
uv python install 3.13.7
이제 실습에 사용할 vLLM 이미지를 다운로드합니다.
docker pull cr.backend.ai/multiarch/vllm:0.23.0-cuda12.9-ubuntu22.04
1.4 설치 파일 다운로드
Backend.AI Open Source의 최신 안정 버전 소스 코드 및 설치 파일을 다운로드합니다.
git clone https://github.com/lablup/backend.ai -b 26.4.4 && cd backend.ai
git lfs install && git lfs pull
wget https://github.com/lablup/backend.ai/releases/download/26.4.4/backendai-install-linux-aarch64 && chmod +x backendai-install-linux-aarch64
sudo apt update
1.5 DGX Spark IP 주소 확인
사용자의 컴퓨터에서 DGX Spark에 접근 가능한 IP 주소를 확인합니다. 대부분의 경우 이것은 SSH 명령에서 @ 오른쪽의 주소에 해당합니다: ssh dgx@192.168.2.24
2. 설치
다음 명령을 실행하여 대화형 설치 프로그램을 시작합니다.
./backendai-install-linux-aarch64 install --accelerator cuda
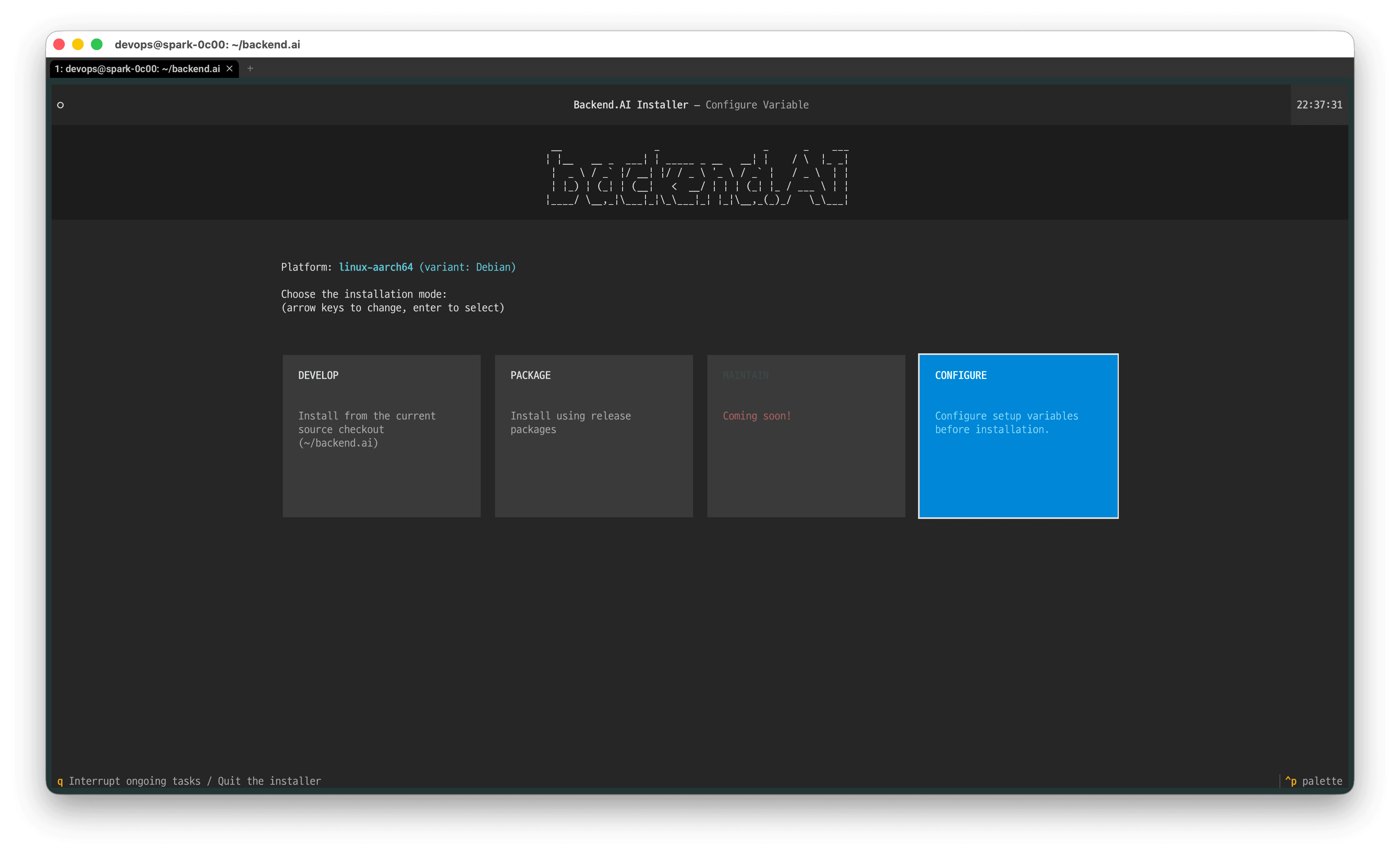
위와 같은 설치 화면이 나타납니다. 설치를 계속하기 전에, 먼저 키보드 방향키를 이용해 'CONFIGURE' 로 이동 후, 엔터를 눌러 Backend.AI 설치 프로그램의 설정 모드에 진입합니다.
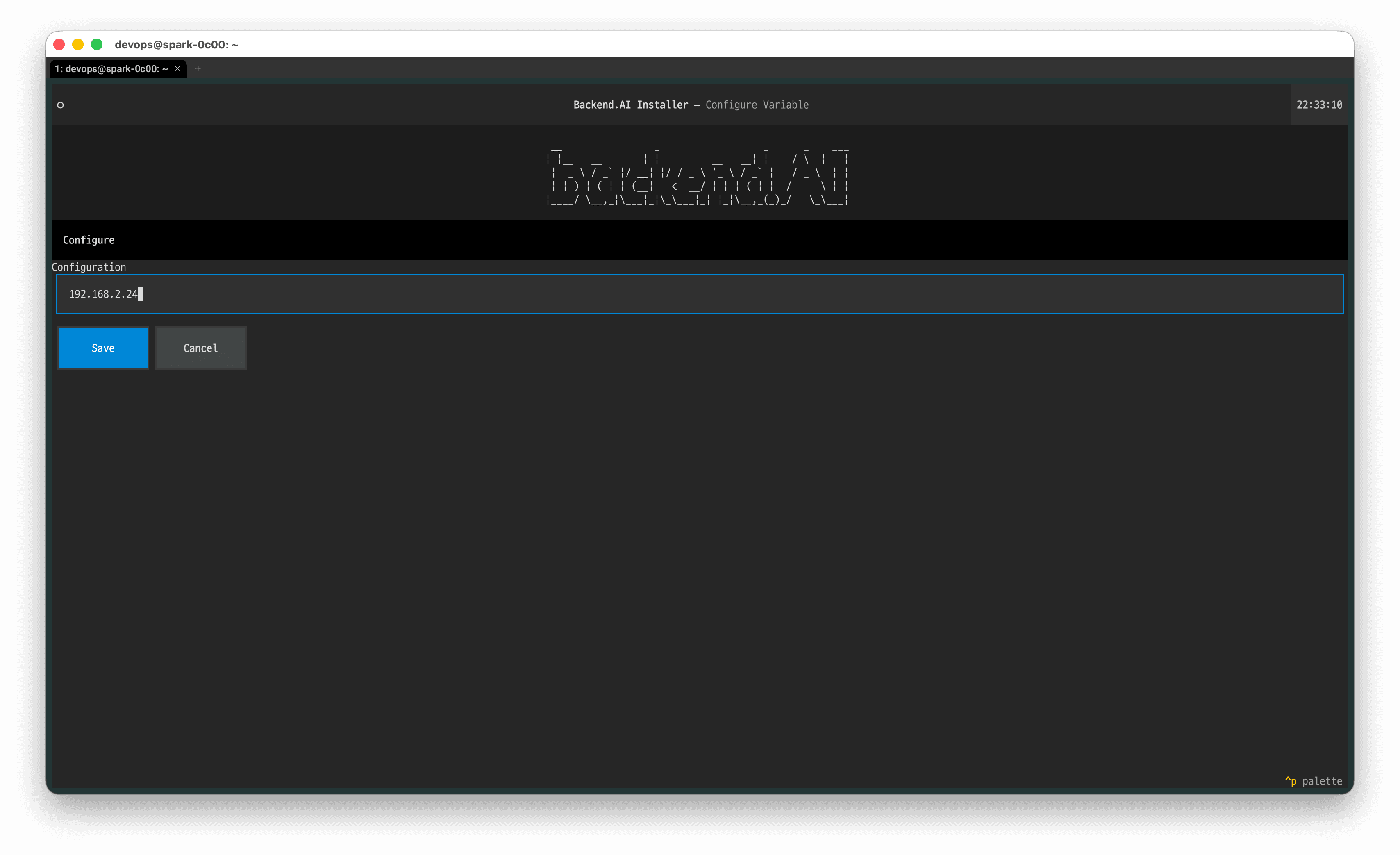
1.4 단계에서 확인한 DGX Spark의 IP를 입력 후 '저장' 을 선택합니다.
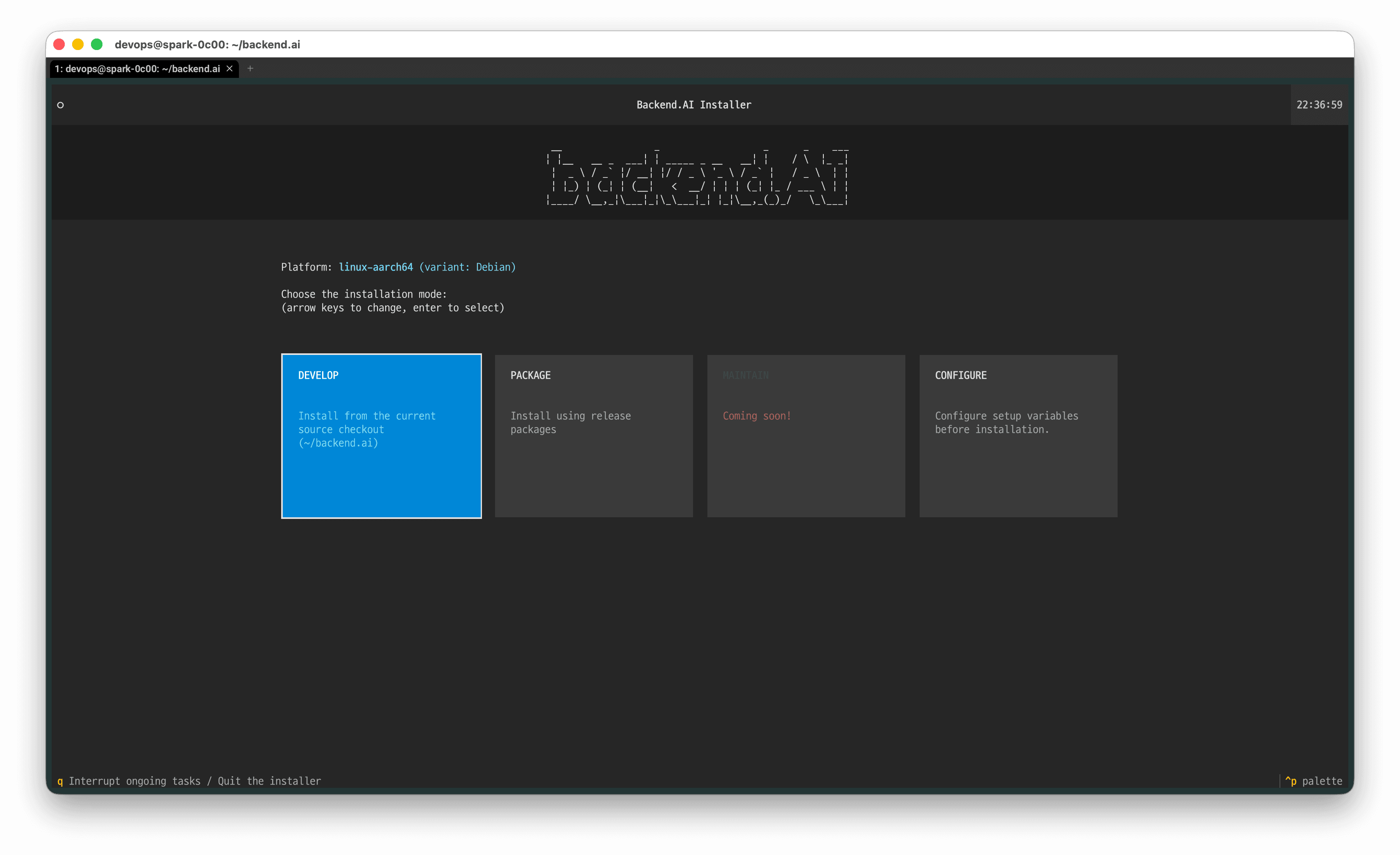
키보드 방향키를 이용해 'DEVELOP' 로 이동 후, 엔터를 눌러 Backend.AI 패키지 버전의 설치를 시작합니다.
NOTE: 26.4.0 ~ 26.4.4 버전의 경우 현재 PACKAGE 설치가 정상 동작하지 않는 버그가 존재합니다.
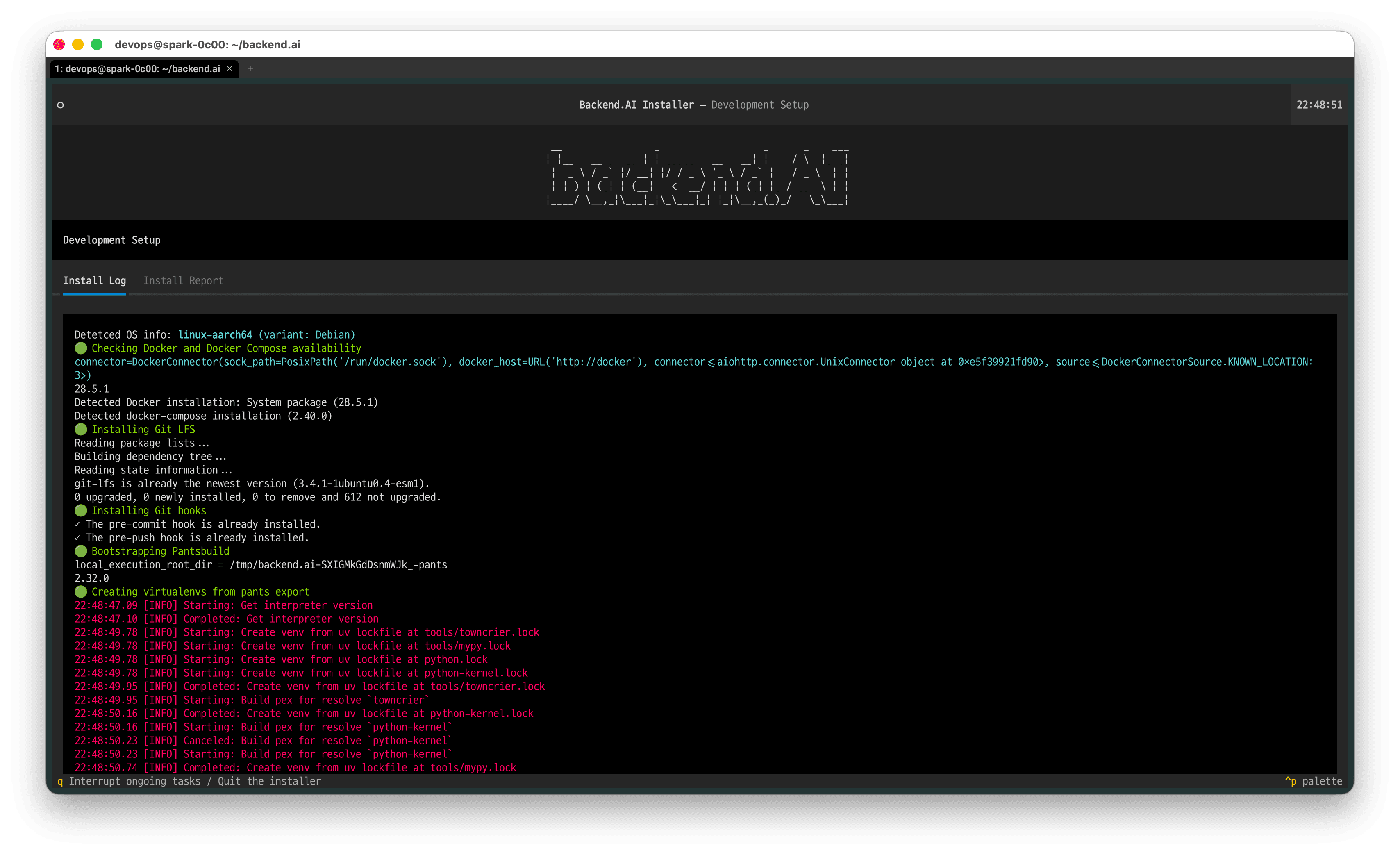
설치는 자동으로 진행되며, 설치가 완료되면 Install Report가 제공됩니다.
