2026년 6월 12일
엔지니어링
Intel Arc와 Backend.AI의 만남: Arc Pro B70의 32GB 메모리가 에이전트형 AI에 제공하는 이점

허진호
테크니컬 라이터

조규진
AI 플랫폼 아키텍트

Gilliean Lee
AI Solutions Architect
2026년 6월 12일
엔지니어링
Intel Arc와 Backend.AI의 만남: Arc Pro B70의 32GB 메모리가 에이전트형 AI에 제공하는 이점
허진호
테크니컬 라이터
조규진
AI 플랫폼 아키텍트
Gilliean Lee
AI Solutions Architect
Backend.AI는 기존에 지원하던 Intel Gaudi 2/3 AI 가속기에 이어, Intel Arc 그래픽 라인업으로 지원 범위를 확장합니다. 그 첫 번째 제품은 Arc Pro B70입니다. B70은 동급 데스크톱 카드 대비 더 큰 메모리 용량을 갖추고 있으며, 단일 사용자 최대 성능보다 지속적인 처리량과 메모리 용량이 중요한 에이전틱 AI 워크로드에서 특히 강점을 발휘합니다.
LLM 서빙에서 카드의 실질적인 유용성을 결정하는 핵심 스펙은 메모리가 되었고, 가장 중요한 이유 중에 하나가 바로 KV 캐시입니다. KV 캐시는 추론 엔진이 이전 연산 결과를 재활용하기 위해 보관하는 데이터로, 컨텍스트 길이와 동시 요청 수가 늘어날수록 함께 증가합니다. 컨텍스트 길이와 동시 요청 수는 에이전틱 워크플로우의 핵심으로, 코딩 에이전트는 긴 기본 컨텍스트를 유지하면서 여러 턴에 걸쳐 이를 반복적으로 참조하고, 실제 서비스 환경에서는 다양한 사용자들에게서 이러한 에이전트 수십 개가 동시에 실행됩니다. KV 캐시를 위한 메모리가 부족해지면 엔진은 캐시를 축출하고 재연산을 시작하며, 이 순간 처리량이 급격히 떨어지는 결과로 이어집니다. 이에 대한 해결책은 캐시를 GPU 밖으로 옮기는 KV 캐시 오프로딩 방식을 활용하거나, 처음부터 메모리 용량이 큰 카드를 사용해 해당 임계점에 더 늦게 도달하도록 하는 것입니다.
아래 벤치마크와 분석은 여러 오픈 모델을 대상으로 일반적인 데스크톱급 대안인 NVIDIA RTX PRO 4000 Blackwell과 비교하며 이를 실제로 검증했습니다. 결과적으로, 컨텍스트 길이와 동시 요청 수가 늘어날수록 B70의 우위는 더욱 뚜렷해지는데, 이는 에이전틱 워크로드가 향하는 방향과 정확히 일치합니다.
Arc Pro B70: 더욱 많은 메모리를 가진 워크스테이션 GPU
인텔 아크 프로 B70은 인텔의 Xe2(배틀메이지) 아키텍처를 기반으로 구축된 워크스테이션 GPU로, AI 추론 및 전문 시각화를 위해 2026년 3월에 출시되었습니다.
 | ||||||||||||||||||||
|
추론 성능에서 인상적인 수치는 32GB GDDR6 메모리와 608GB/s의 대역폭입니다. 앞서 언급했듯, 메모리는 LLM 서빙 스택에서 가장 먼저 바닥나는 자원 중 하나입니다. 모델 가중치 로드 후 남은 메모리가 KV 캐시를 수용하는 구조이므로, 32GB 카드는 메모리가 부족해지기 전까지 훨씬 더 긴 컨텍스트와 더 많은 동시 요청을 유지할 수 있습니다. B70은 $1,099에 이 수준의 메모리를 단일 워크스테이션으로 갖출 수 있어, 로컬 및 소규모 클러스터 추론 환경에서 진지하게 검토할 만한 옵션입니다. 아래 벤치마크는 대부분의 데스크톱 및 워크스테이션 환경에서 사용하는 방식과 동일하게, 카드 한 장(텐서 병렬화 1, TP = 1)으로 실행했습니다.