3. 설치 후
실행 위치: 설치 대상 노드
3.1 설치 결과 파일
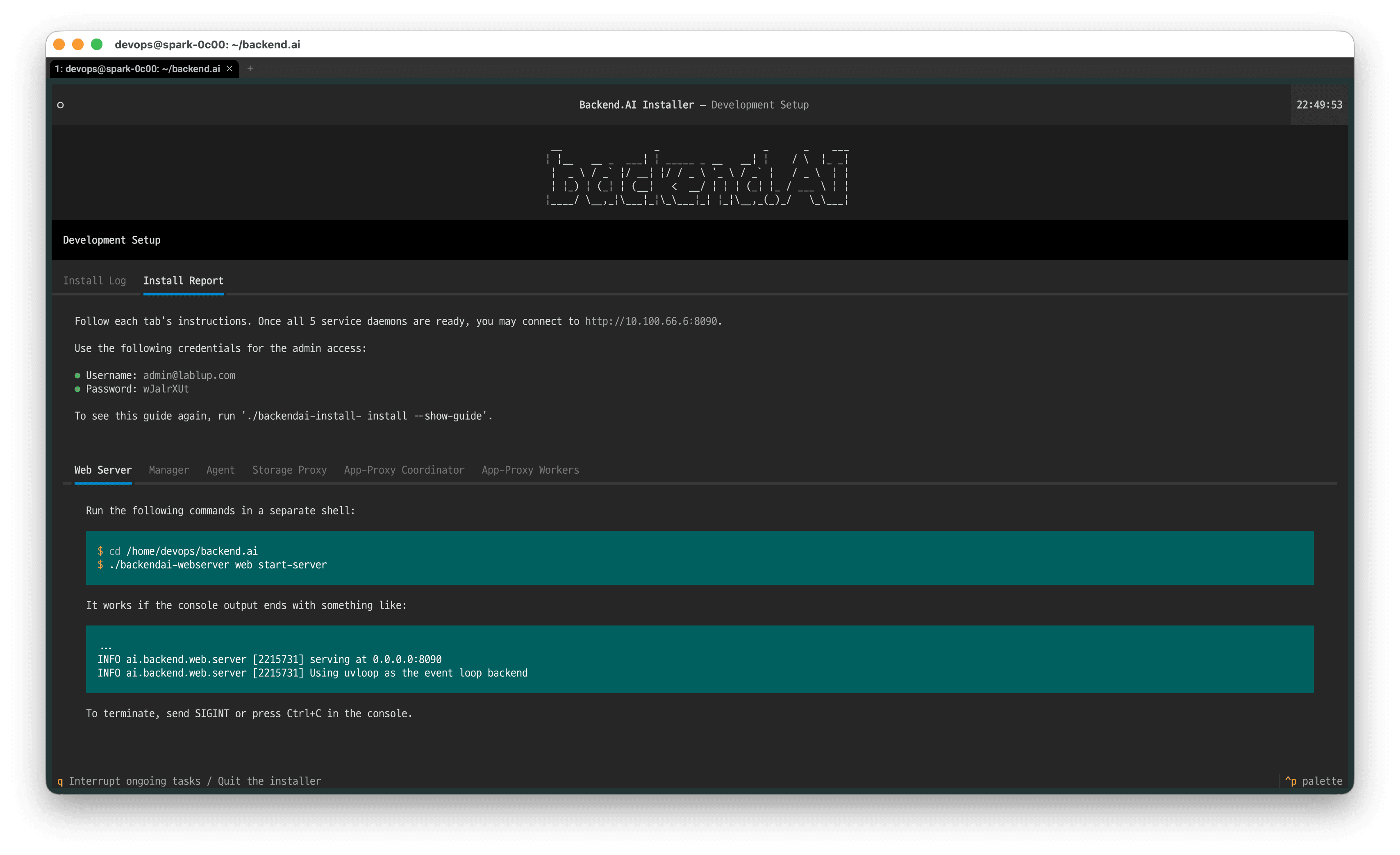
- 설치가 완료되고 나면, 현재 디렉터리에
INSTALL-INFO파일이 생성됩니다. 설치 완료 후 표시되는 안내 메시지 혹은 해당 파일을 읽는 것으로 초기 접속 방법을 확인할 수 있습니다. 설치 완료 후 표시되는 안내 메시지를 다시 보고 싶다면 아래 명령을 실행합니다.
./backendai-install-linux-aarch64 install --show-guide
backend.ai 소스 코드 폴더 아래에서 다음 명령을 실행하여 데이터베이스를 초기화합니다.
$ ./py -m alembic -c alembic-appproxy.ini upgrade head
INFO [alembic.runtime.migration] Context impl PostgresqlImpl.
INFO [alembic.runtime.migration] Will assume transactional DDL.
INFO [alembic.runtime.migration] Running upgrade -> 5c6942374c62, initial tables
INFO [alembic.runtime.migration] Running upgrade 5c6942374c62 -> e81f833e28fa, create circuits table
INFO [alembic.runtime.migration] Running upgrade e81f833e28fa -> 6e38326a056a, rename misrepresentative column names
INFO [alembic.runtime.migration] Running upgrade 6e38326a056a -> a06b7ba8f4bd, add worker.wildcard_traffic_port column
INFO [alembic.runtime.migration] Running upgrade a06b7ba8f4bd -> 0dd436073e84, add wokrer.status column
INFO [alembic.runtime.migration] Running upgrade 0dd436073e84 -> 825d283e0743, add circuit.runtime_variant column
INFO [alembic.runtime.migration] Running upgrade 825d283e0743 -> 66f87e010f90, add worker.traefik_last_used_marker_path
INFO [alembic.runtime.migration] Running upgrade 66f87e010f90 -> 7dbbc087108e, separate use_tls into tls_listen and tls_advertised
INFO [alembic.runtime.migration] Running upgrade 7dbbc087108e -> a1b2c3d4e5f6, add endpoint health check table
/home/devops/backend.ai/src/ai/backend/appproxy/coordinator/models/alembic/versions/a1b2c3d4e5f6_add_endpoint_health_check_table.py:67: SAWarning: Column 'endpoints.id' is marked as a member of the primary key for table 'endpoints', but has no Python-side or server-side default generator indicated, nor does it indicate 'autoincrement=True' or 'nullable=True', and no explicit value is passed. Primary key columns typically may not store NULL.
op.execute(insert_query)
backend.ai 소스 코드 폴더 아래의 webserver.conf 파일을 선호하는 파일 편집기로 엽니다. 이후 max_memory_per_container 값을 64에서 128으로 수정 후 파일을 저장합니다.
3.2 서비스 기동
설치 후 tmux를 실행합니다. 다음 서비스 데몬을 기동합니다. (cd <target-path> 후)
./backend.ai web start-server --debug
./backend.ai mgr start-server --debug
./backend.ai ag start-server --debug
./backend.ai storage start-server --debug
./backend.ai app-proxy-coordinator start-server --debug
./backend.ai app-proxy-worker start-server --debug
./backend.ai app-proxy worker start-server -f app-proxy-worker-tcp.toml --debug
3.3 접속
- WebUI:
http://<1.4에서 확인한 DGX Spark의 IP Address>:8090 - 기본 관리자 계정:
- Username:
admin@lablup.com- Password:wJalrXUt
운영 환경인 경우 최초 로그인 후 기본 비밀번호를 변경하는 것이 안전합니다.
4. vLLM을 이용해 모델 실행하기
4.1 모델 폴더 생성
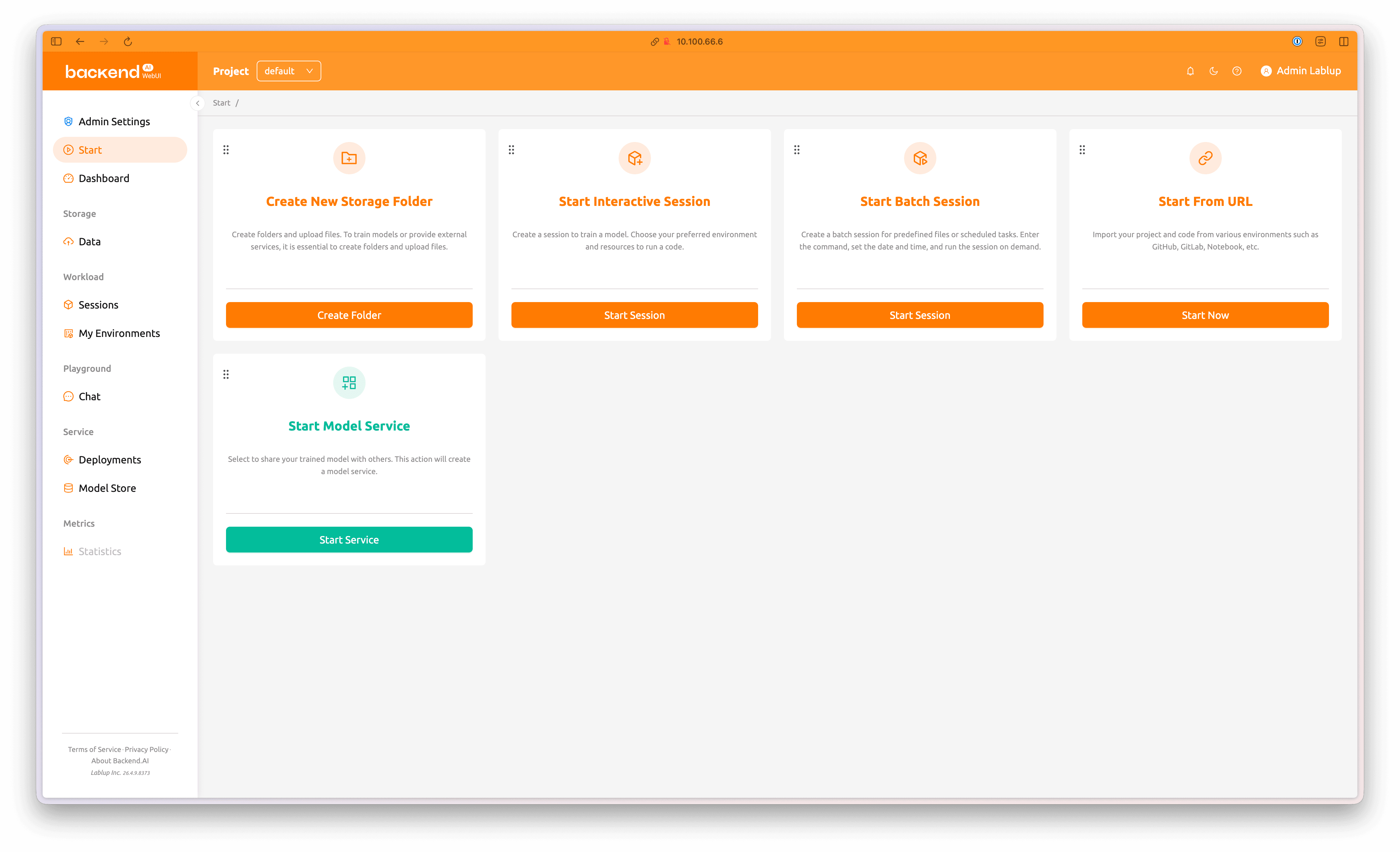
Backend.AI의 WebUI로 접속합니다. 초기 관리자 로그인 정보를 입력하여 관리자 계정으로 로그인합니다. 좌측의 'Data' 탭을 클릭하여 'Create Folder' 버튼을 눌러 새 모델 폴더를 생성하는 다이얼로그를 엽니다. 혹은, Start 페이지에서 바로 'Create Folder' 버튼을 누를 수도 있습니다.
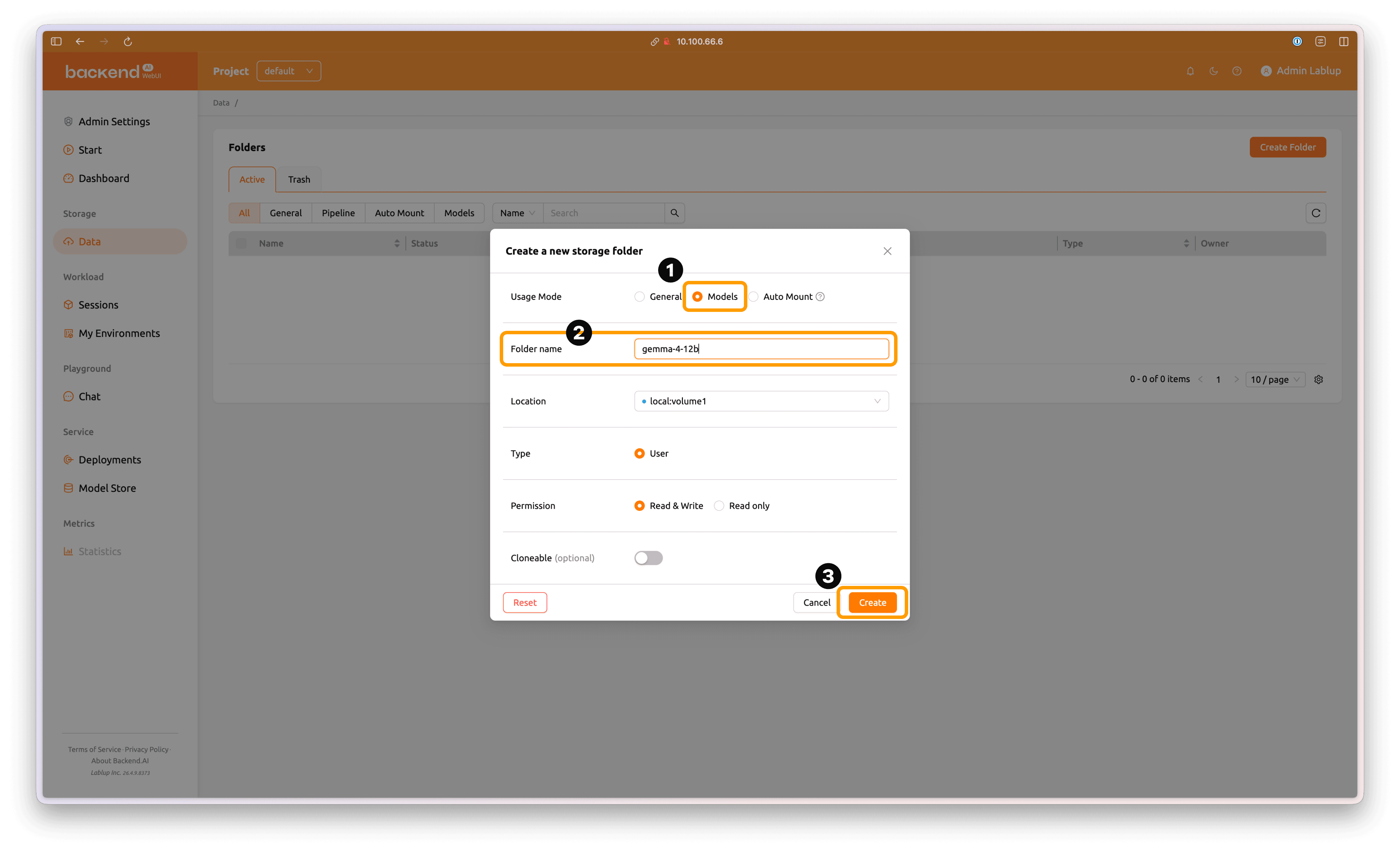
폴더 형식을 'Model' 로 선택 후, 적절한 폴더명을 입력합니다. 'Create' 버튼을 눌러 모델 폴더를 생성합니다.
폴더가 생성되었습니다.
4.2 Backend.AI 세션 생성
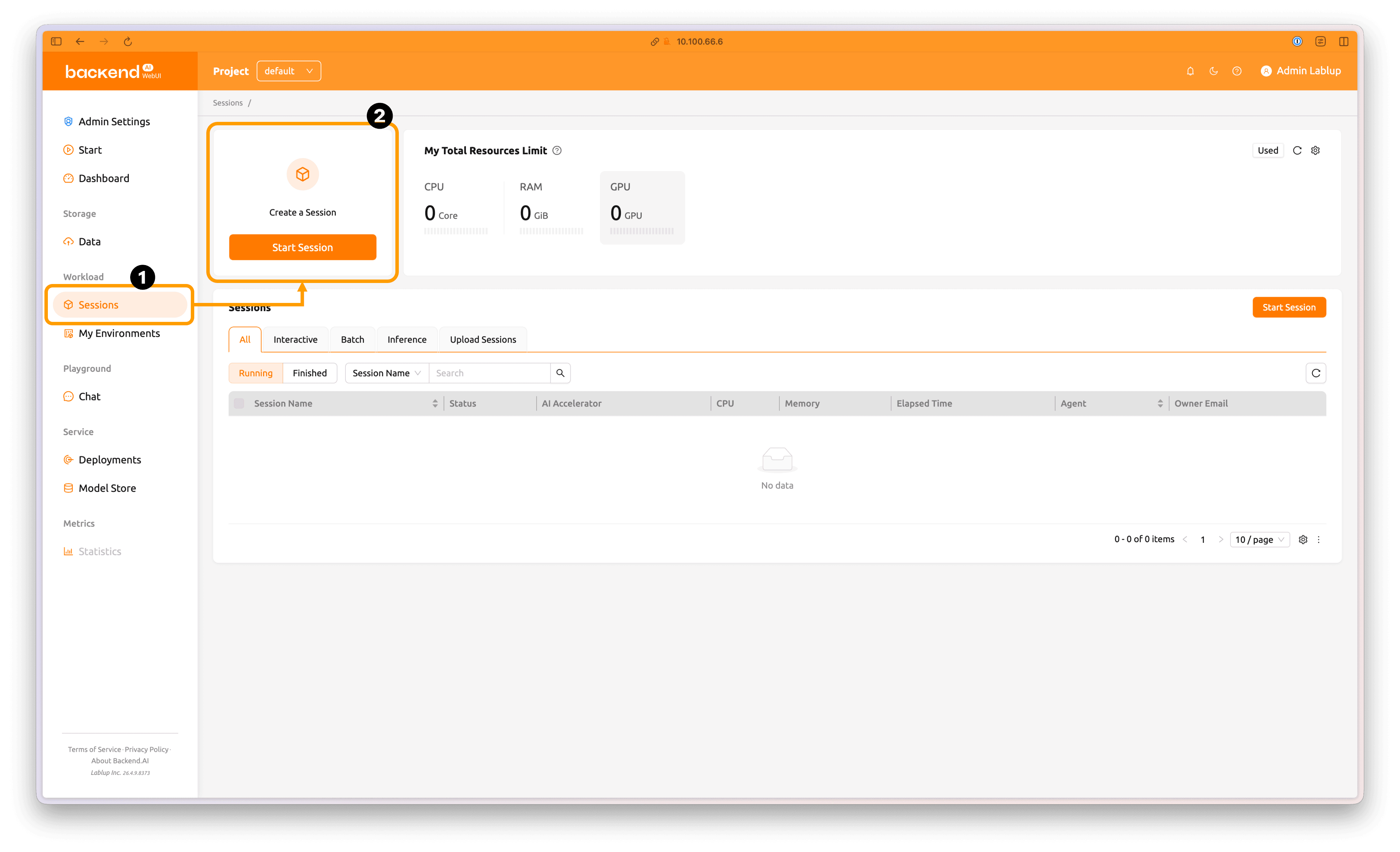
메뉴의 'Session' 탭을 클릭해 세션 페이지로 이동합니다. 페이지 상단 'Start Session' 버튼을 클릭해 새로운 세션을 생성하는 페이지로 이동합니다.
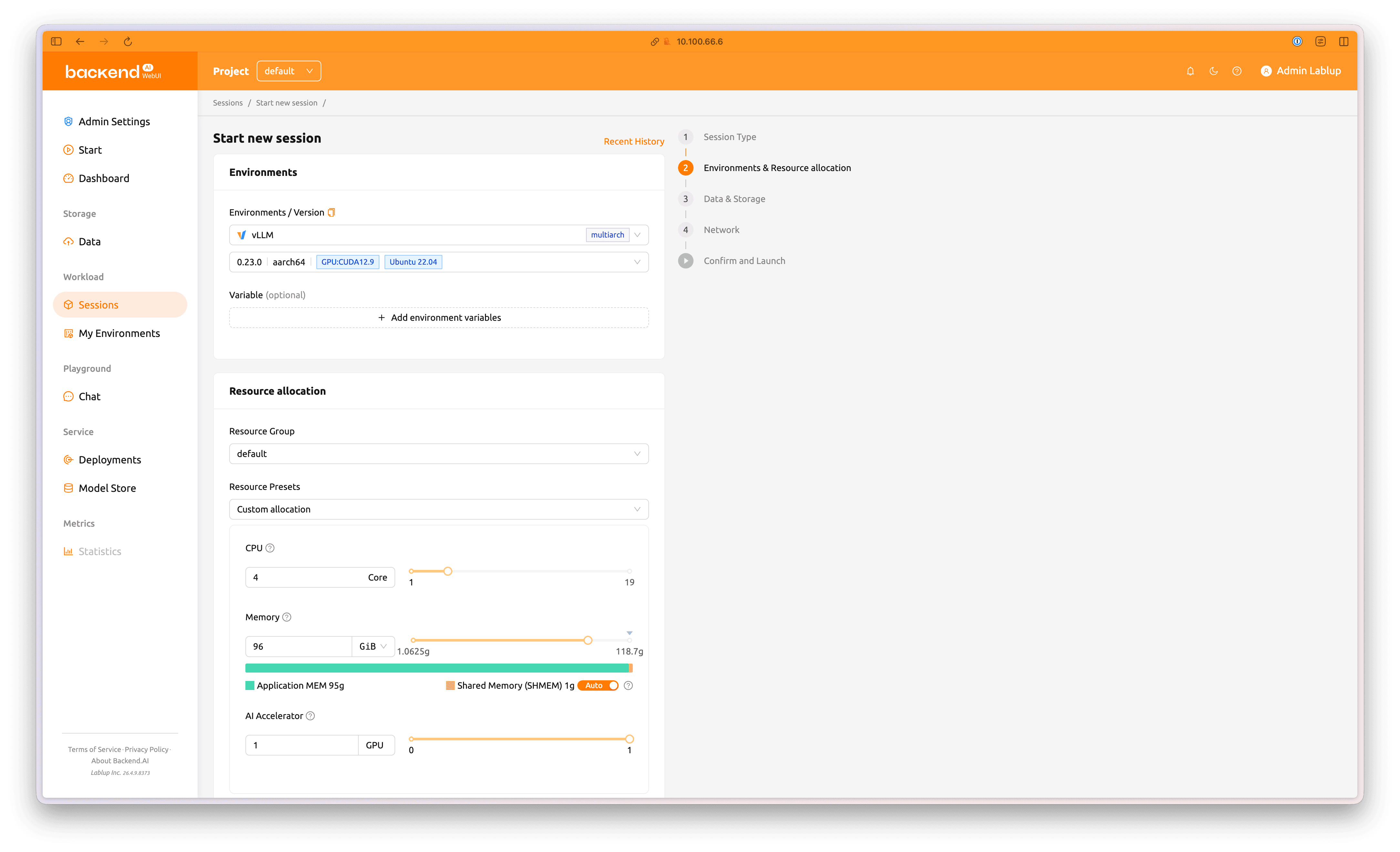
2단계, 'Environments & Resource allocation' 항목에서 세션에 할당될 자원량 및 이미지를 다음과 같이 설정합니다.
- Environments / Versions:
vLLM, 0.23.0 | aarch64 | CUDA 12.9 | Ubuntu 22.04 - Resource Group:
default - Resource Preset:
Custom allocation - GPU:
4Core - Memory:
96GiB - AI Accelerator:
1GPU
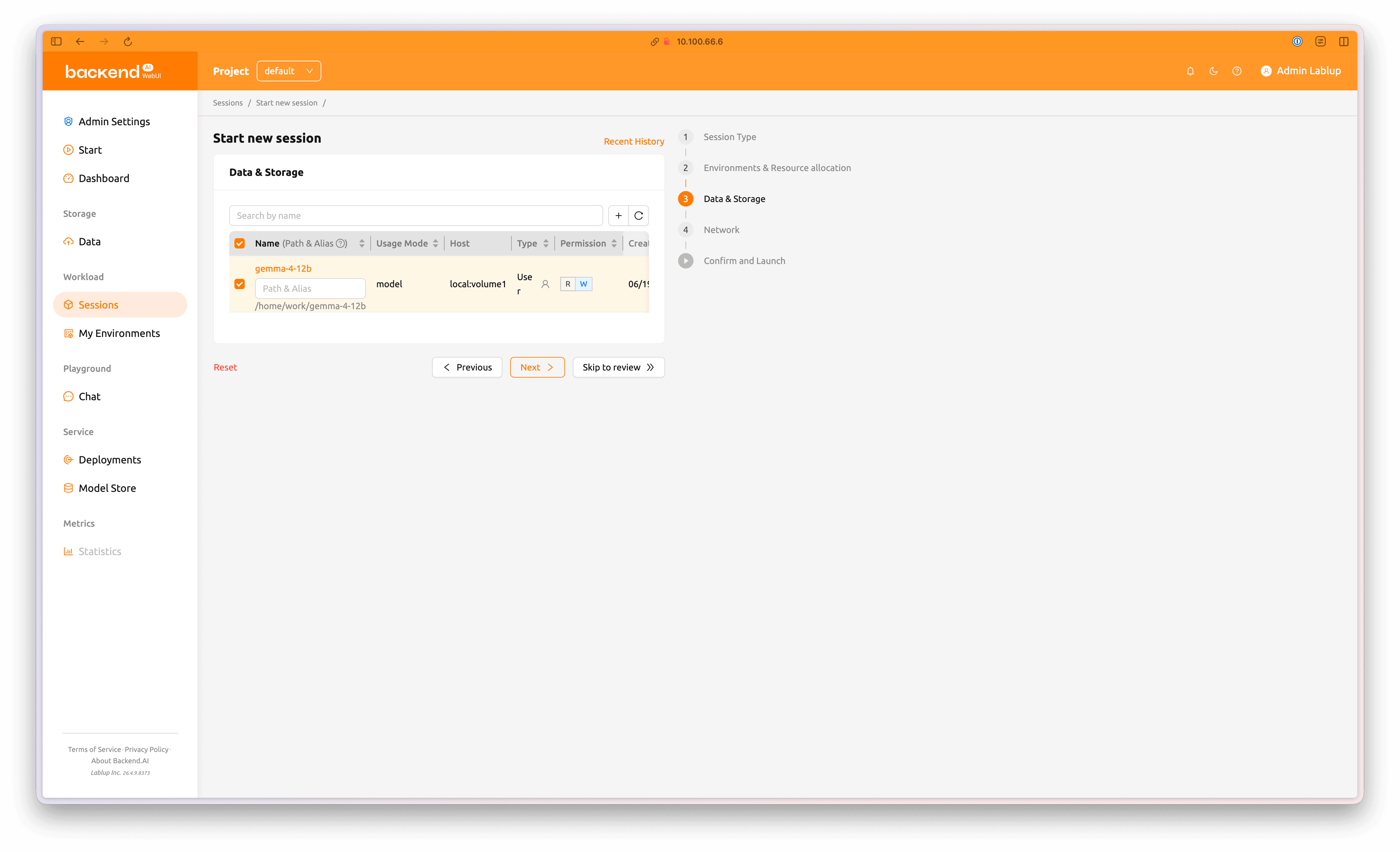
3단계, 'Data & Storage' 항목에서 앞에서 생성한 gemma-4-12b 폴더를 선택하여 탑재합니다.
이후 'Skip to review' 버튼을 클릭하여 마지막 단계로 진입합니다.