B70의 성능을 최대로 발휘하다
메모리 여유가 충분한 워크스테이션 카드는 로컬 환경에서 실행 가능한 워크로드의 범위를 확장합니다. 사용자는 긴 컨텍스트 윈도우가 필요한 에이전트를 프로토타이핑하기 위해 데이터센터를 빌릴 필요 없이 로컬에서 비용 효율적으로 실행하면서 프로덕션에서 사용할 모델 서빙 스택을 그대로 유지할 수 있습니다. B70은 단일 단문 요청의 처리 속도보다, 더 많은 작업을 더 오래 감당할 수 있는 구조로 설계되었기 때문입니다.
이 메모리 여유 공간은 에이전틱 워크플로우에서 직접적인 성능 이점으로 작용합니다. KV 캐시가 클수록 처리량이 저하되기 전까지 한 카드에서 더 많은 에이전트를 실행하고, 더 긴 컨텍스트를 처리하며, 더 높은 동시성을 확보할 수 있습니다. 각 에이전트는 코드베이스와 툴로 구성된 긴 프리픽스를 고정해두고 매 턴마다 이를 다시 참조합니다. 여러 에이전트를 동시에 실행하면 연산 능력보다 메모리가 먼저 병목이 되는데, 아래 벤치마크를 통해 그 결과를 확인해볼 수 있습니다.
벤치마크
대역폭과 연산 성능은 단일 단문 요청에서 가장 큰 효과를 발휘하고, 순수 용량은 지속적인 부하 환경에서 가장 큰 차이를 만듭니다. 맥락을 고려하여 B70의 메모리 용량을 평가하기 위해, 시장에서 널리 사용되는 데스크톱급 워크스테이션 카드인 NVIDIA RTX PRO 4000 Blackwell과의 비교 벤치마크를 진행했습니다. RTX PRO 4000 Blackwell이 소폭 앞서는 사양을 지니고 있지만, 전반적인 스펙 수준은 두 제품이 유사한 포지션에 있음을 보여줍니다. RTX PRO 4000 Blackwell은 24GB GDDR7 메모리를 탑재하며, 메모리 대역폭(672GB/s 대 608GB/s)과 FP32 연산 성능 모두 B70보다 높습니다. 다만 B70의 경우 24GB 메모리 대신 32GB 메모리를 탑재하여 메모리 스펙 이점이 있는 구성이 특징입니다.
두 카드는 동일한 노드(Intel Xeon w9-3475X, Ubuntu 25.10) 환경에서 테스트했습니다. 각 노드는 GPU 한 장을 텐서 병렬화 1(TP = 1)로 운용하며, vLLM의 bench_sweep을 사용해 입력 길이, 출력 길이, 동시 요청 수를 변화시키며 측정했습니다. 사용한 오픈 모델은 OpenAI GPT-OSS 20B, Qwen3 4B Instruct 2507, Qwen3 8B 세 가지이며, 주요 지표는 출력에 대한 처리량입니다.
1. 에이전틱 부하 상황에서 계속 성능을 유지하는 B70
에이전틱 워크로드는 긴 컨텍스트와 높은 동시 요청 수를 함께 요구합니다. 첫 번째 테스트는 Qwen3 8B를 8,192토큰 입력으로 고정한 상태에서 동시 요청 수를 1에서 16으로, 점진적 증가시키는 방향으로 측정했습니다.