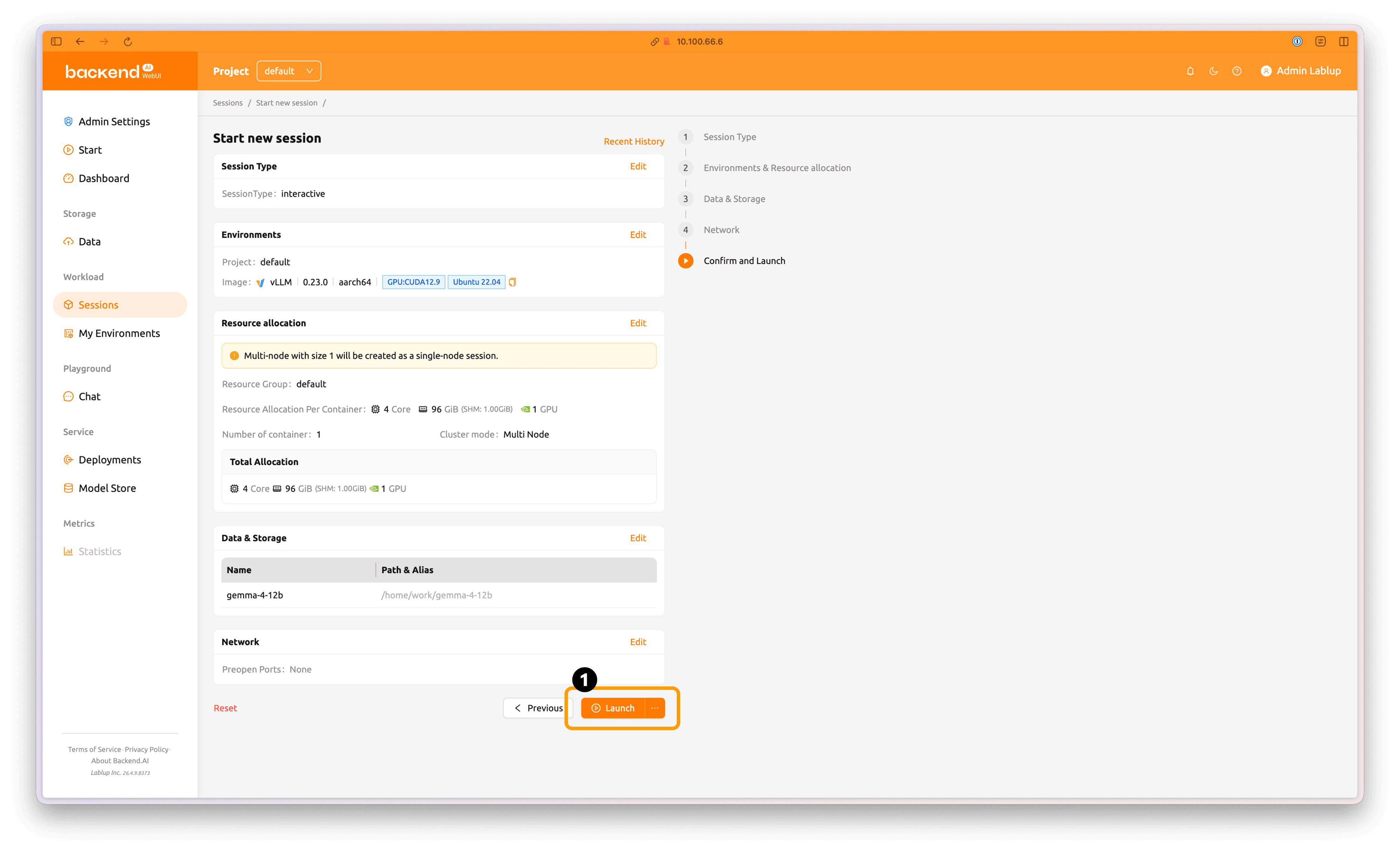
마지막으로 모든 값이 올바르게 설정되었는지 확인한 후, 'Launch' 버튼을 눌러 세션을 실행합니다.
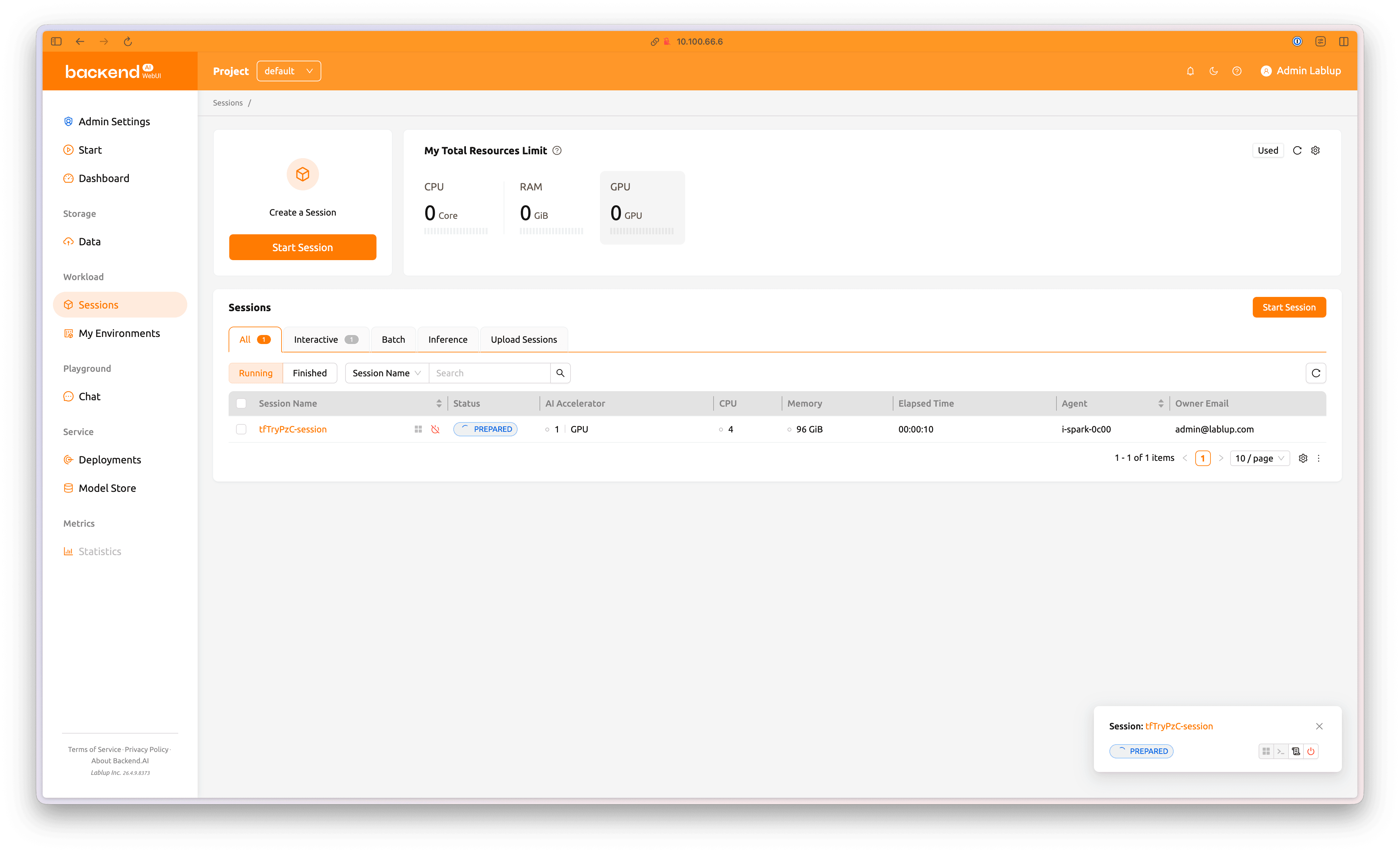
세션이 제출되어 실행 대기중인 모습입니다. 세션 실행이 대기중인 경우 상태값이 PREPARED라고 나타나며, 로딩 스피너가 동작합니다.
세션 이름을 클릭하면 보다 상세한 정보를 확인할 수 있습니다.
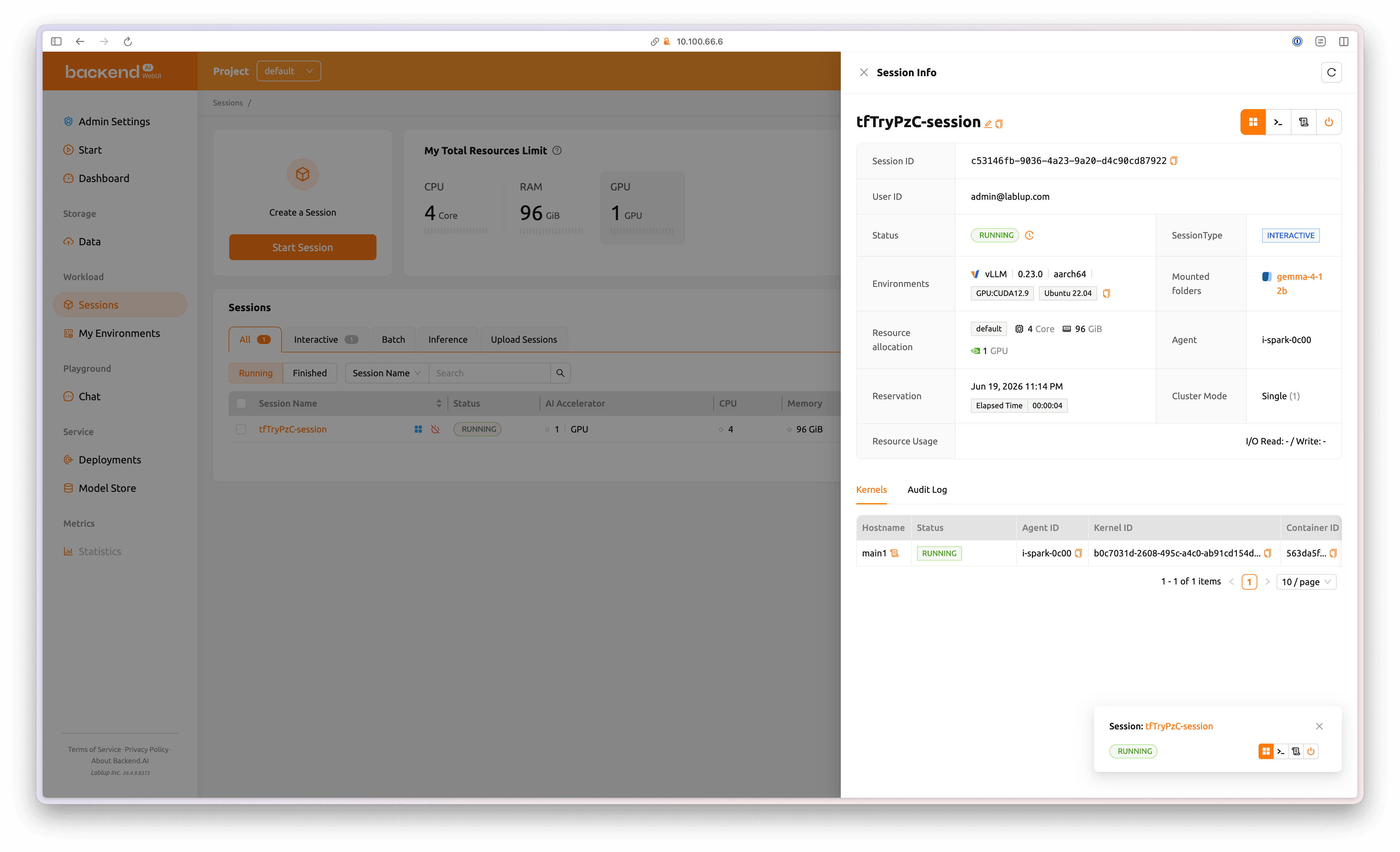
세션 실행이 완료되면 세션의 상태가 RUNNING 으로 바뀝니다.
4.3 vLLM 실행
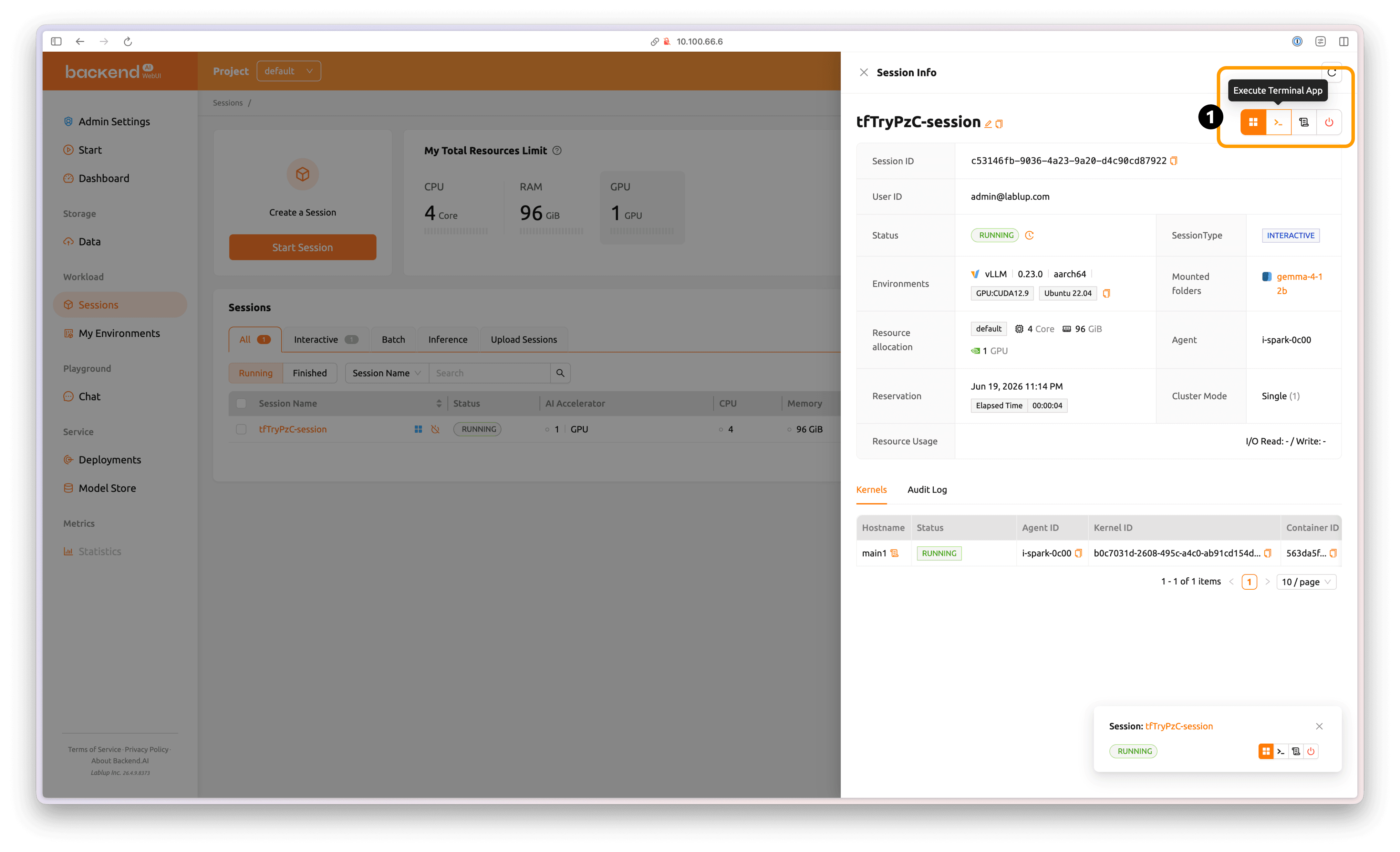
세션 상세 탭의 오른쪽 상단 'Execute Terminal App' 버튼을 클릭해 컨테이너 환경의 리눅스 셸에 진입합니다.