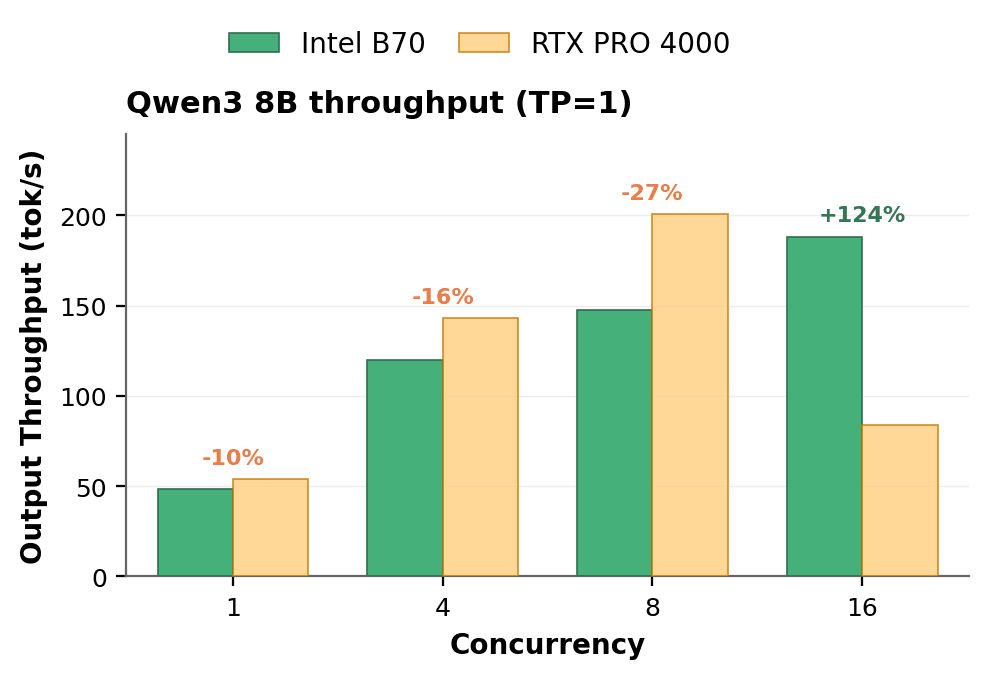
B70은 부하가 늘어날수록 처리량이 꾸준히 증가하는 결과를 보입니다. 단일 요청에서 48.5 tok/s, 동시 요청 8개에서 147.4 tok/s, 16개에서 188.2 tok/s로 상승세를 유지했습니다. RTX PRO 4000 Blackwell은 초반에 더 빠른 모습을 보이며 동시 요청 8개 구간까지 앞섰습니다. 그러나 16개 구간에서 모든 요청을 동시에 수용할 메모리가 부족해지면서 처리량이 83.9 tok/s로 떨어졌습니다. 이 시점부터 카드는 새로운 작업을 처리하는 대신 기존 작업을 축출하고 재연산하는 데 시간을 소비하기 때문입니다. B70은 16개 세션을 모두 수용할 여유가 있어 서빙을 중단 없이 이어갔고, 높은 부하 구간에서 RTX PRO 4000 Blackwell 대비 2.24배 높은 처리량을 기록했습니다.1
컨텍스트가 길어질수록 더욱 빠른 지점에서 B70의 우위 구간이 확인됩니다. 32K 토큰 입력 환경에서는 동시 요청 4개 구간부터 처리량 우위를 유지했는데, 이 시점에서 RTX PRO 4000 Blackwell은 이 크기의 컨텍스트를 제대로 수용하지 못했습니다. 이 구간에서 B70은 3.6배에서 4.4배 높은 처리량을 기록했습니다.2 에이전틱 AI가 요구하는 방향을 고려했을 때, B70이 가진 메모리 우위는 워크로드 운영에서 확실한 이점으로 작용합니다.
2. 20B 모델에서도 계속 성능 우위를 유지하는 B70
모델이 클수록 요청이 들어오기 전부터 GPU 메모리를 더 많이 차지하기 때문에, 실제 처리에 사용할 수 있는 메모리는 줄어들게 됩니다. GPT-OSS 20B 모델로 진행한 이번 테스트는 부하 상황에서 카드가 생산성을 보장할 수 있는지 확인하는 더욱 까다로운 테스트입니다. 이 모델을 2,048토큰 입력과 2,048토큰 출력 조건으로 전체 동시 요청 범위에 걸쳐 실행했습니다.
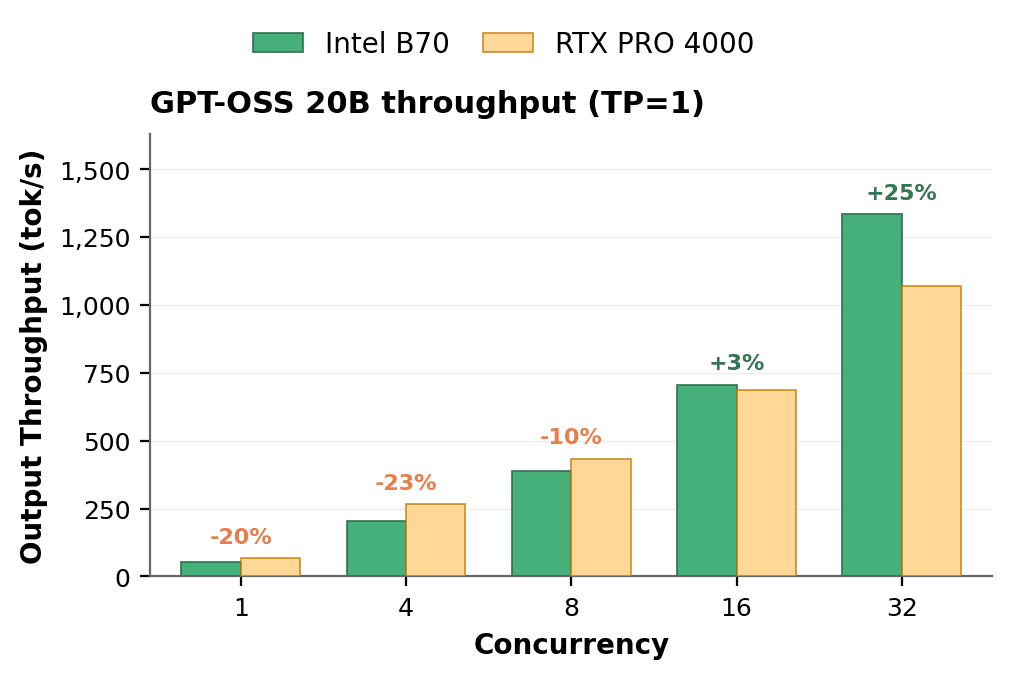
GPT-OSS 20B 모델에서도 B70의 처리량은 동시 요청 수가 늘어날수록 꾸준히 상승했습니다. 단일 요청에서 54.8 tok/s, 16개에서 706.9 tok/s, 32개에서 1,334.4 tok/s를 기록하며 요청이 추가될수록 처리량이 계속 늘어나는 결과를 보입니다. RTX PRO 4000 Blackwell은 첫 번째 테스트와 같은 양상으로, 가벼운 부하에서는 더 빠르지만 동시 요청 수가 증가할수록 처리량 증가폭이 줄어드는 경향을 보입니다.
두 카드는 동시 요청 16개 구간에서 거의 동일한 수준을 보였고(706.9 대 686.0 tok/s), 32개 구간에서는 B70이 1.25배 앞섰습니다(1,334.4 대 1,071.6 tok/s).3 이 크기의 모델에서는 실행 중인 요청에 할당할 수 있는 여유 메모리가 줄어드는데, B70은 더 큰 메모리 풀 덕분에 RTX PRO 4000 Blackwell의 처리량이 정체되는 구간에서도 처리량 증가를 유지했습니다. 이러한 결과는 다양한 벤치마크 상황에서도 공통적으로 나타났고, 에이전틱 AI 워크로드의 지속성과 메모리 용량 사이의 중요한 상관관계를 보여줍니다.
3. 약 2.1배 더 큰 KV 캐시 용량: B70이 성능 우위를 유지하는 근본적인 이유
두 구간의 성능 역전은 모두 동일한 원인에서 비롯되는데, 바로 KV 캐시의 크기입니다. 모델 가중치를 로드한 후 각 카드가 수용할 수 있는 KV 캐시의 크기는 스펙에 따라 달라지는데, 모델별로 각 카드가 유지할 수 있는 최대 동시 토큰 수를 측정한 결과는 다음과 같습니다.