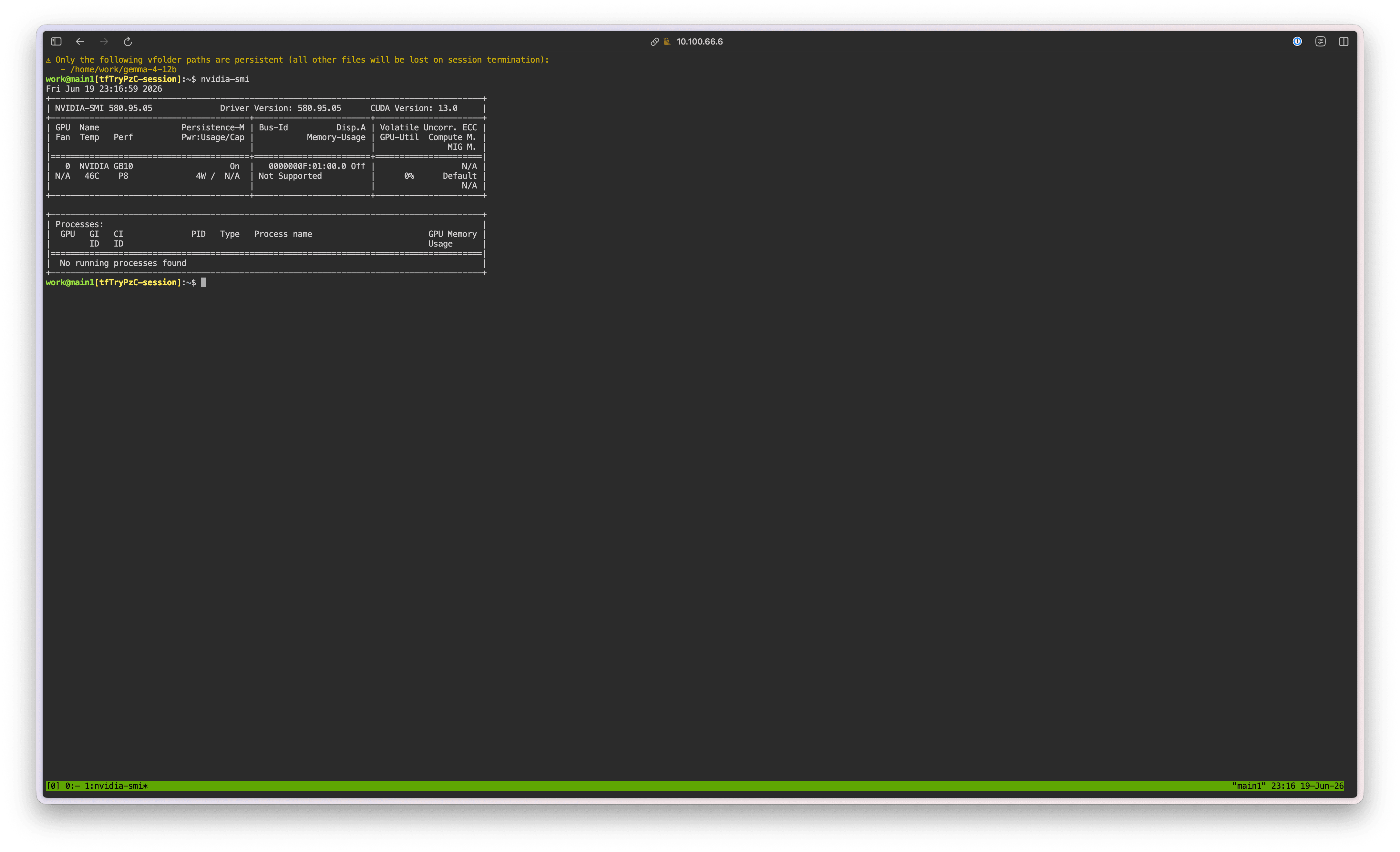
먼저 nvidia-smi 명령을 실행하여 GPU를 정상적으로 인식하는지 확인합니다.
이후 아래 명령을 실행하여 Gemma 4 12B 모델을 다운로드 받습니다.
hf download --local-dir gemma-4-12b google/gemma-4-12b-it
다운로드가 완료된 이후 아래 명령을 실행하여 모델이 정상적으로 다운로드 되었는지 확인합니다.
ls -al gemma-4-12b
이후 다음 명령으로 vLLM 서버를 실행합니다.
vllm serve gemma-4-12b --gpu-memory-utilization 0.5
Note: 왜 GPU Memory Utilization 값을 작게 설정해야 하나요?
vLLM의 한계로 인해, Unified Memory가 적용된 GB10 환경에서 컨테이너 메모리가 장치의 총 메모리 양보다 작게 설정되는 경우 이를 제대로 인식하지 못하여 Illegal Memory Access 오류가 발생할 수 있습니다.
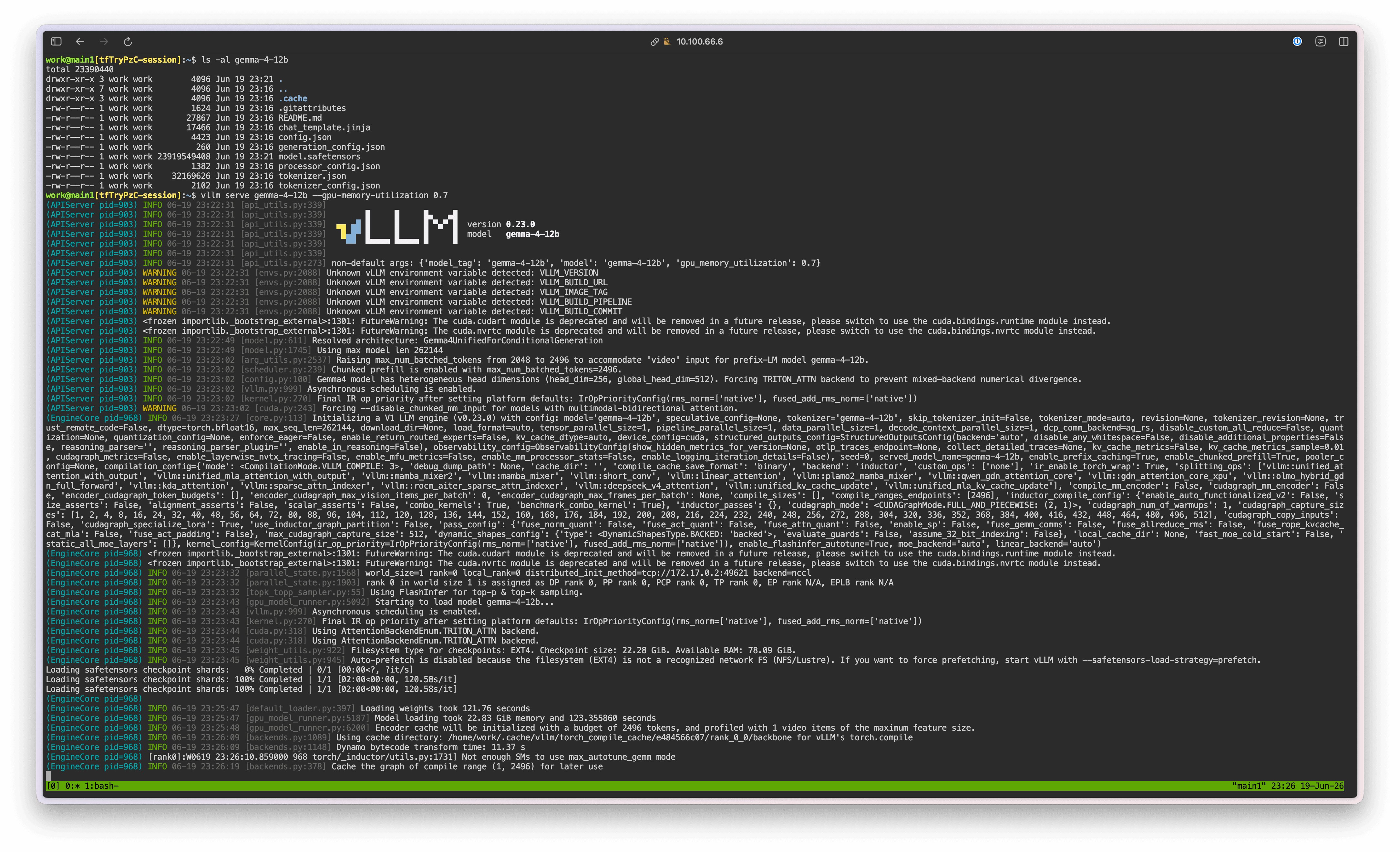
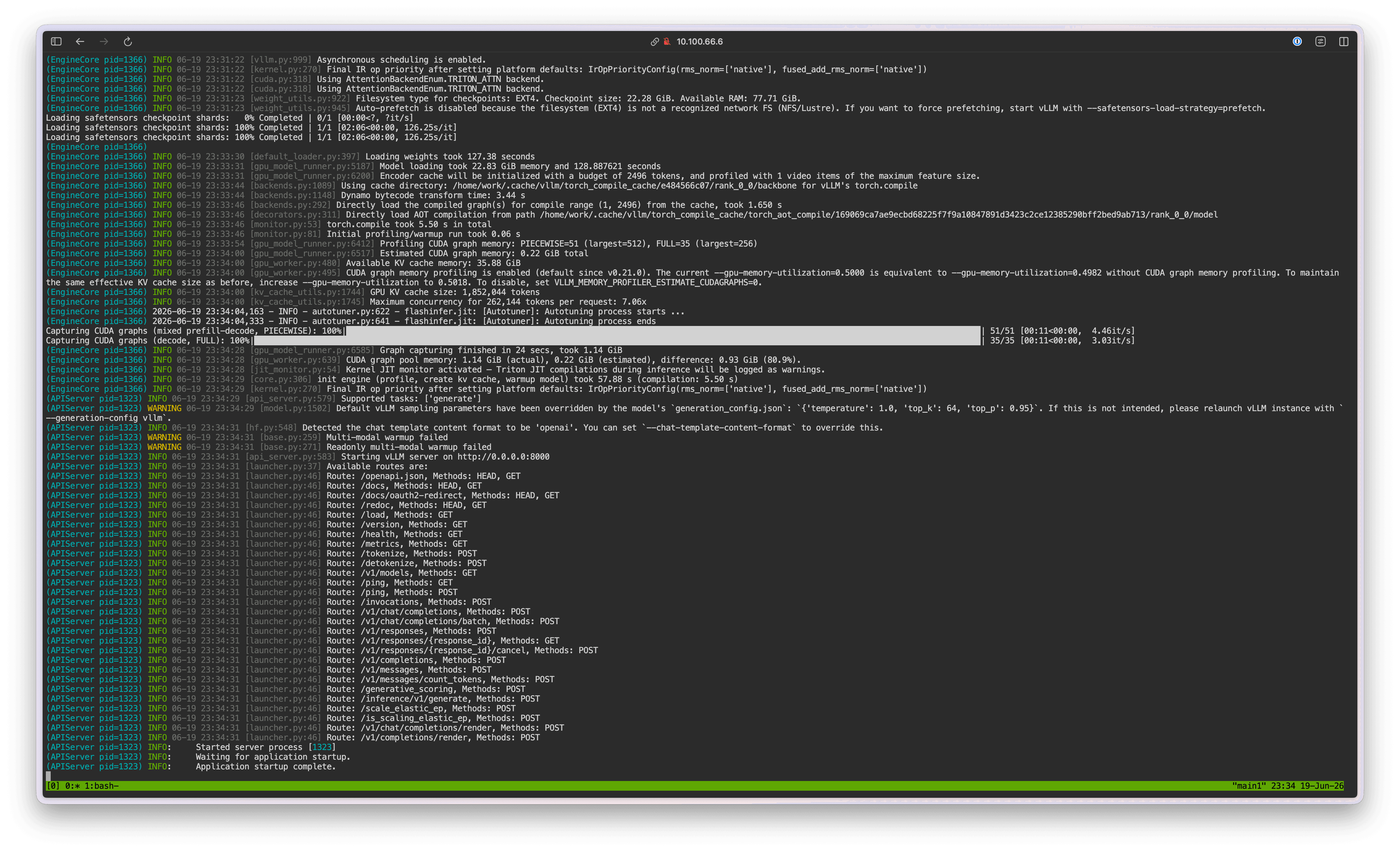
vLLM 서버가 실행되면 이후 아래 cURL 명령으로 추론을 시험해 볼 수 있습니다.
curl http://localhost:8000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{ "model": "gemma-4-12b", "messages": [ { "role": "user", "content": "Hello!" } ] }'
정상적으로 값이 반환되면 터미널 브라우저 창을 닫습니다.
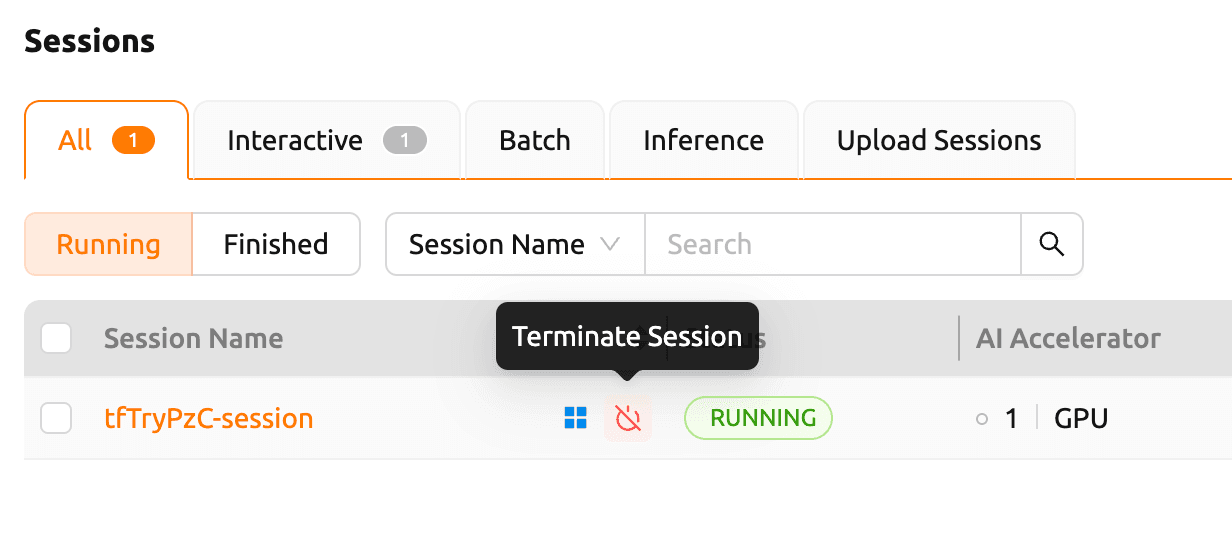
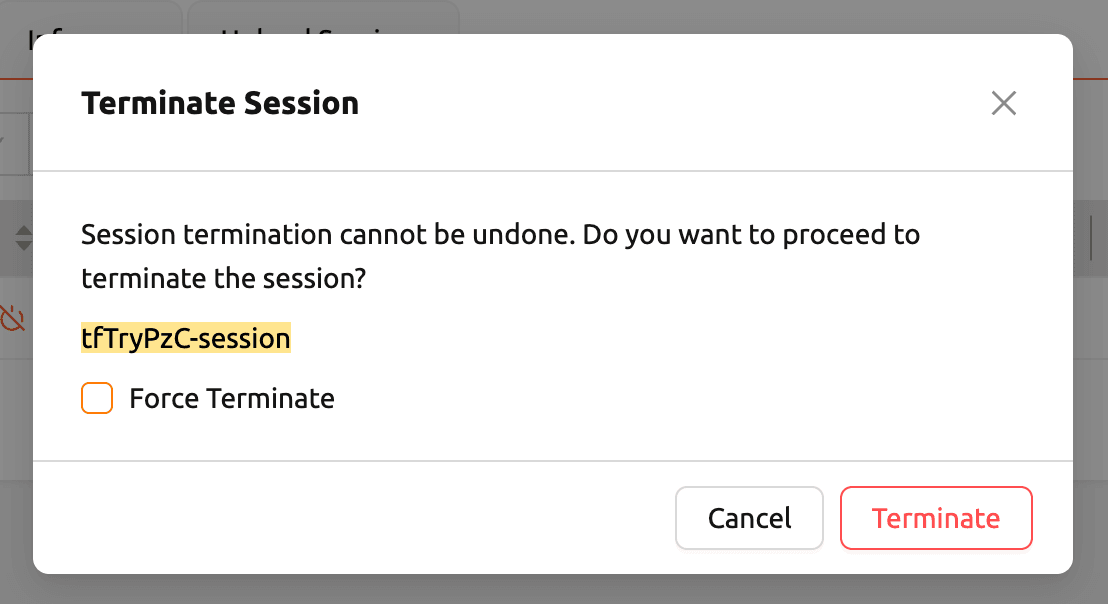
세션 목록에서 실행한 세션을 선택, 'Terminate Session' 버튼을 클릭해 세션을 종료합니다.
5. vLLM으로 모델 서비스하기
5.1 Deployment 생성
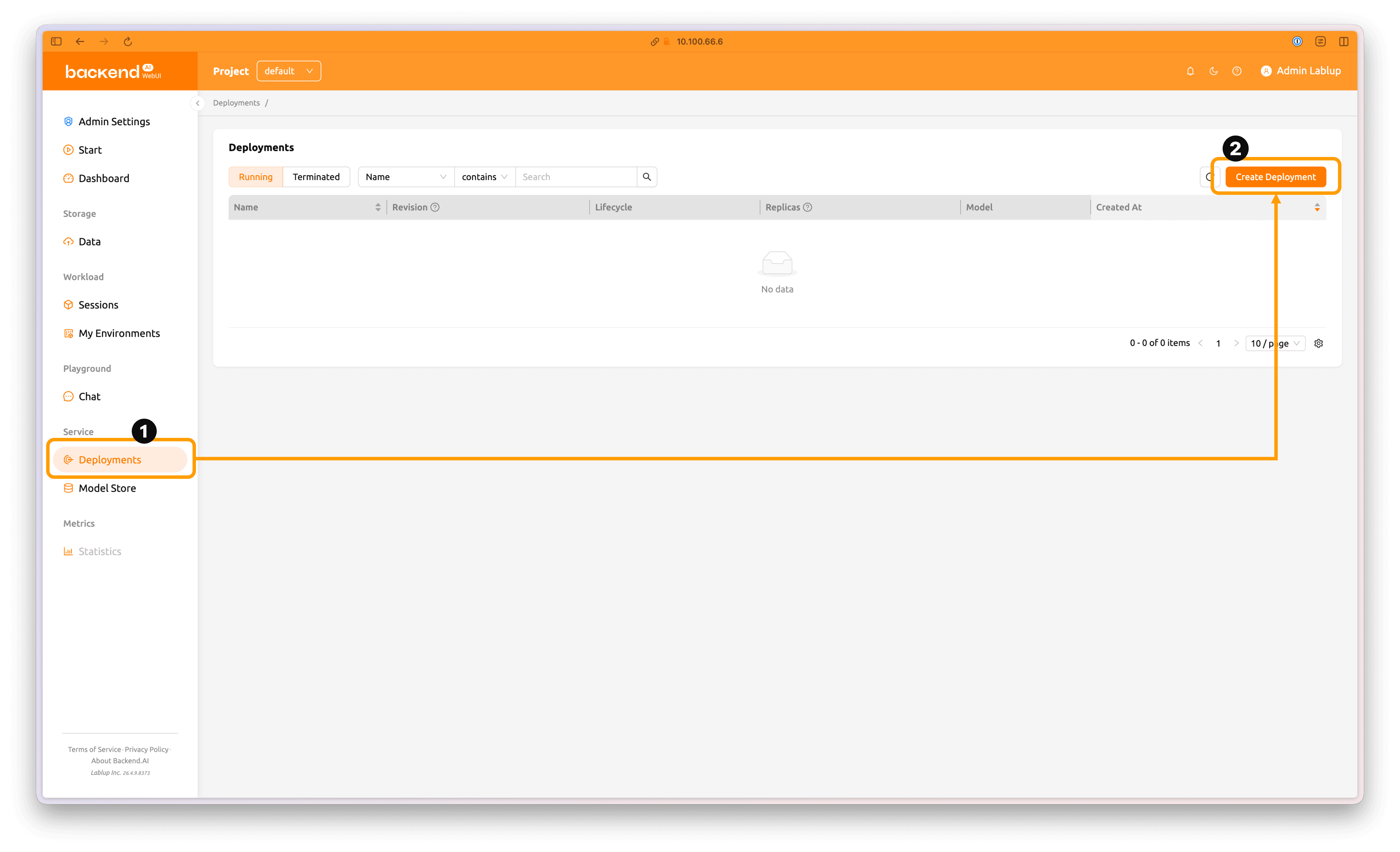
좌측의 'Deployments' 탭을 클릭하여 Deployment 페이지로 이동합니다.
페이지 우측 상단의 'Create deployment' 버튼을 클릭하여 새 Deployment를 생성합니다.
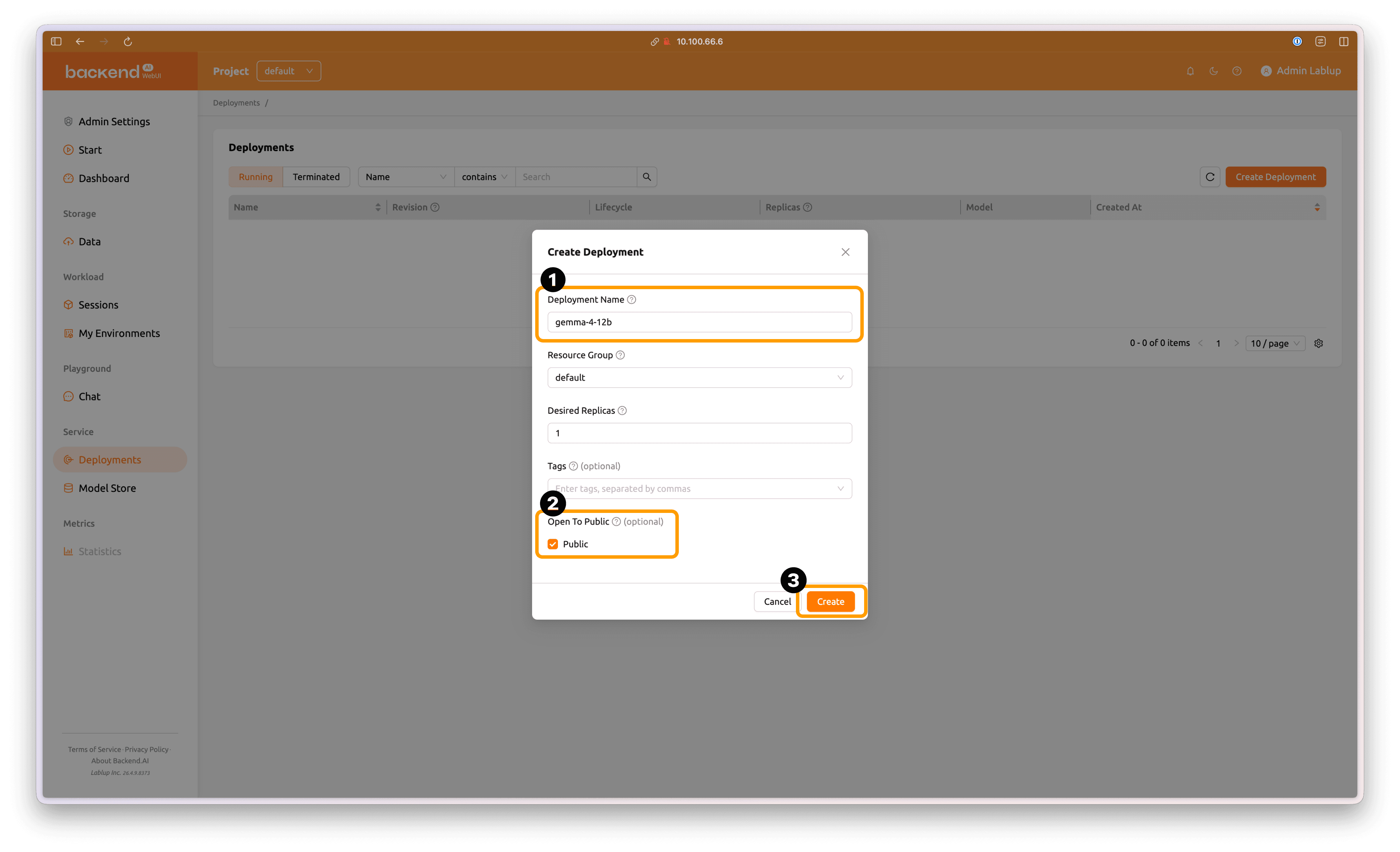
생성할 Deployment에 적절한 이름을 붙여줍니다. 'Open To Public' 옵션을 활성화 한 후, 'Create' 버튼을 눌러 새로운 Deployment를 생성합니다.
Open To Public 옵션을 활성화하지 않을 경우, Deployment 페이지에서 생성한 Access Token을 추론 요청에 포함해야 (
Authorization: BearerHTTP Header) 모델 서비스에 접근할 수 있습니다.
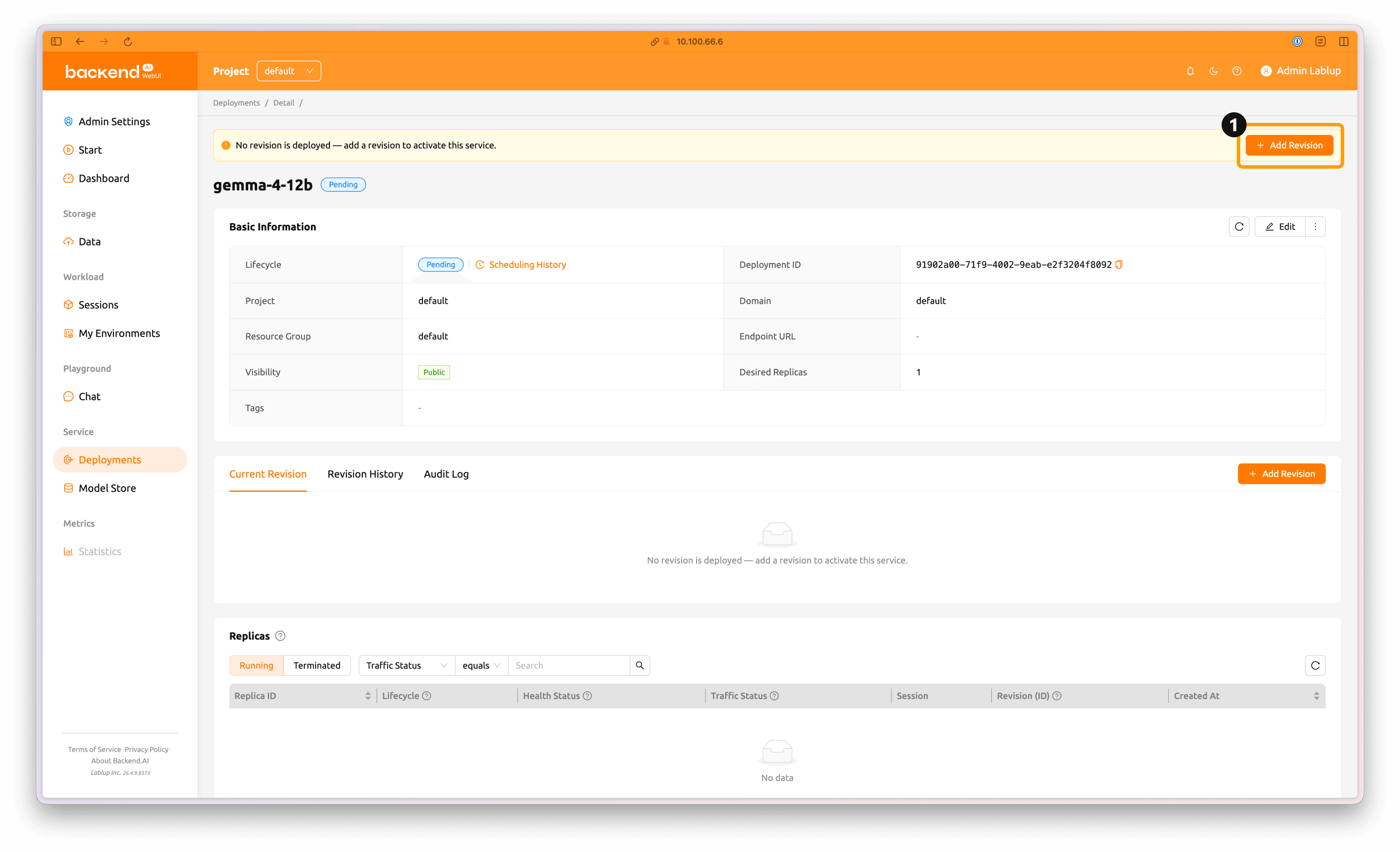
새로운 Deployment가 생성되었습니다. 'Add Revision' 버튼을 눌러 Revision을 생성합니다.
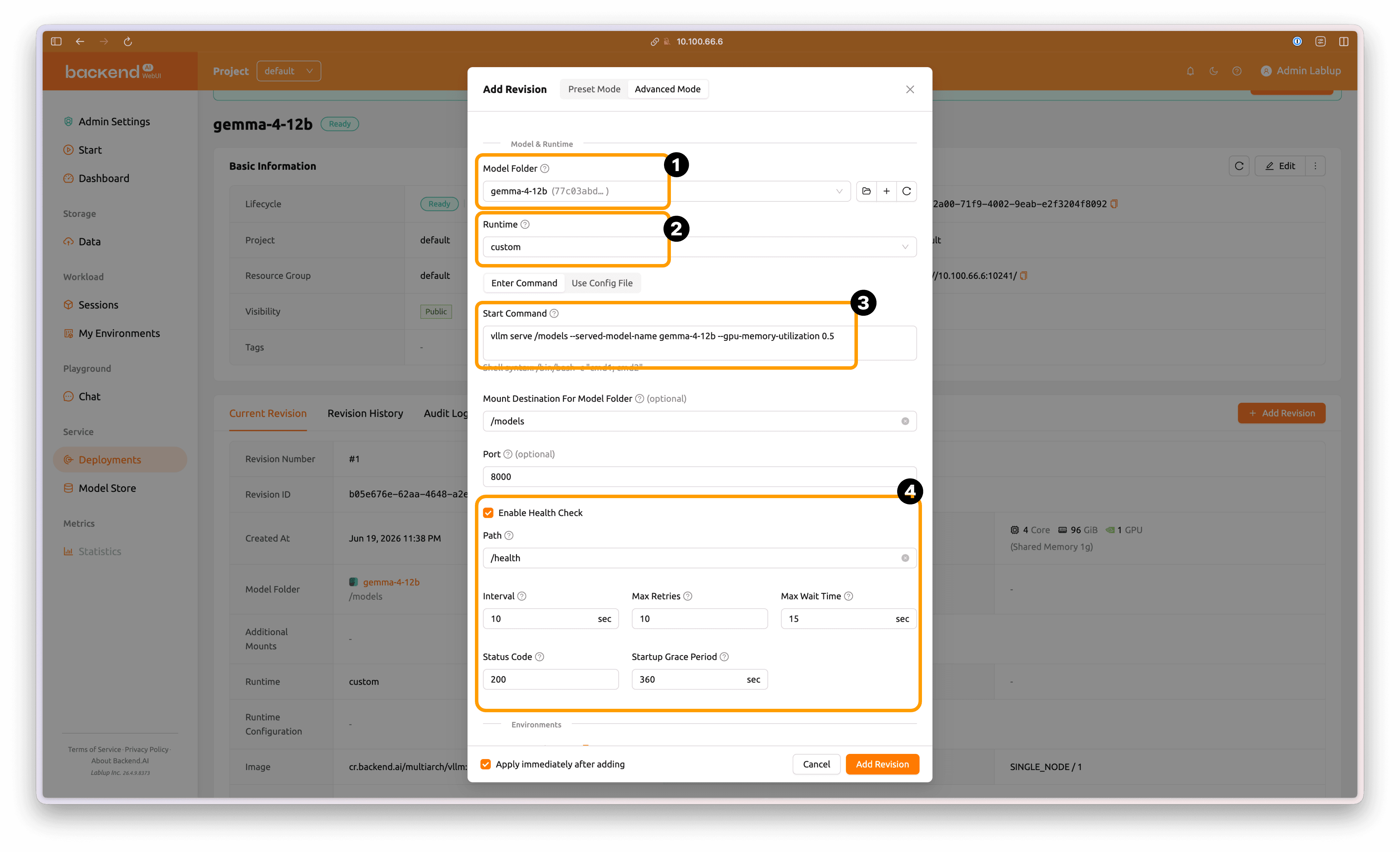
Advanced Mode에서 Model Folder를 gemma-4-12b, Runtime을 custom으로 둔 후 실행 명령을 아래와 같이 입력합니다.
vllm serve /models --served-model-name gemma-4-12b --gpu-memory-utilization 0.5
이후 아래쪽의 Enable Health Check 값을 활성화합니다.