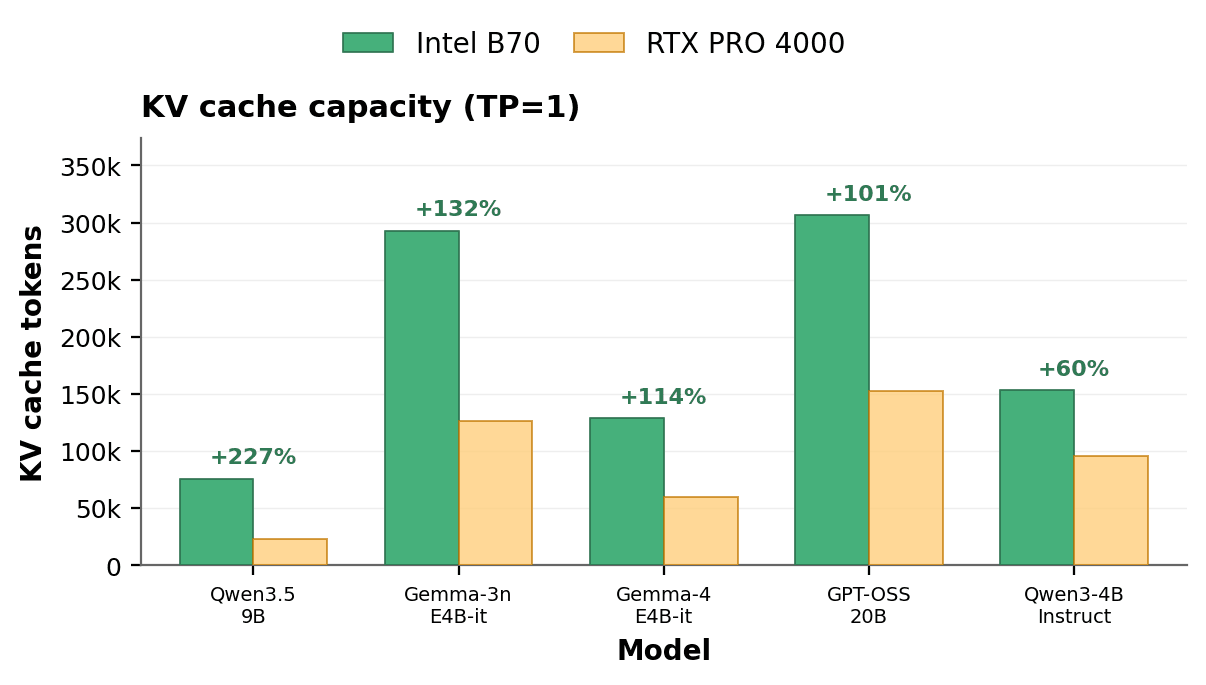
이 비교는 GPT-OSS 20B와 Qwen3 8B에 집중한 위의 처리량 테스트보다 더 넓은 모델 세트를 대상으로 합니다.
전체 모델 세트 평균을 기준으로, B70은 RTX PRO 4000 Blackwell 대비 약 2.1배 더 많은 KV 캐시를 수용했습니다(약 191,000 vs 92,000 토큰). 4 이 격차는 32GB 대 24GB의 단순 용량 비율인 1.33배를 상회합니다. 모델 가중치가 각 카드의 메모리를 먼저 일정량 차지하기 때문에, B70의 더 큰 잔여 메모리는 비례 이상의 이점을 만들어냅니다.5 이러한 우위는 메모리 효율이 높은 최신 모델 아키텍처에서 더욱 두드러지게 나타납니다. 캐시가 부족해지면 축출과 재연산이 발생하며 처리량이 급격히 저하되는데, B70은 더 큰 메모리 용량으로 인해 이 임계점에 더 늦게 도달합니다.
토큰당 비용 계산
장비와 솔루션 도입 시 토큰 처리 비용은 주요 검토 항목 중 하나입니다. 이 비용은 처리량과 카드 가격, 두 가지 요소에 의해 결정됩니다. 정가 기준으로 B70은 $1,099, RTX PRO 4000 Blackwell은 $2,199로, 처리량을 고려하기 전부터 B70이 낮은 도입 비용을 가집니다. 벤치마크 결과를 반영하면 두 제품 간 비용 효율 격차는 더욱 커집니다.
에이전틱 환경에서는 처리량과 가격, 두 요소가 동시에 비용 효율에 영향을 줍니다. 달러당 토큰 수는 출력 처리량을 카드 가격으로 나눈 값이며, B70의 달러당 토큰 우위는 처리량 비율에 가격 비율 2배(RTX PRO 4000 Blackwell $2,199 대 B70 $1,099)를 적용한 값입니다.