Startup Grade Period는 DGX Spark에서의 Gemma 4 12B 모델 로드 속도를 고려하여 제안된 디폴트 값에서 600초로 변경합니다.
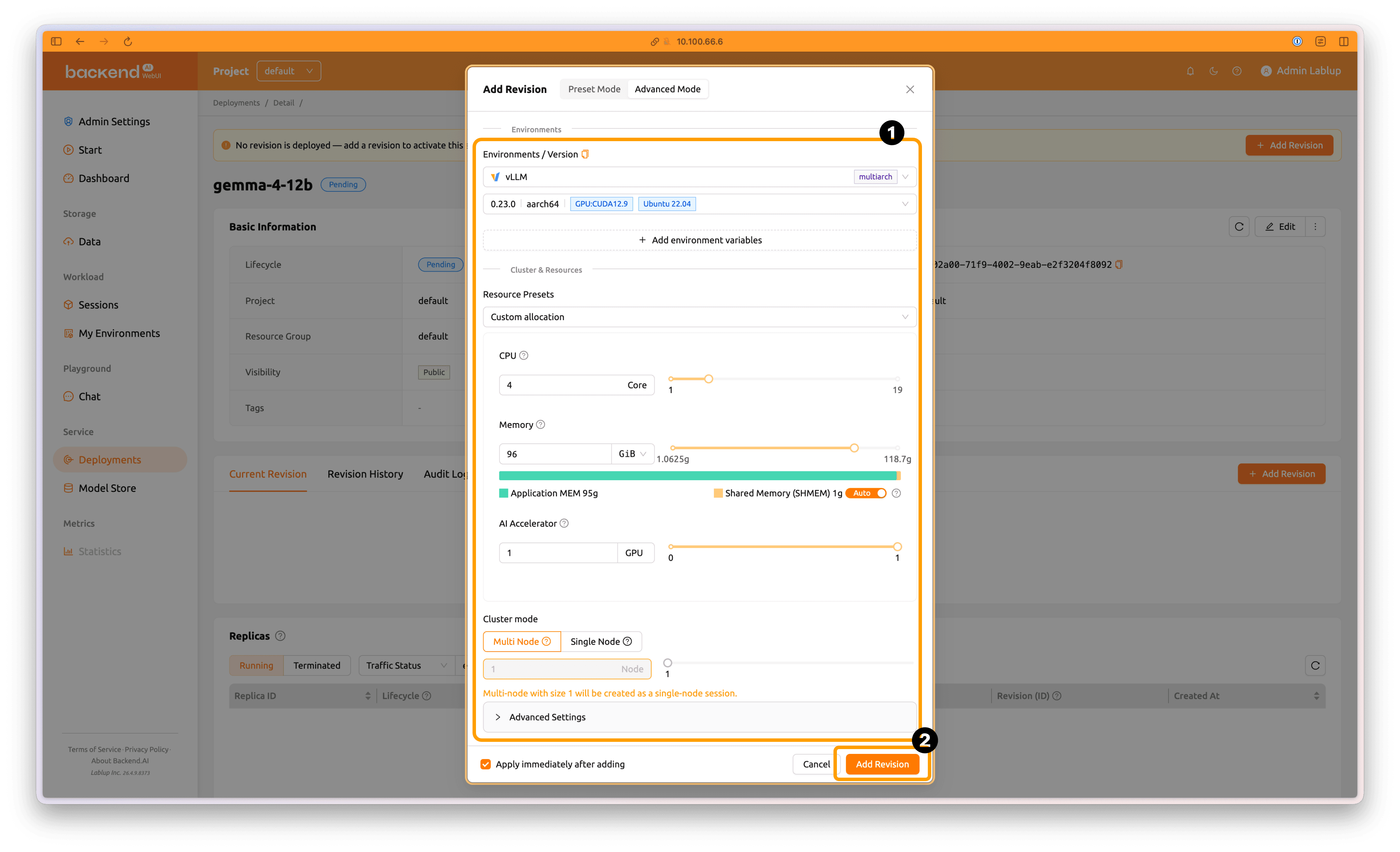
아래와 같이 자원 요구량을 설정합니다.
- Environments / Versions:
vLLM, 0.23.0 | aarch64 | CUDA 12.9 | Ubuntu 22.04 - Resource Group:
default - Resource Preset:
Custom allocation - GPU:
4Core - Memory:
96GiB - AI Accelerator:
1GPU - Cluster mode:
Multi-node/1Node
이후 'Add Revision' 버튼을 클릭해 새로운 Revision을 생성합니다.
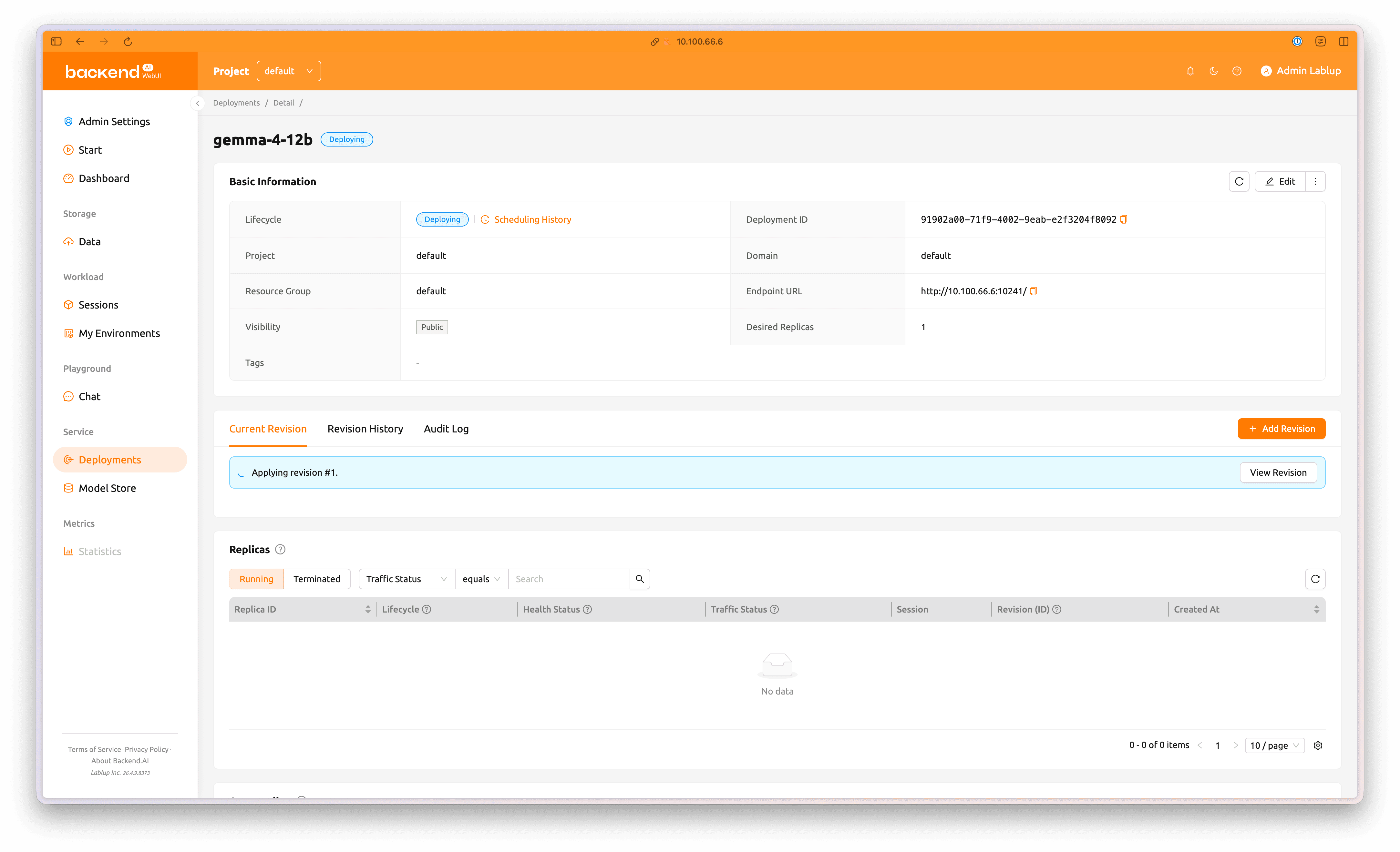
이제 새로운 Revision이 Deployment에 배포됩니다.
5.2 Deployment 상태 확인
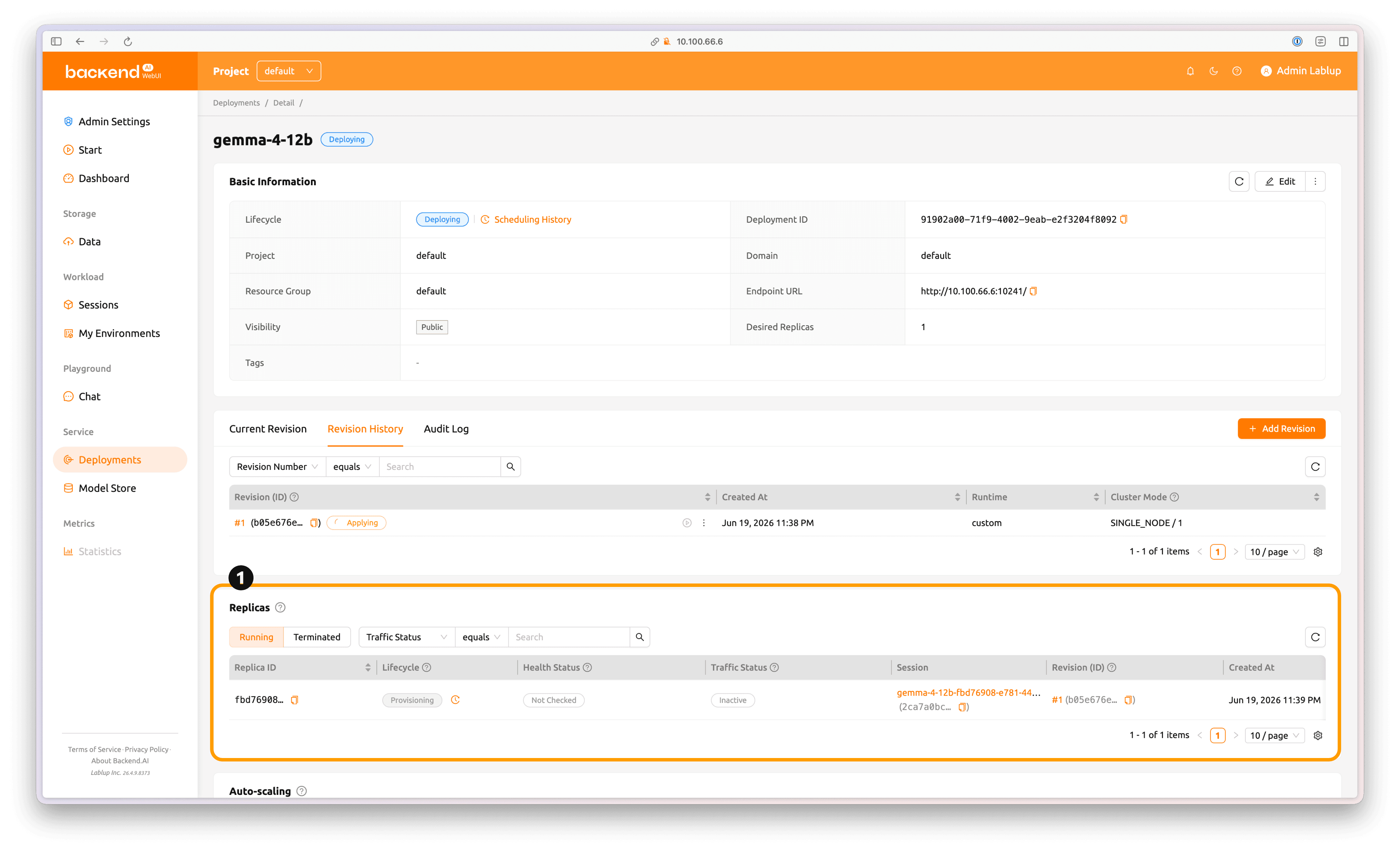
배포 상태는 'Replicas' 섹션에서 확인할 수 있습니다.
개별 배포 컨테이너의 상태는 'Replicas' 섹션의 'Session' 탭에서 주황색으로 하이라이트된 세션 이름을 눌러 확인할 수 있습니다.
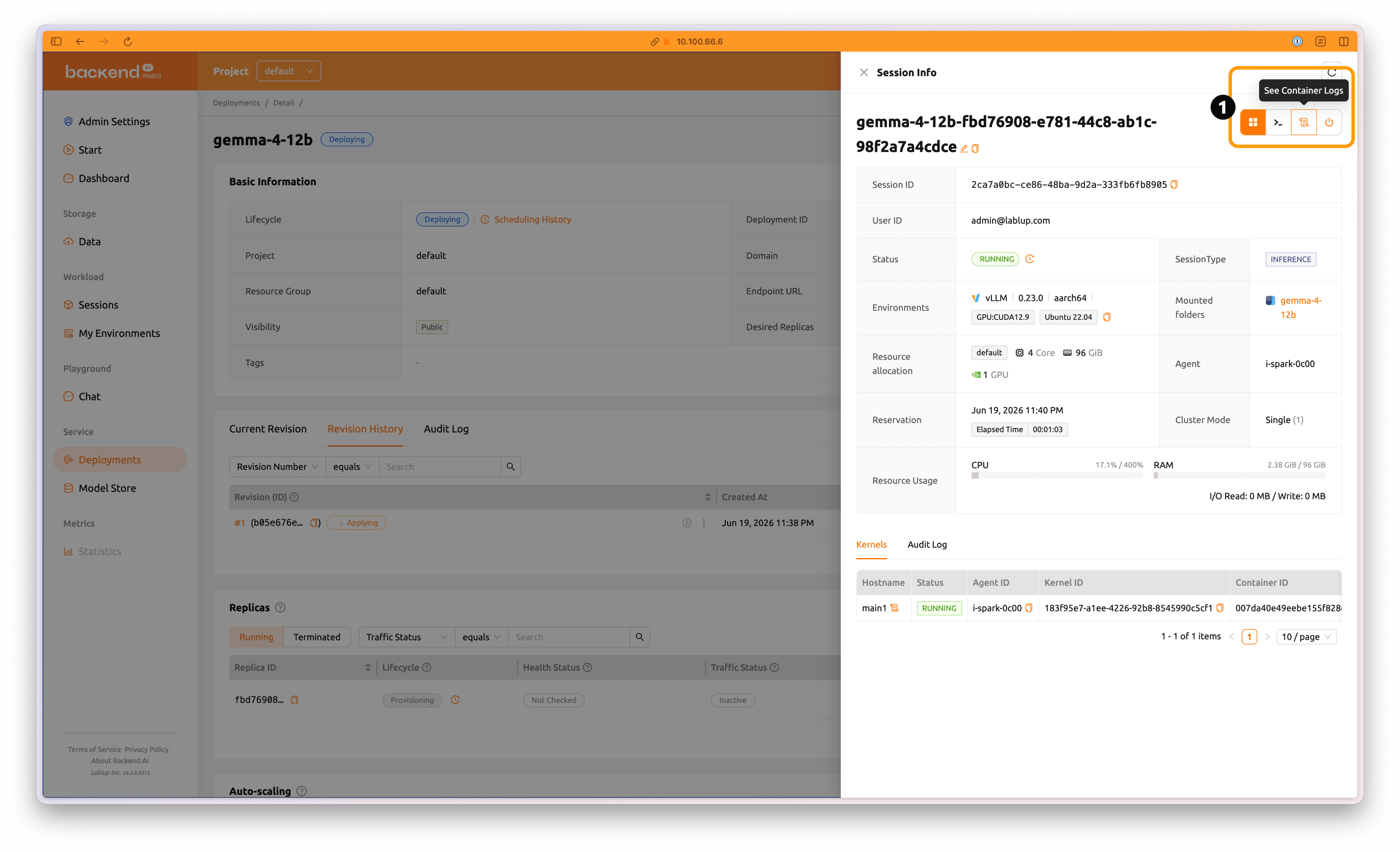
'See Container Logs' 버튼을 클릭해 모델 서비스 컨테이너의 진행 상황을 확인할 수 있습니다.
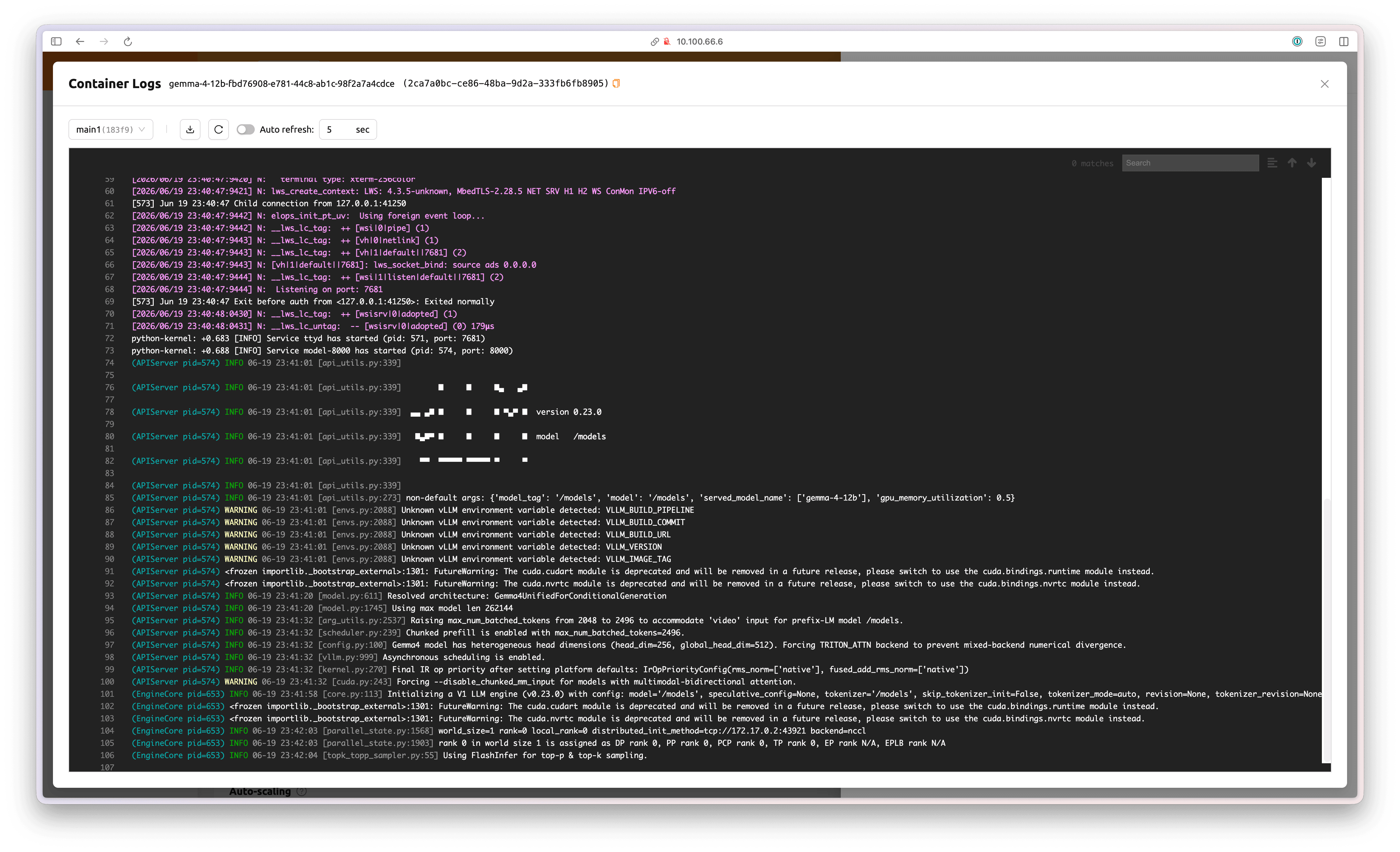
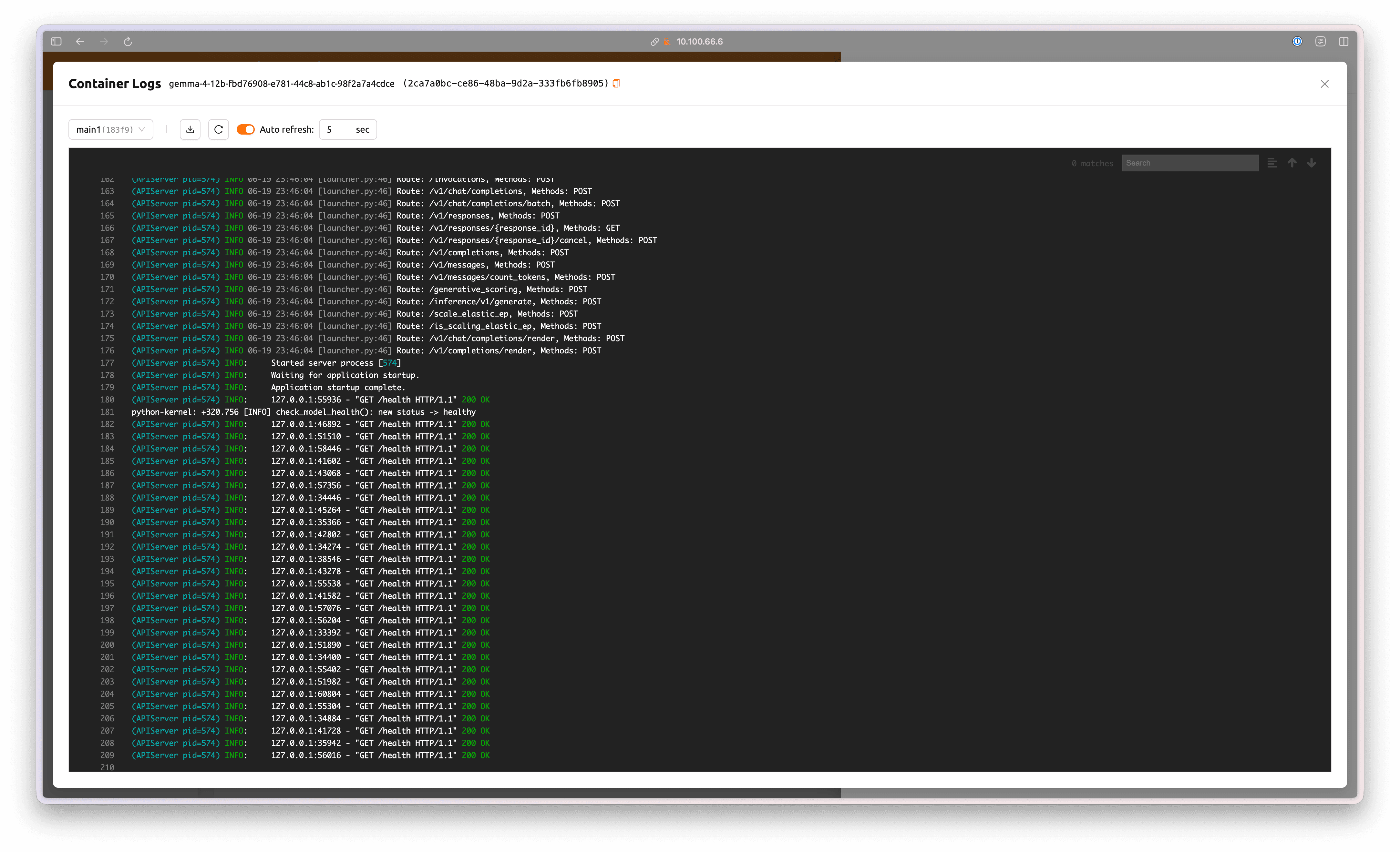
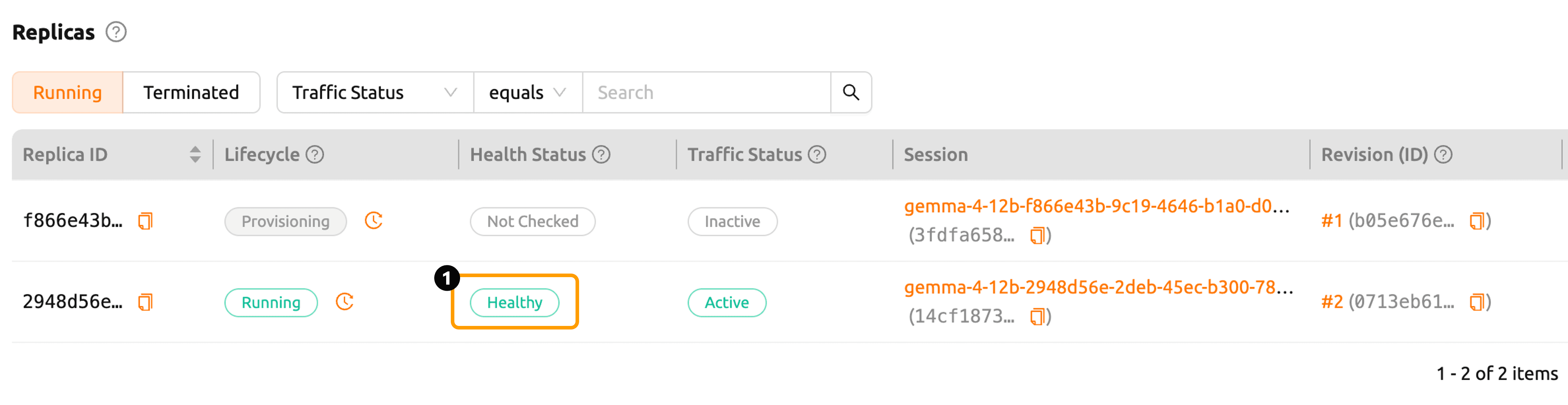
vLLM이 실행되고, Health Check가 성공적으로 수행되면 Health Status가 'Healthy' 로 변경됩니다.
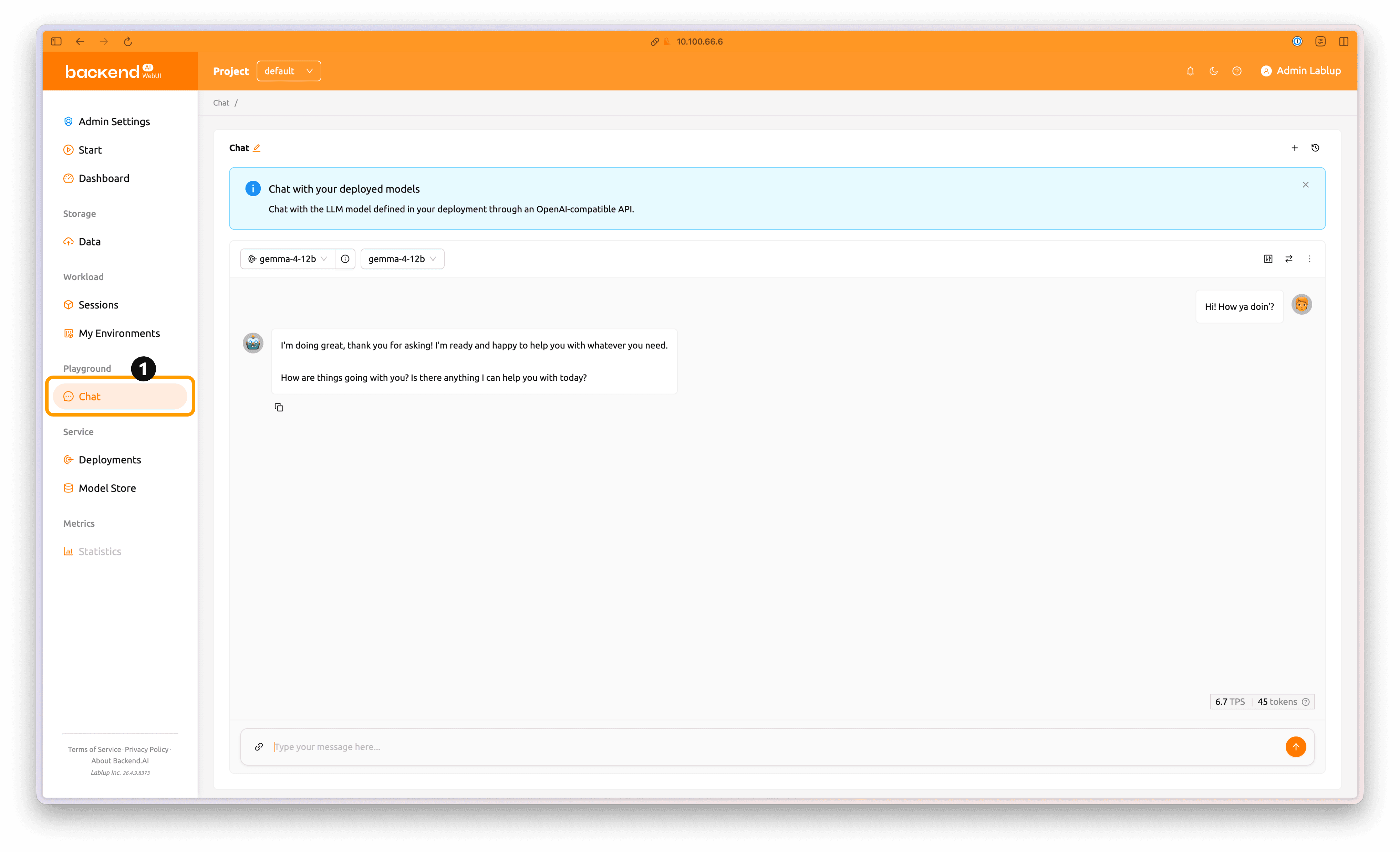
모델 서비스 배포가 완료되면 좌측의 'Chat' 탭을 클릭하여 배포된 모델에 추론 요청을 보낼 수 있습니다.
6. Troubleshooting
6.1 Agent에서 경고 발생
gather_node_measures(): LibraryError('NVML', 'nvmlDeviceGetMemoryInfo', 3)
해당 오류는 Backend.AI Open Source 버전의 CUDA 플러그인이 DGX Spark를 정식 지원하지 않아 발생하는 경고로, Backend.AI에서의 CUDA 사용에는 지장이 없습니다. 추후 버전에서 수정 예정입니다.
해당 가이드는 Backend.AI 26.4.9 버전을 기준으로 하며, 향후 소프트웨어 업데이트로 인터페이스가 일부 변경될 수 있습니다.