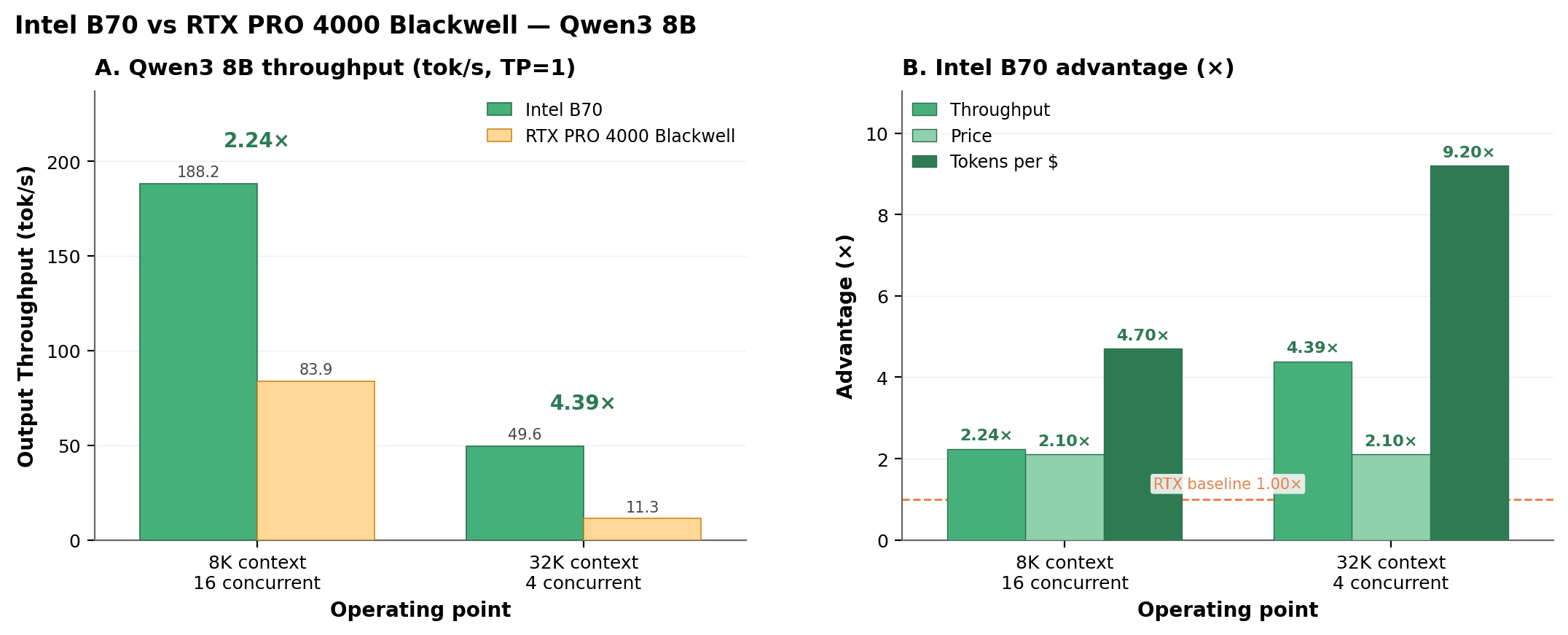
| Operating Point | Output Throughput B70 vs RTX PRO 4000 Blackwell | Price Advantage | Tokens per Dollar |
|---|---|---|---|
| Qwen3 8B, 8K context, 16 concurrent | 2.24x188.2 vs 83.9 tok/s | 2.0x | 4.48x |
| Qwen3 8B, 32K context, 4 concurrent | 4.39x49.6 vs 11.3 tok/s | 2.0x | 8.78x |
낮은 동시 요청 수 구간에서는 처리량이 10~20% 낮지만, 낮은 가격으로 인해 달러당 토큰 수는 소폭 높게 유지됩니다(처리량 비율 0.90x 기준으로도 달러당 토큰 수는 1.9배). 달러당 출력 기준으로 B70은 전체 범위에서 경쟁력을 유지하며, 에이전트가 실제로 실행되는 구간에서는 격차가 더욱 뚜렷하게 나타납니다.
전력 소비 측면에서는 다른 양상이 나타납니다. B70은 230W, RTX PRO 4000 Blackwell은 140W를 소비하므로, 단일 사용자 및 낮은 동시 요청 수 환경에서는 RTX PRO 4000 Blackwell의 에너지 효율이 더 높습니다. 그러나 이 이점은 B70의 설계 목표에 해당하지 않는 환경에서만 유효합니다. 동시 사용자가 증가하면 B70의 처리량 우위가 높은 전력 소비를 상쇄하여, 와트당 토큰 수에서도 RTX PRO 4000 Blackwell을 앞섭니다. 결과적으로 도입 비용은 모든 구간에서 B70이 유리하며, 에이전트가 실행되는 다중 사용자 부하 환경에서는 운영 비용에서도 B70이 우위를 가집니다.
데스크톱에서 데이터센터까지, 하나의 플랫폼으로
B70은 워크스테이션 카드 한 장으로 긴 컨텍스트 에이전트를 실행하고 여러 에이전트를 동시에 서빙하는 데스크톱 규모의 에이전틱 AI 환경에 적합합니다. 그러나 팀마다 운영 규모는 다르고, 모든 팀이 같은 방향으로 확장하는 것도 아닙니다. 카드 한 장으로 모든 것을 처리하는 팀도 있고, 몇 개의 노드를 묶어 팀 공유 추론 클러스터를 구성하는 팀도 있으며, 동일한 워크로드를 데이터센터 규모로 운영하는 팀도 있습니다. Backend.AI는 단일 컨트롤 플레인과 단일 모델 서빙 스택으로 이 세 가지 환경 모두를 지원하기 때문에, 배포 규모와 관계없이 동일한 플랫폼을 유지할 수 있습니다. 여러 환경에 걸쳐 운영하는 팀에게 이 일관성은 파이프라인을 재구성하지 않고도 환경 간 이동을 가능하게 하는 기반입니다. Intel XPU를 Backend.AI의 공식 지원 목록에 추가함으로써, 그 범위는 워크스테이션 카드 수준까지 확장됩니다.
연산 성능보다 메모리가 먼저 병목이 되는 에이전틱 AI 환경에서 B70은 데스크톱 영역에서의 선택지를 넓히고, Backend.AI는 전체 범위에 걸친 일관된 관리 환경을 제공합니다. 데스크톱에 꽂힌 한 대의 B70부터 여러대의 B70을 사용하는 공유 클러스터, 데이터센터에 있는 Gaudi까지 이제 하드웨어는 더이상 제약이 아닌 선택의 영역이 됩니다. 사용자의 환경에 맞는 Intel의 그래픽 카드와 AI 가속기를 선택하고, Backend.AI를 통해 스택의 변경 없이 손쉽게 환경을 확장, 모델과 에이전트 서빙에 활용해보세요.
Backend.AI는 Intel XPU를 포함하여 엣지 디바이스부터 데이터센터 클러스터까지, 모든 가속기 환경에서 AI 워크로드를 실행합니다. B70 또는 보유 중인 하드웨어 환경에서 Backend.AI를 사용하려면 contact@lablup.com으로 문의하거나 backend.ai를 방문하세요.
*해당 포스트의 PDF 버전은 다음 링크에서 다운로드받으실 수 있습니다.
벤치마크 조건
- 카드: Intel Arc Pro B70 (32 GB GDDR6) vs NVIDIA RTX PRO 4000 Blackwell (24 GB GDDR7 ECC).
- 노드: Intel Xeon w9-3475X, Ubuntu 25.10. B70 node 96 GB RAM; RTX PRO 4000 Blackwell node 256 GB RAM. Single GPU per run, tensor parallelism of 1.
- 도구: vLLM
bench sweep, request rateinf(all prompts submitted simultaneously; concurrency equals prompt count). - 모델: GPT-OSS 20B, Qwen3 4B Instruct 2507, Qwen3 8B. KV cache comparison also covers Gemma-4-E4B-it, Qwen3.5-9B, Gemma-3n-E4B-it.
- 메트릭: output throughput (tokens/s); per-user throughput is output throughput divided by concurrency.
- 벤치마크 데이터: 인텔 & 래블업, 2026년 4월.
추가 고지사항
- 권장 소비자 가격(MSRP)은 2026년 6월 9일 기준 Newegg 소매점 목록(https://www.newegg.com/intel-arc-pro-b70-32gb-graphics-card/p/N82E16814883008)을 기준으로 합니다. 실제 판매 가격은 현지 관세, 세금 및 기타 요인을 포함한 다양한 요소에 따라 변동될 수 있습니다. 인텔의 권장 가격은 인텔의 공식 가격 제안을 의미하지 않습니다. 제품 가용성은 국가 및 판매점에 따라 다를 수 있습니다. 구매 전, 해당 판매점에 재고 여부 및 최종 가격 정보를 확인하시기 바랍니다.
Footnotes
-
Qwen3 8B LLM(https://huggingface.co/Qwen/Qwen3-8B) 실행 중 토큰 처리량 측정을 기반으로 한 벤치마크 테스트입니다. Intel 결과는 Intel Xeon w9-3475X, Intel Arc Pro B70 GPU, 96GB RAM, Ubuntu 25.10 환경 기준이며, NVIDIA 결과는 Intel Xeon w9-3475X, NVIDIA RTX PRO 4000 GPU, 256GB RAM, Ubuntu 25.10 환경 기준입니다. 측정일: 2026년 4월 14일 ↩
-
Qwen3 8B LLM(https://huggingface.co/Qwen/Qwen3-8B) 실행 중 토큰 처리량 측정을 기반으로 한 벤치마크 테스트입니다. Intel 결과는 Intel Xeon w9-3475X, Intel Arc Pro B70 GPU, 96GB RAM, Ubuntu 25.10 환경 기준이며, NVIDIA 결과는 Intel Xeon w9-3475X, NVIDIA RTX PRO 4000 GPU, 256GB RAM, Ubuntu 25.10 환경 기준입니다. 측정일: 2026년 4월 14일 ↩
-
GPT-OSS 20B LLM(https://huggingface.co/openai/gpt-oss-20b) 실행 중 토큰 처리량 측정을 기반으로 한 벤치마크 테스트입니다. Intel 결과는 Intel Xeon w9-3475X, Intel Arc Pro B70 GPU, 96GB RAM, Ubuntu 25.10 환경 기준이며, NVIDIA 결과는 Intel Xeon w9-3475X, NVIDIA RTX PRO 4000 GPU, 256GB RAM, Ubuntu 25.10 환경 기준입니다. 측정일: 2026년 4월 11일 ↩
-
Gemma-4-E4B-it(https://huggingface.co/google/gemma-4-E4B-it), Gemma-3n-E4B-it(https://huggingface.co/google/gemma-3n-E4B-it), GPT-OSS 20B(https://huggingface.co/openai/gpt-oss-20b), Qwen3 4B Instruct 2507(https://huggingface.co/Qwen/Qwen3-4B-Instruct-2507), Qwen3 8B(https://huggingface.co/Qwen/Qwen3-8B), Qwen3.5-9B(https://huggingface.co/Qwen/Qwen3.5-9B) 등 여러 LLM의 KV 캐시 용량 측정을 기반으로 한 벤치마크 테스트입니다. Intel 결과는 Intel Xeon w9-3475X, Intel Arc Pro B70 GPU, 96GB RAM, Ubuntu 25.10 환경 기준이며, NVIDIA 결과는 Intel Xeon w9-3475X, NVIDIA RTX PRO 4000 GPU, 256GB RAM, Ubuntu 25.10 환경 기준입니다. 측정일: 2026년 4월 14일 ↩
-
Gemma-4-E4B-it(https://huggingface.co/google/gemma-4-E4B-it), Gemma-3n-E4B-it(https://huggingface.co/google/gemma-3n-E4B-it), GPT-OSS 20B(https://huggingface.co/openai/gpt-oss-20b), Qwen3 4B Instruct 2507(https://huggingface.co/Qwen/Qwen3-4B-Instruct-2507), Qwen3 8B(https://huggingface.co/Qwen/Qwen3-8B), Qwen3.5-9B(https://huggingface.co/Qwen/Qwen3.5-9B) 등 여러 LLM의 KV 캐시 용량 측정을 기반으로 한 벤치마크 테스트입니다. Intel 결과는 Intel Xeon w9-3475X, Intel Arc Pro B70 GPU, 96GB RAM, Ubuntu 25.10 환경 기준이며, NVIDIA 결과는 Intel Xeon w9-3475X, NVIDIA RTX PRO 4000 GPU, 256GB RAM, Ubuntu 25.10 환경 기준입니다. 측정일: 2026년 4월 14일 ↩